Loading TFHub Models
Overview
In the realm of deep learning, TensorFlow load model function plays a pivotal role in harnessing the potential of pre-trained models. TensorFlow Hub (TFHub) has emerged as a valuable resource for accessing and utilizing pre-trained models.
We will uncover the steps involved in leveraging TFHub models for inference, delve into fine-tuning and transfer learning technique. Furthermore, we will discuss caching and performance optimization strategies.
Introduction
TensorFlow load model function enables loading pre-trained models from disk. It restores the model architecture, weights, and configuration, allowing for inference or further training. By providing the path to the saved model, it returns an instance of tf.keras.Model class. This facilitates easy integration of pre-trained models into TensorFlow workflows, aiding tasks like prediction, classification, or feature extraction.
What is TensorFlow Hub?
TensorFlow Hub is a repository and platform that allows users to discover, share, and reuse pre-trained machine learning models. It serves as a** centralized hub for models, embeddings**, and other resources that can be used in TensorFlow projects.
![]()
Here are the key points about TensorFlow Hub:
- Model Repository:
TensorFlow Hub provides a vast collection of pre-trained tensorflow load models across various domains, including computer vision, natural language processing, audio processing, and more. - Reusability:
TensorFlow Hub promotes model reusability by allowing users to download and incorporate pre-trained models into their own projects with ease. - Transfer Learning:
One of the primary use cases of TensorFlow Hub is transfer learning. Transfer learning involves taking a pre-trained model and fine-tuning it on a specific task or dataset. - Versatility:
TensorFlow Hub supports models in various formats, including TensorFlow SavedModel, Keras models, and TensorFlow.js models, making it compatible with different TensorFlow environments and frameworks.

- Community Contributions:
TensorFlow Hub encourages community contributions, allowing researchers and developers to share their own pre-trained models with the wider community. - Easy Integration:
TensorFlow Hub provides a simple API for loading and using pre-trained Tensorflow load models, making it accessible to both beginners and experienced TensorFlow users.
How to Load TFHub Models via hub.load()?
Loading TensorFlow load models using hub.load() is a straightforward process that allows you to use pre-trained TensorFlow models from TensorFlow Hub. TensorFlow Hub is a repository of pre-trained machine learning models that can be easily integrated into your own projects.
To load a TFHub model using hub.load(), follow these steps:
Step 1: Install TensorFlow and TensorFlow Hub:
Ensure you have TensorFlow and TensorFlow Hub installed on your system. You can install them using pip:
Step 2: Import the required libraries:
In your Python script or Jupyter Notebook, import the necessary libraries:
Step 3: Load the TFHub model:
Use the hub.load() function to load the tensorflow load model of your choice. You can do this by providing the URL or handle of the model from TensorFlow Hub. For example, to load the popular Universal Sentence Encoder (USE), you can use the following code:
In this example, model_url is the URL of the USE model from TensorFlow Hub. Replace it with the URL or handle of the specific model you want to use.
Step 4: Using the loaded model:
Once the tensorflow load model is loaded, you can use it to make predictions on your data. The specific usage will depend on the model you've chosen. For example, with the USE model, you can encode sentences into fixed-length dense vectors as follows:
The embeddings variable will now contain the dense vector representations of the input sentences.
Sample Output
Using TFHub Models for Inference
In the world of machine learning, building models from scratch can be a time-consuming and resource-intensive process. Luckily, TensorFlow Hub comes to the rescue by providing a treasure trove of pre-trained models that can be easily integrated into your projects. In this section, we'll explore how to use TensorFlow Hub models for efficient and accurate inference.
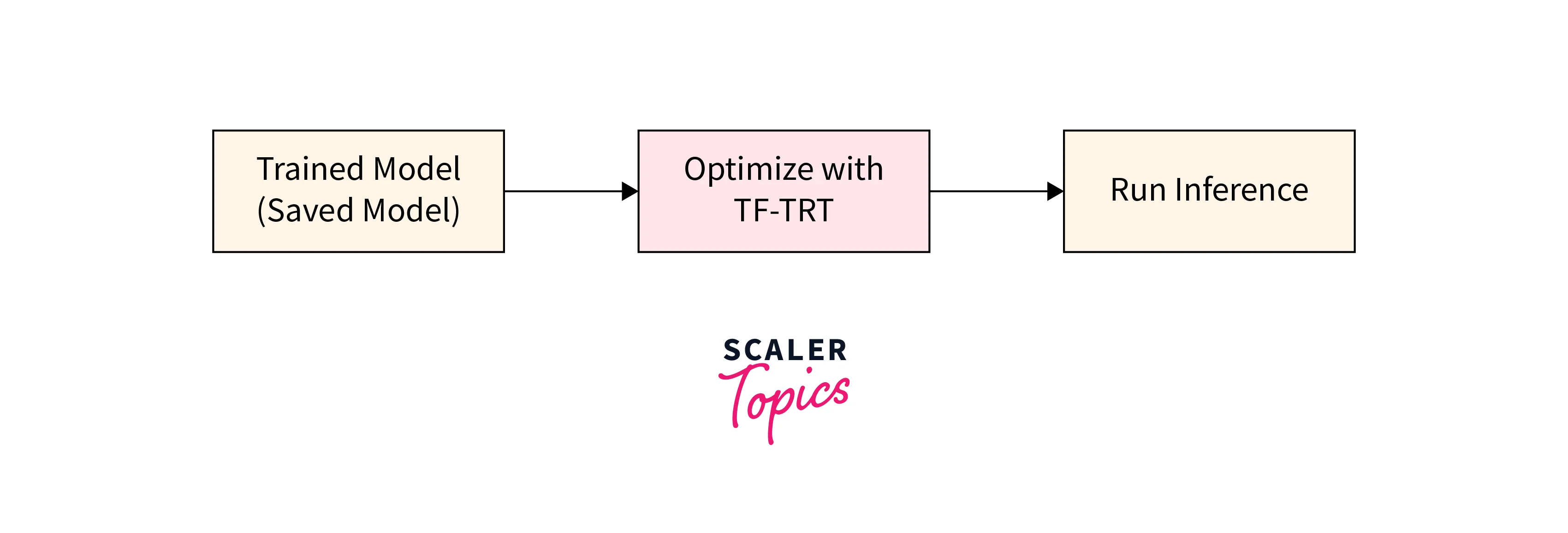
- Discovering the Model:
Start by exploring the vast collection of pre-trained models available on TensorFlow Hub. Whether you're working on computer vision, natural language processing, or audio processing tasks, you're likely to find a model that suits your needs. Browse through the repository and select the model that aligns with your project requirements. - Loading the Model:
Once you've identified the model, loading it into your TensorFlow project is a breeze. TensorFlow Hub provides a user-friendly API that simplifies the process. You can easily download the TensorFlow load model using its URL or import it directly into your code. The API abstracts away the complexities of model loading, allowing you to focus on the task at hand.
- Preprocessing Input Data:
Before feeding the data to the model, it's essential to preprocess it according to the model's requirements. TensorFlow Hub models often come with guidelines on how to preprocess the input data, such as resizing images or tokenizing text. Ensure that your input data adheres to these guidelines for optimal performance. - Making Predictions:
With the model loaded and the input data preprocessed, you're now ready to make predictions. TensorFlow Hub models provide a straightforward interface for feeding the input data and obtaining the corresponding output predictions. Whether you're classifying images, generating text, or performing other tasks, the API offers intuitive methods to obtain predictions efficiently. - Fine-tuning and Transfer Learning:
TensorFlow Hub models also serve as excellent starting points for fine-tuning and transfer learning. If you have a specific task or dataset, you can take a pre-trained Tensorflow load model and fine-tune it on your data to enhance its performance. This approach saves you significant training time and computational resources.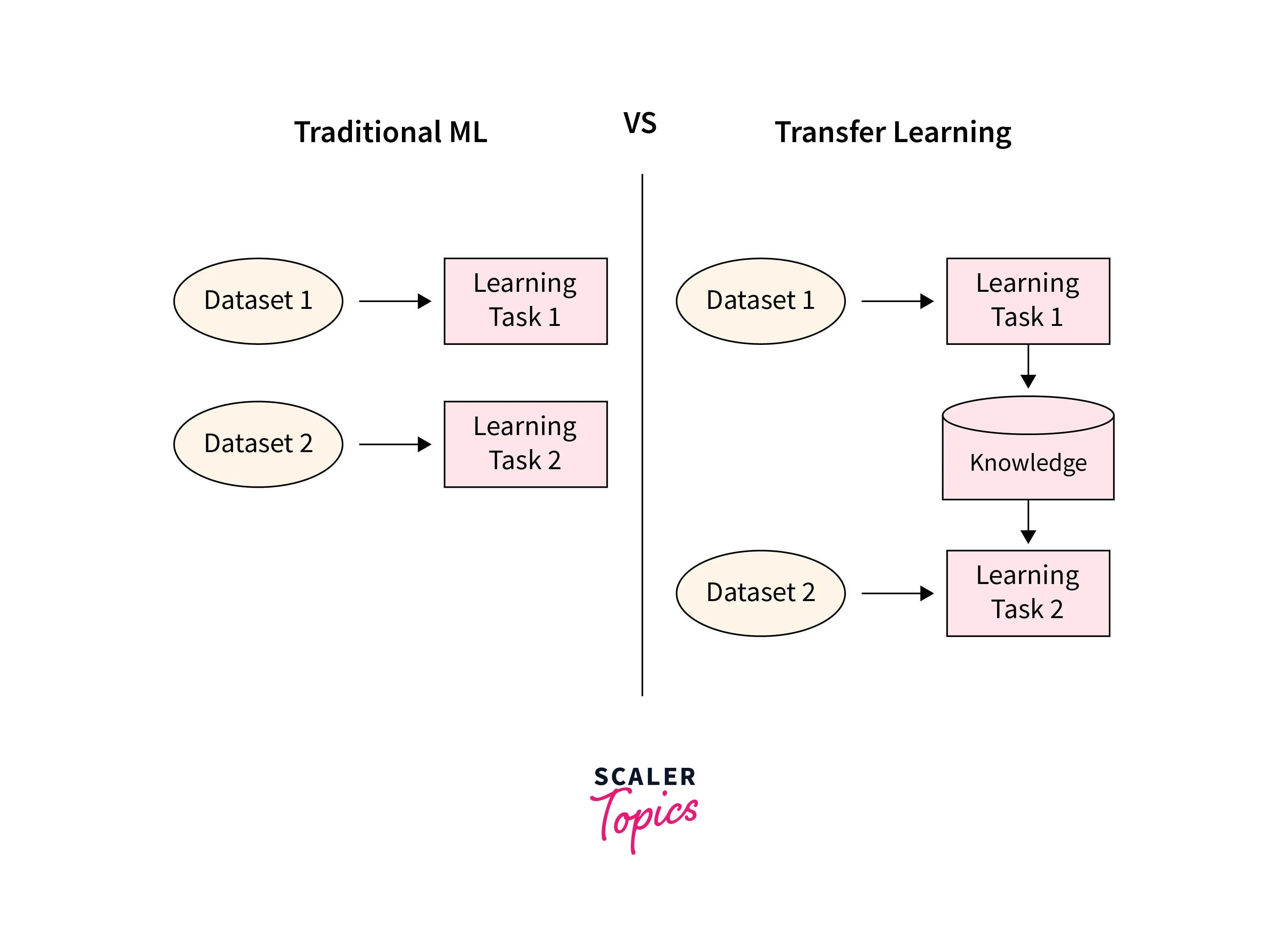
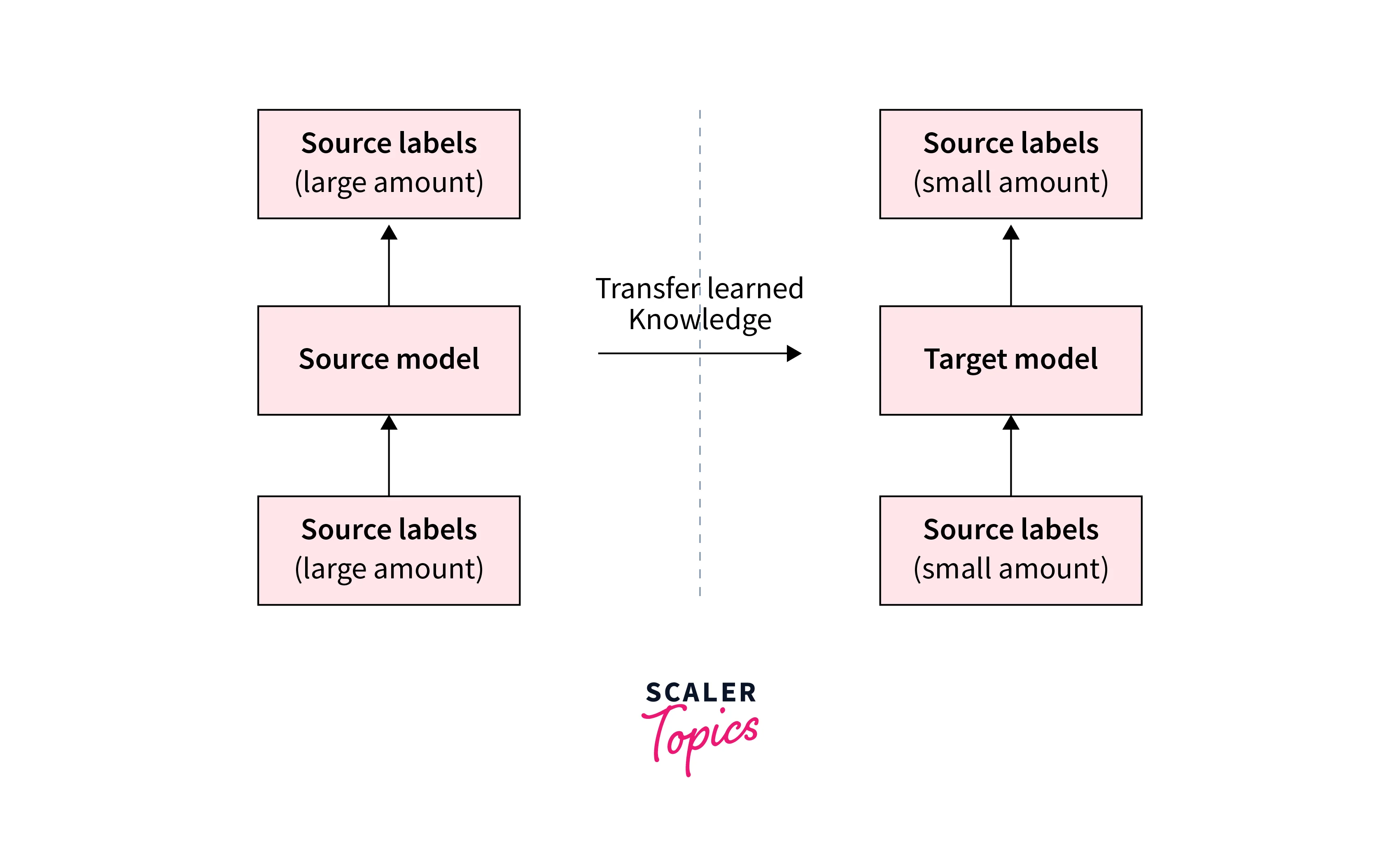
Fine-tuning and Transfer Learning with TFHub Models
Fine-tuning and transfer learning are powerful techniques that allow us to adapt and extend TensorFlow Hub (TFHub) models for specific tasks or domains. With Tensorflow load models as a starting point, we can leverage their learned knowledge and apply it to new problems without training from scratch.
Here's an overview of the concepts and steps involved:
Fine-tuning
- Fine-tuning involves taking a pre-trained TFHub model and updating its parameters to better fit a specific task or dataset.
- By keeping the initial knowledge intact and focusing on learning task-specific details, we can achieve improved performance with less training time.
- To fine-tune a TFHub model, we typically freeze the initial layers and retrain the later layers using task-specific data.
Transfer Learning
- Transfer learning is closely related to fine-tuning and involves utilizing the representations learned by a pre-trained Tensorflow load model to improve the performance of a related task.
- Rather than starting from scratch, we can initialize our custom model with the pre-trained TFHub model's weights and then adapt it to our specific task by training on our dataset.
- This approach allows us to leverage the general knowledge captured by the TFHub model, even when we have limited labeled data.
How to Incorporate a TensorFlow Load Model?
To incorporate a TensorFlow load model into our custom model and perform transfer learning, we can follow these steps:
- Load the TFHub model using the TFHub library.
- Create a new model architecture for our specific task, adding additional layers or modifying the existing ones as needed.
- Transfer the weights from the TFHub model to the corresponding layers in our custom model.
- Fine-tune the model by training it on our task-specific dataset, adjusting the model's parameters to optimize performance.
- Evaluate the performance of the transfer-learned model on a validation set to ensure it meets our desired criteria.

Example
Here's an example code snippet showcasing how to incorporate a TFHub model into a custom model and adapt it for transfer learning:
By incorporating a TFHub model into our custom model and adjusting it through transfer learning, we can take advantage of the pre-trained model's knowledge and achieve better results on our specific tasks, even with limited data.
Customizing TFHub Models
Customizing TFHub models empowers you to tailor the models to your specific requirements. By employing techniques like feature extraction or fine-tuning, modifying the architecture, and following best practices, you can effectively adapt Tensorflow load models for your own tasks and domains.
Techniques for Customizing TFHub Models to Fit Specific Requirements
Customizing TensorFlow Hub (TFHub) models is a crucial step in refactoring them to specific requirements. By applying various techniques, such as feature extraction, fine-tuning, and model stacking, we can modify Tensorflow load models to align with our unique machine learning tasks.
-
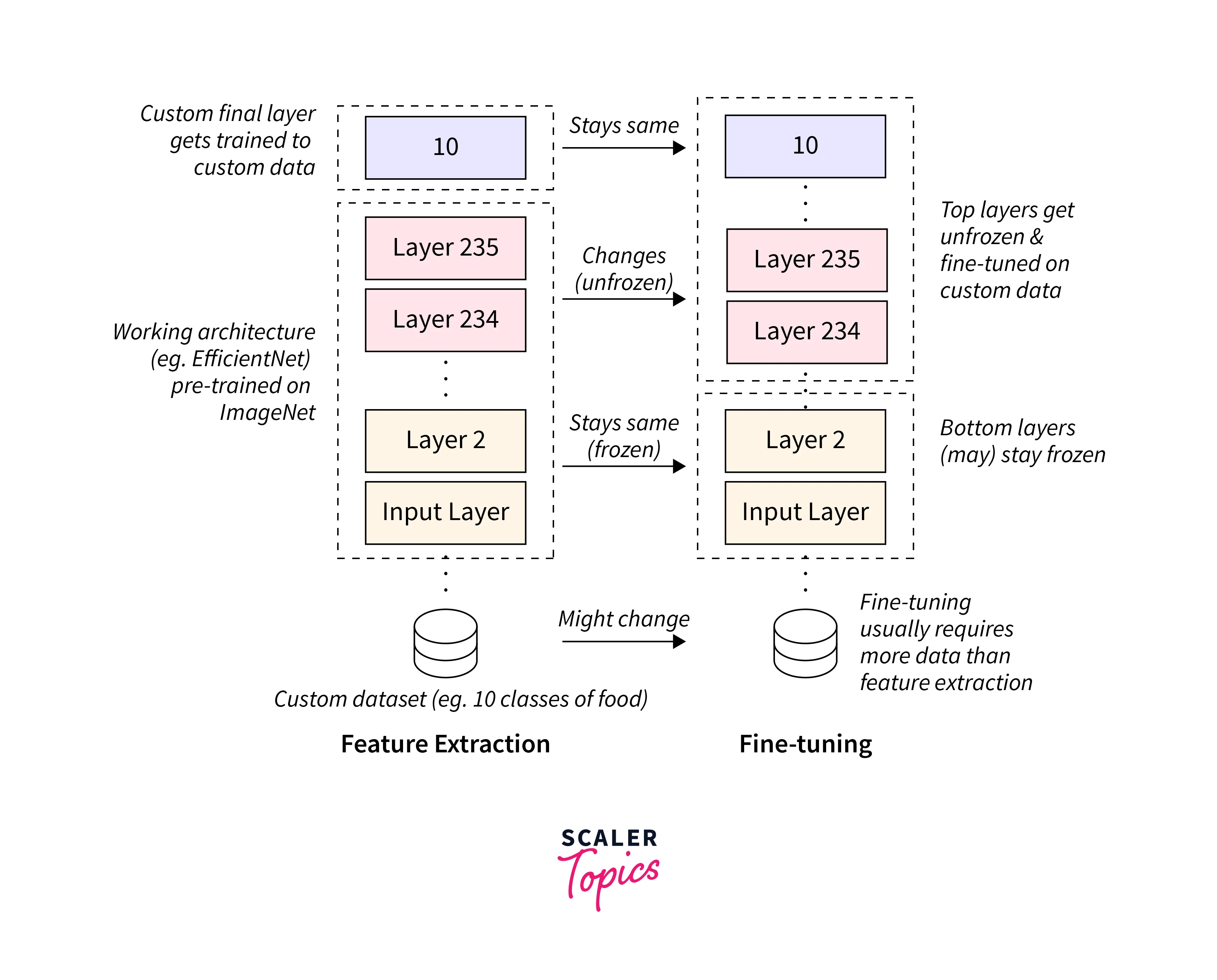
Feature Extraction:
TFHub models often serve as feature extractors, where the output of the pre-trained layers is used as input to a custom model. By removing the final classification layer of the TFHub model and adding your own layers, you can customize the output for your specific task. -
Fine-tuning:
Fine-tuning allows you to adapt a TFHub model to your task by training the entire model, including the pre-trained layers. This technique is effective when you have a substantial amount of task-specific data. You can selectively freeze certain layers to prevent them from being updated during training. -
Model Stacking:
TFHub models can be stacked with other models or layers to create more complex architectures. This allows you to combine the learned representations of the TFHub model with additional layers tailored to your specific task.
Modifying and Extending the Architecture of TFHub Models
Modifying and extending the architecture of TensorFlow Hub (TFHub) models provides flexibility in tailoring them to specific requirements. By adjusting the architecture, we can add or remove layers, change input shapes, or customize the output to match our desired task. This allows us to incorporate additional complexity, adapt the model's output for specific needs, or integrate it seamlessly with other models or layers
- Adding Layers:
You can extend the TFHub model by adding new layers on top of it. This gives you the flexibility to introduce additional complexity or adapt the model's output to match your desired output shape. - Removing Layers:
Depending on your task, you may need to remove certain layers from the TFHub model. This can be done by excluding those layers when constructing your custom model architecture. - Changing Input Shape:
Te are typically trained on specific input shapes. If your data has a different input shape, you will need to modify the TFHub model's input layer accordingly to ensure compatibility.
Considerations and Best Practices for Making Customizations to TFHub Models
When making customizations to TensorFlow Hub (TFHub) models, it's essential to consider certain factors and follow best practices. These considerations ensure that our modifications are effective and align with our specific requirements. By adhering to these practices, we can maintain model integrity, optimize performance, and streamline the customization process.
- Compatibility:
Ensure that any modifications made to the TFHub model, such as adding or removing layers, are compatible with the expected input and output shapes of the model. Mismatched shapes can lead to errors or degraded performance. - Gradual Unfreezing:
When fine-tuning a TFHub model, it is often beneficial to perform gradual unfreezing. Start by training only the newly added layers and gradually unfreeze deeper layers during subsequent training epochs. This allows the model to adapt to the new task while retaining the knowledge from the pre-trained layers. - Regularization:
Customizing TFHub models provides an opportunity to apply regularization techniques such as dropout or L2 regularization. These techniques can help prevent overfitting and improve generalization.
- Transfer Learning Evaluation:
After making customizations, it is crucial to evaluate the performance of the transfer-learned model on validation data. This allows you to assess whether the modifications have improved or maintained the model's effectiveness for your specific task.
Caching and Performance Optimization
By applying caching techniques, caching TensorFlow load models locally, and optimizing memory and computation, you can significantly enhance the performance and efficiency of working with TensorFlow load models.
The below strategies ensure faster model loading, improved resource utilization, and ultimately, better execution of your TensorFlow projects.
Caching Techniques for Optimizing TFHub Models
Caching plays a crucial role in optimizing the loading and usage of TFHub models. By caching, we can minimize the time and resources required to fetch and initialize models. Here are some caching techniques to consider:
-
Memory-based Caching:
Utilize in-memory caching mechanisms, such as dictionaries or LRU (Least Recently Used) caches, to store the loaded models in memory. This allows for faster access and avoids repeated model loading. -
Disk-based Caching:
Save the TensorFlow load models to disk in a serialized format, such as using the SavedModel format, to create a cache. When loading the model, check if it already exists in the cache before fetching it from the TFHub repository.
Caching TFHub Models Locally for Improved Performance
Caching TFHub models locally provides faster access and improves performance by eliminating the need to download the model repeatedly. Here's how to cache TensorFlow Load models:
- Download and Save Models Locally:
Download the TFHub model using its URL and save it locally in a directory. This can be done using the TensorFlow tf.saved_model.save() function or other appropriate methods. - Check Local Cache:
Before fetching the model from TFHub, check if the model is already available in the local cache. If it exists, load it from the cache. Otherwise, fetch it from TFHub and save it to the cache for future use.
Strategies for Optimizing Memory and Computation with TFHub Models
Optimizing memory and computation when working with TensorFlow load models is essential for efficient execution and resource management. Consider the following strategies:
- Memory-Efficient Data Loading:
Use efficient data loading techniques, such as TensorFlow tf.data pipelines, to avoid unnecessary memory overhead. Load and preprocess data in batches to reduce memory consumption. - GPU Memory Management:
TFHub models may require significant GPU memory. To optimize GPU memory usage, set the appropriate allow_growth or per_process_gpu_memory_fraction flags when configuring the TensorFlow session. This ensures efficient allocation of GPU memory resources.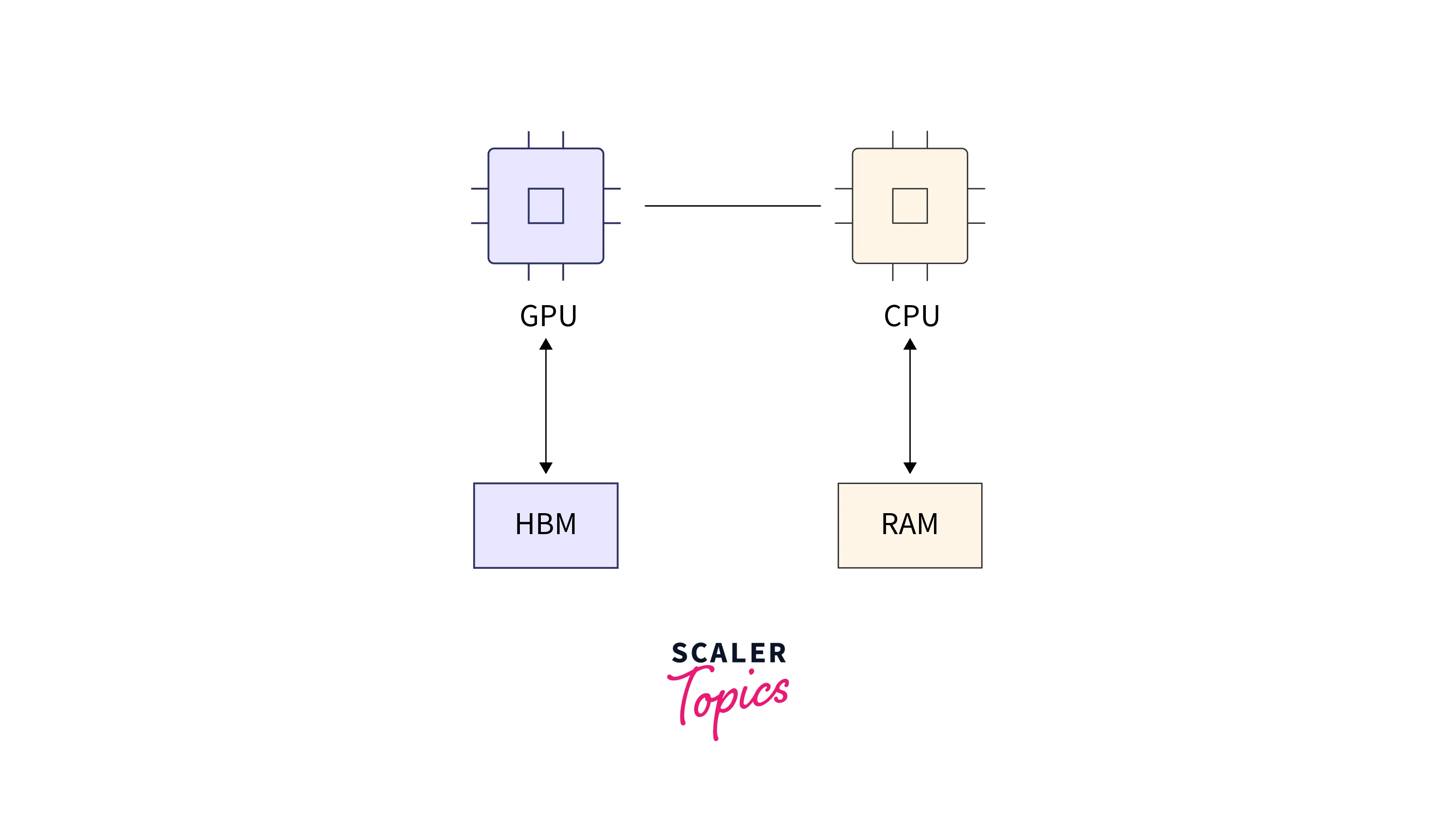
- Model Quantization:
Consider applying model quantization techniques, such as post-training quantization or quantization-aware training, to reduce model size and memory requirements while maintaining acceptable performance. This can be particularly useful when deploying models on resource-constrained devices. - Computation Graph Optimization:
Utilize TensorFlow's graph optimizations, such as graph pruning and function inlining, to optimize the computation graph of your model. These optimizations can reduce redundant computations and improve overall execution speed.
Model Updates and Versioning in TFHub
Model updates and versioning are critical aspects of working with TensorFlow load models, allowing for improvements, bug fixes, and maintaining compatibility over time. TFHub provides mechanisms to handle updates and versioning effectively. Here's an overview:
- Model Updates:
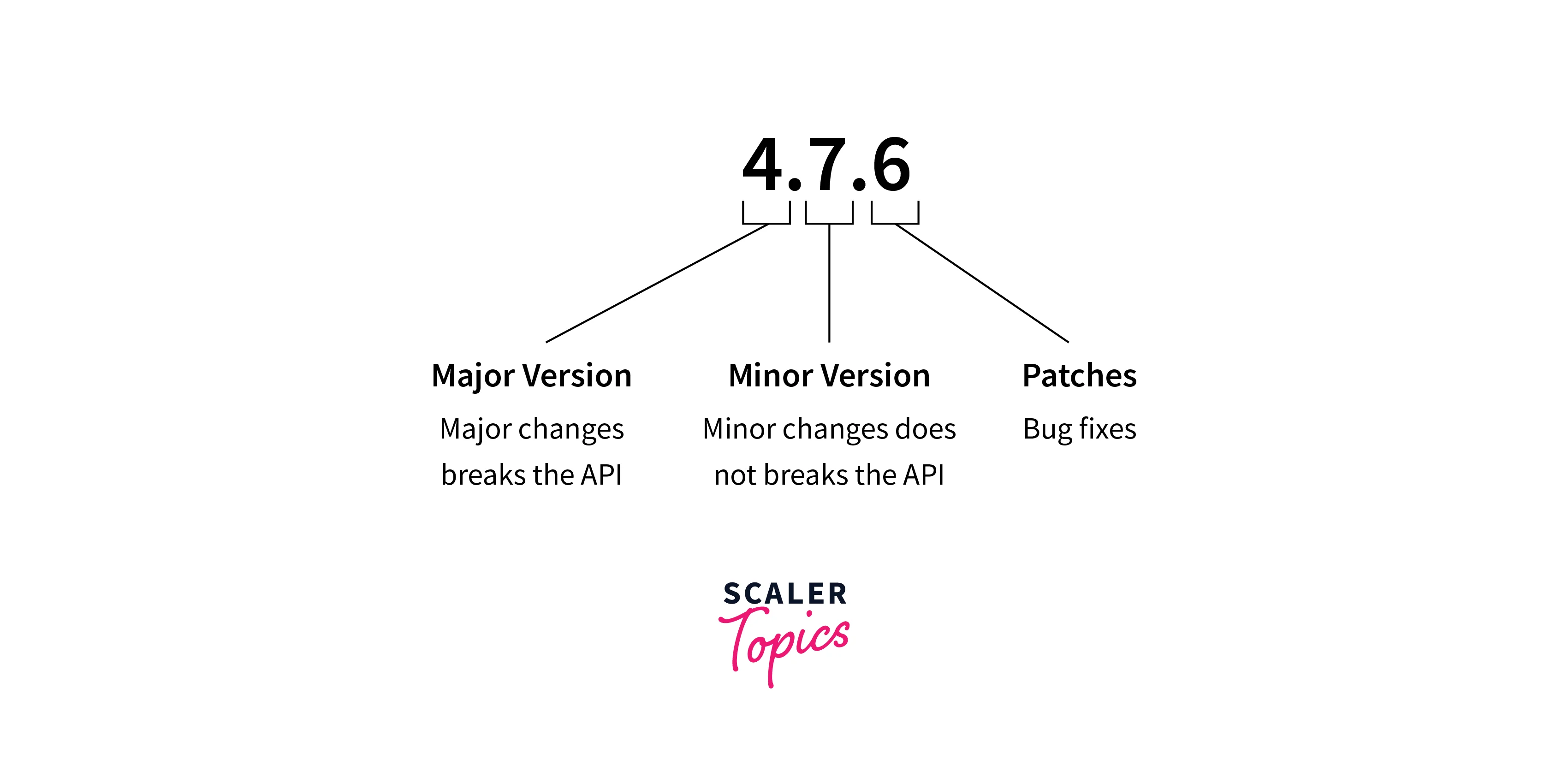
TensorFlow load models undergo updates to incorporate new features, improvements, or fixes. These updates may include changes to the model architecture, weights, or additional resources. Regularly check for updates to ensure you're using the latest version of the model. - Semantic Versioning:
TFHub follows semantic versioning, where each model is assigned a version number in the form of MAJOR.MINOR.PATCH. MAJOR version updates signify significant changes that may require modifications to your code, while MINOR and PATCH updates introduce backward-compatible enhancements and bug fixes, respectively.
Handling Model Updates and Keeping Track of Model Versions
Managing model updates and tracking versions in a project is crucial for reproducibility and ensuring consistency across different runs or deployments. Here are some practices to handle model updates and versioning effectively:
- Version Control:
Utilize version control systems, such as Git, to track changes in your project code, including the usage of TensorFlow load models. This allows you to roll back to previous versions, tag specific model versions, and maintain a clear history of model updates. - Documentation:
Maintain documentation that captures the model version(s) used in your project. Include details about the TFHub model URL, the version number, and any additional information necessary to reproduce the model setup accurately. - Fixed Model Version:
To ensure consistent results, fix the model version used in your project. Specify the exact version of the TFHub model in your code, making it explicit and avoiding unintentional updates when new versions are released.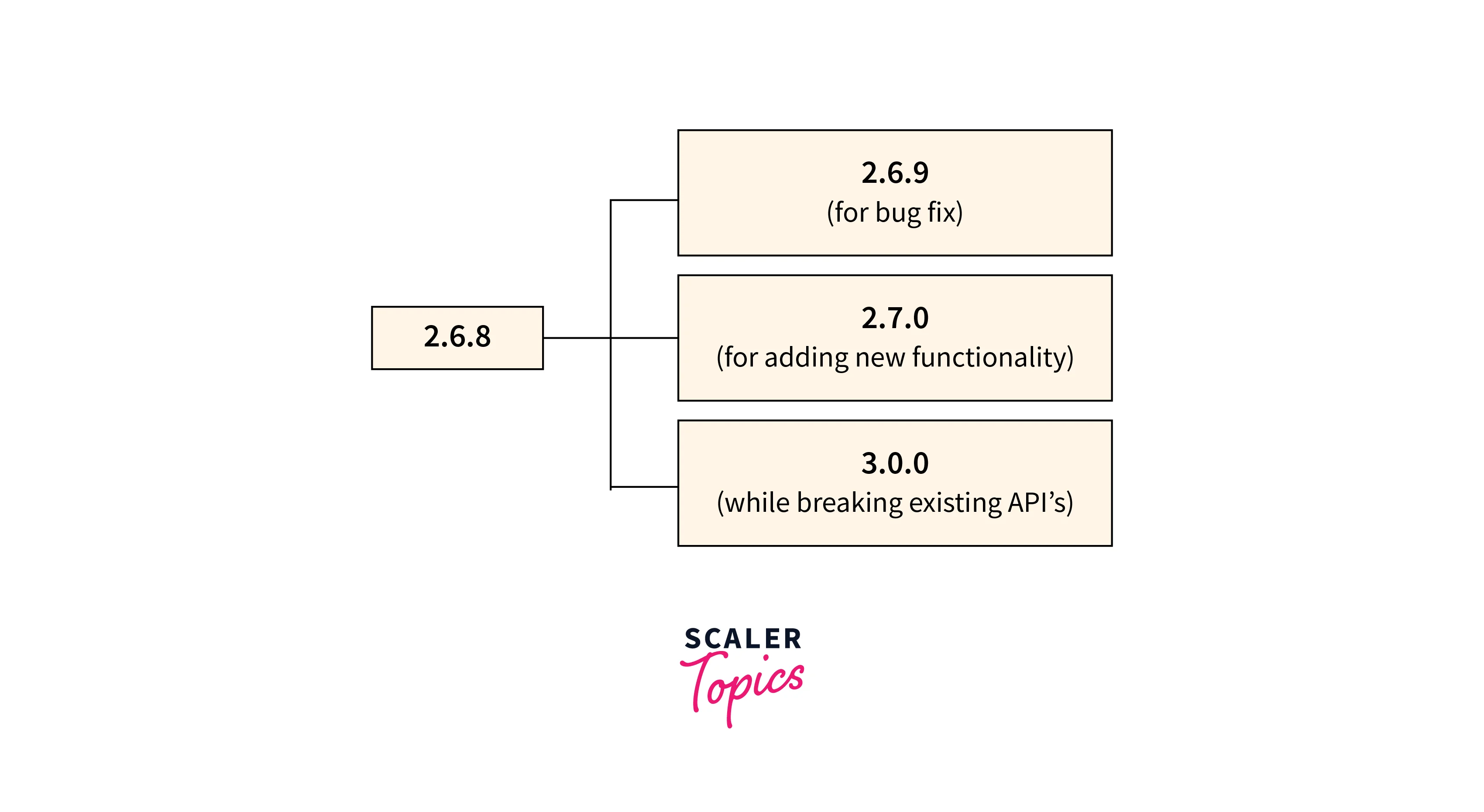
- Model Versioning in SavedModel Format:
When saving and sharing your own models in the SavedModel format, consider following semantic versioning principles to indicate updates and changes made to your custom models. This helps ensure proper versioning when integrating them with TensorFlow load models. - Model Validation:
Regularly validate and compare results obtained using different model versions. This ensures that any changes in model behavior are detected, and the impact on your project's outputs is assessed.
Conclusion
- Customizing TensorFlow Hub (TFHub) models allows us to tailor them to specific requirements, enhancing their performance and adaptability for unique machine learning tasks.
- Techniques such as feature extraction, fine-tuning, and model stacking provide flexibility in modifying and extending TFHub model architectures to suit our needs, enabling us to leverage the pre-trained knowledge while customizing the models for our specific applications.
- Considerations and best practices, including compatibility checks, regularization implementation, and documentation, are crucial for successful customizations, ensuring reproducibility, efficiency, and effective management of TensorFlow load models in our projects.