Text and NLP with TensorFlow
Overview
TensorFlow NLP (Natural Language Processing) covers various essential topics, including sentiment analysis, named entity recognition, text generation, text summarization, neural machine translation, and transfer learning for text.
This article showcases how TensorFlow can be utilized to solve complex NLP tasks effectively. By leveraging TensorFlow's advanced features and tools, developers and researchers can harness the true potential of NLP and create innovative applications that understand, generate, and interpret human language with remarkable accuracy.
Introduction to NLP
NLP, or Natural Language Processing, is a branch of artificial intelligence that focuses on the interaction between computers and human language. It involves the analysis, understanding, and generation of human language to enable machines to comprehend and communicate with humans more effectively.
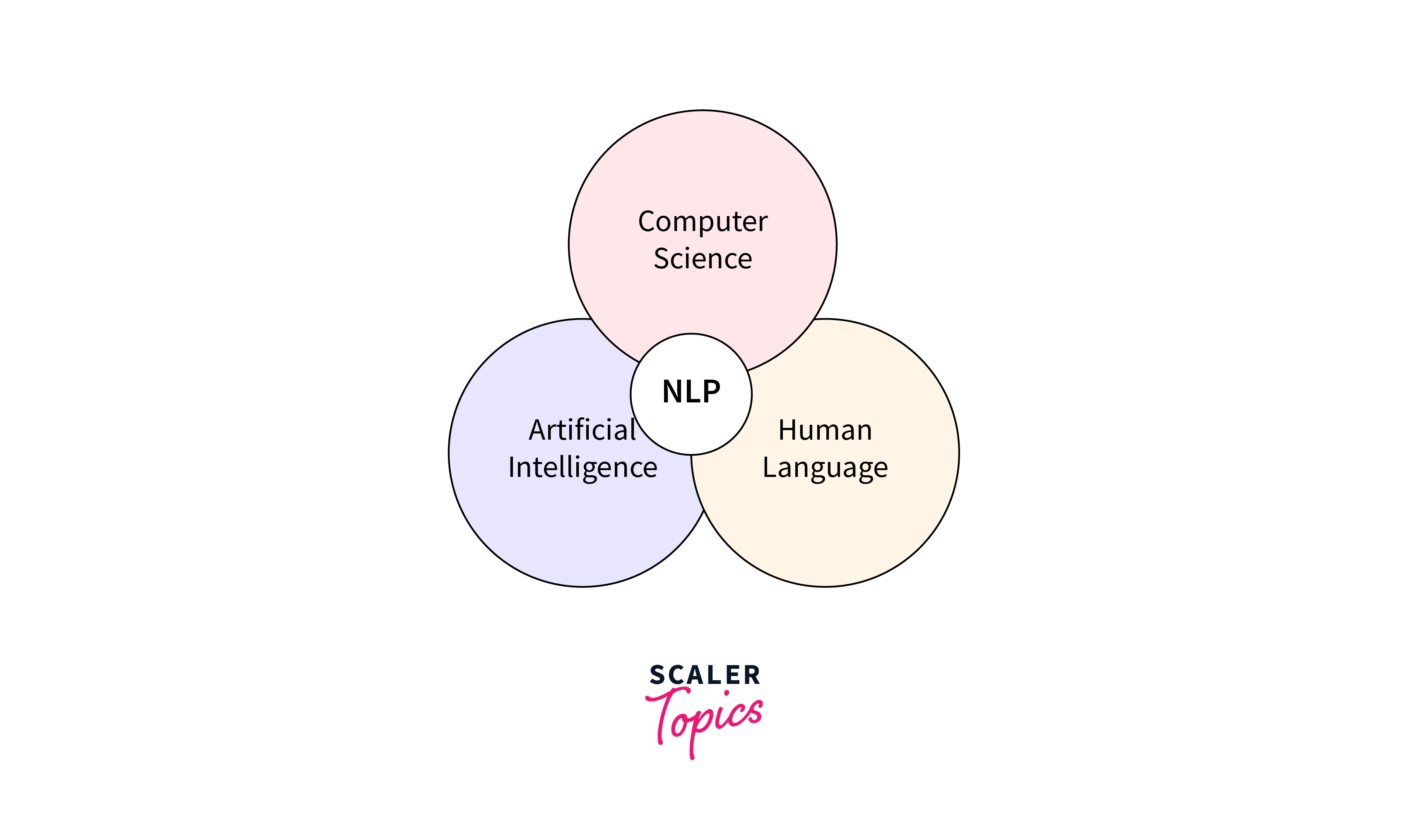
- Language Understanding:
NLP aims to teach machines how to understand and interpret human language in various forms, including written text, spoken words, and gestures. - Language Generation:
NLP enables machines to generate human-like language, allowing them to communicate with humans in a more natural and meaningful way.
Tensorflow NLP continues to advance, opening doors to new possibilities and applications across industries, including healthcare, finance, customer service, and more.
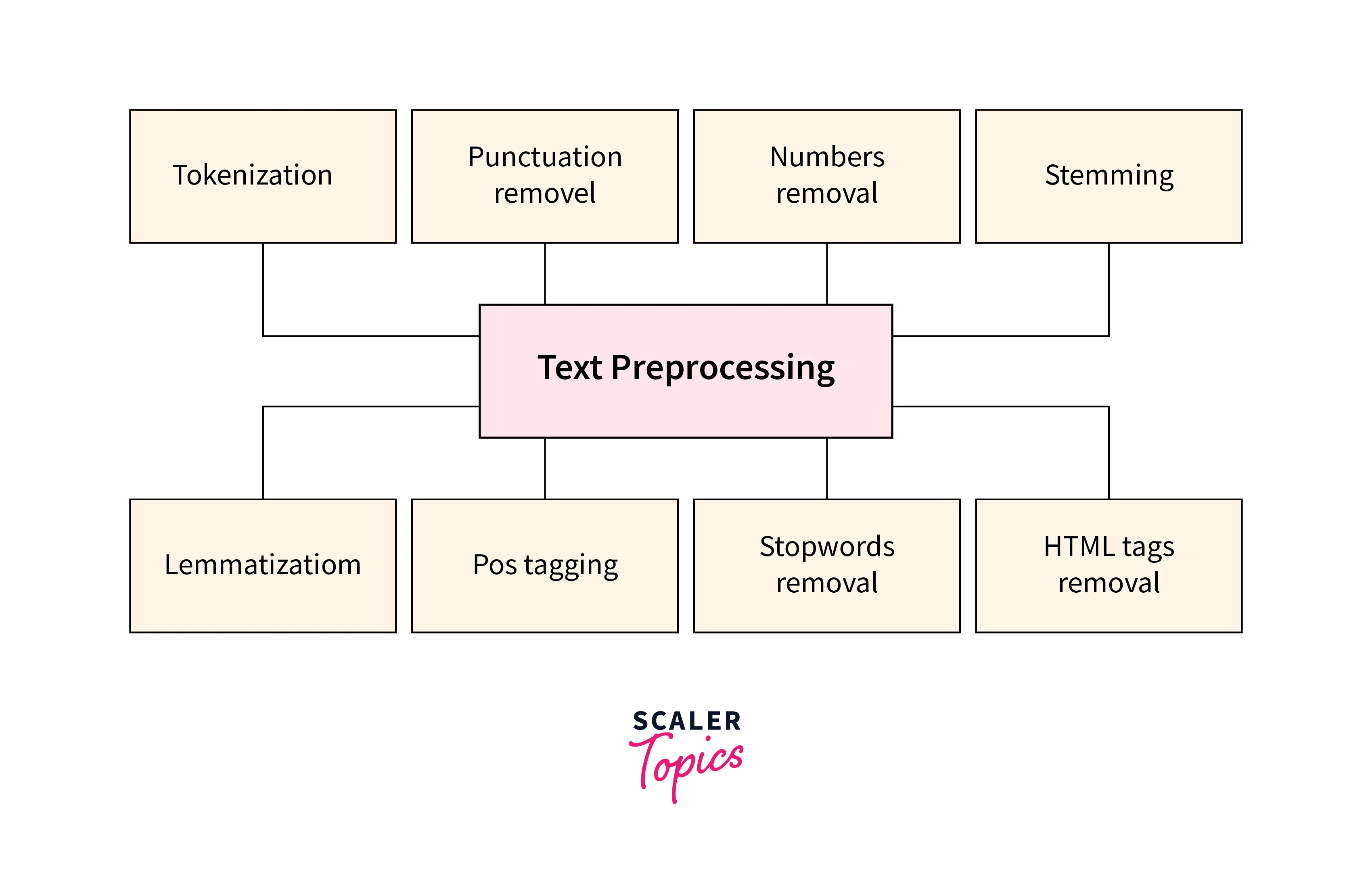
What is Text Preprocessing?
Text preprocessing involves transforming raw text into a format that is suitable for analysis.
- It includes tasks like tokenization, removing stop words, stemming or lemmatization, and handling special characters and punctuation.
- TensorFlow NLP provides several useful tools and libraries, such as TensorFlow Text, that facilitate text preprocessing tasks efficiently.
- These tools can be used to tokenize text, perform various normalization techniques, and convert text into numerical representations suitable for machine learning models.
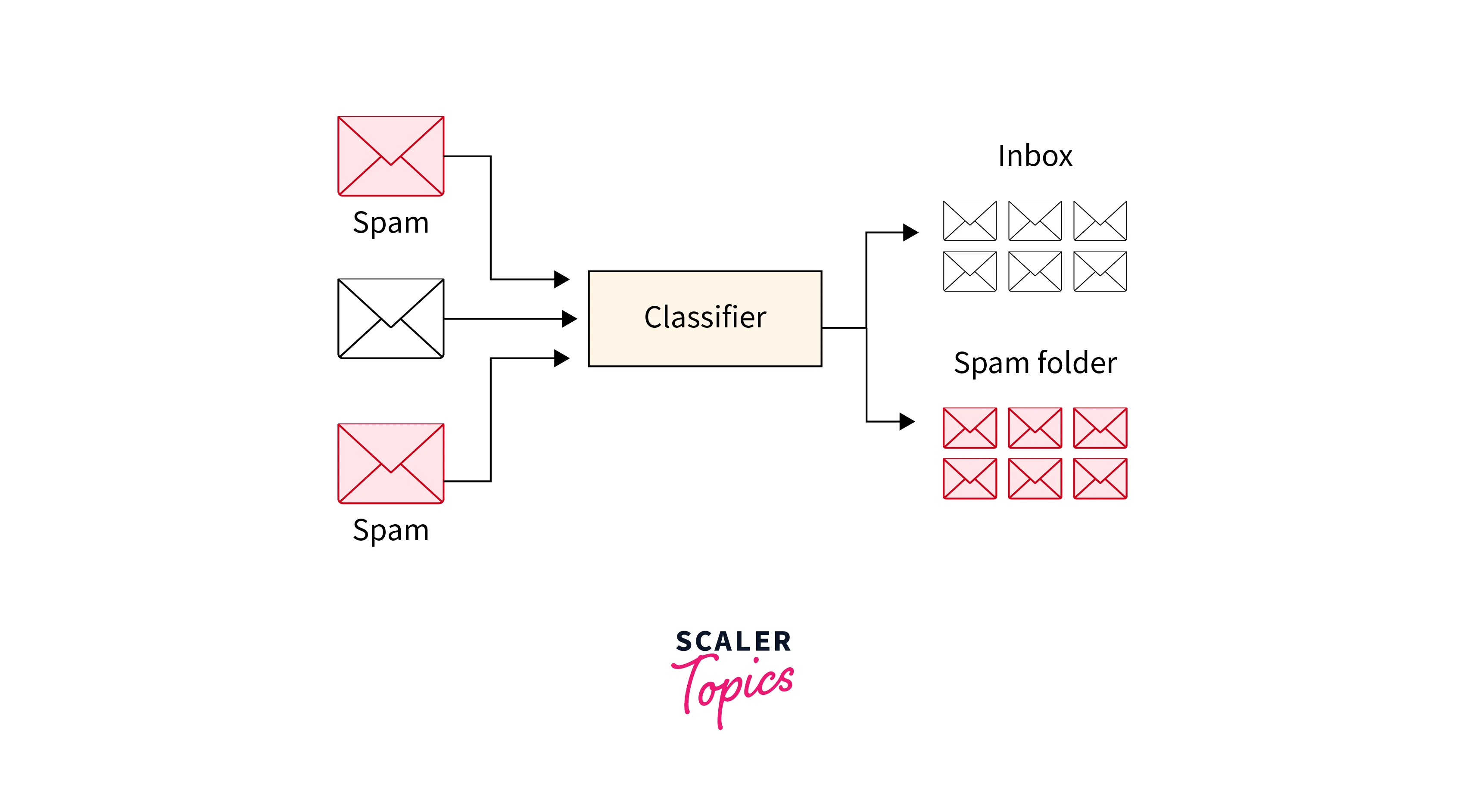
What is Text Classification?
Text classification is the process of categorizing text documents into predefined classes or categories.
- It finds applications in spam filtering, sentiment analysis, topic classification, and many more.
- TensorFlow NLP offers a rich ecosystem for building powerful text classification models. With its high-level API, TensorFlow Keras, you can easily construct deep learning models such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), or transformer-based models like BERT for text classification tasks.
- The flexibility of TensorFlow NLP allows for seamless experimentation and efficient model training and evaluation.
Sentiment Analysis with TensorFlow NLP
Sentiment analysis, a specific task in text classification, focuses on determining the sentiment or emotion expressed in a piece of text.
Sentiment analysis is a powerful tool that teaches computers to understand human emotions in text. By analyzing the words and phrases used, it determines whether a piece of text expresses a positive, negative, or neutral sentiment. This process involves training algorithms on vast amounts of labeled data to recognize patterns and context, allowing them to accurately interpret the underlying emotional tone.
Sentiment analysis finds applications in social media monitoring, customer feedback analysis, and brand perception tracking, providing valuable insights into public sentiment and opinions. It's like giving machines the ability to read between the lines and grasp the feelings behind the words.
In this section, we will explore how to build a sentiment analysis model using TensorFlow NLP, a powerful deep learning framework. We will cover the necessary steps from imports to model evaluation, providing code examples along the way.
What is Sentiment Analysis?
Sentiment Analysis, also known as opinion mining, is a natural language processing (NLP) technique used to determine the sentiment or emotion expressed in a piece of text. Here are five key points about sentiment analysis:
-
Purpose:
The main objective of sentiment analysis is to analyze text data, such as customer reviews, social media posts, or feedback, and classify it that represent different sentiments, such as positive, negative, or neutral. -
Text Classification:
Sentiment analysis is a specific type of text classification task where the focus is on determining the sentiment polarity of the text. It involves training machine learning models to classify text as positive, negative, or neutral based on the underlying sentiment expressed. -
Techniques:
Sentiment analysis can employ various techniques, including rule-based approaches, machine learning algorithms (such as Naive Bayes, Support Vector Machines, or deep learning models), and lexicon-based methods that utilize sentiment dictionaries. -
Applications:
Sentiment analysis finds application in a wide range of domains, including customer feedback analysis, brand reputation management, social media monitoring, market research, political analysis, and personalized recommendation systems. -
Challenges:
Sentiment analysis faces challenges such as handling sarcasm, irony, and context-dependent sentiment, dealing with noisy or ambiguous text, and addressing language variations and linguistic nuances across different domains and cultures.
How are we Going to Build This?
To build a sentiment analysis model, we can follow these five key steps:
-
Data Collection:
Gather a labeled dataset consisting of text samples paired with sentiment labels (positive, negative, or neutral). This dataset can be obtained from publicly available sources or manually labeled by domain experts. -
Data Preprocessing:
Clean and preprocess the text data by removing unnecessary characters, converting text to lowercase, and applying techniques like tokenization, stemming, or lemmatization. Additionally, handle common preprocessing tasks such as removing stop words and handling special characters or punctuation.
-
Feature Extraction:
Convert the preprocessed text into numerical representations that can be processed by machine learning models. Techniques like word embeddings (such as Word2Vec or GloVe) can be used to represent words as dense vectors, capturing semantic relationships between words. -
Model Selection and Training:
Choose an appropriate machine learning algorithm or deep learning architecture for sentiment analysis, such as Naive Bayes, Support Vector Machines, recurrent neural networks (RNNs), or transformer-based models like BERT. Split the dataset into training and validation sets, train the selected model on the training set, and tune the hyperparameters for optimal performance. -
Model Evaluation and Deployment:
Evaluate the trained model on the validation set using metrics like accuracy, precision, recall, and F1 score.
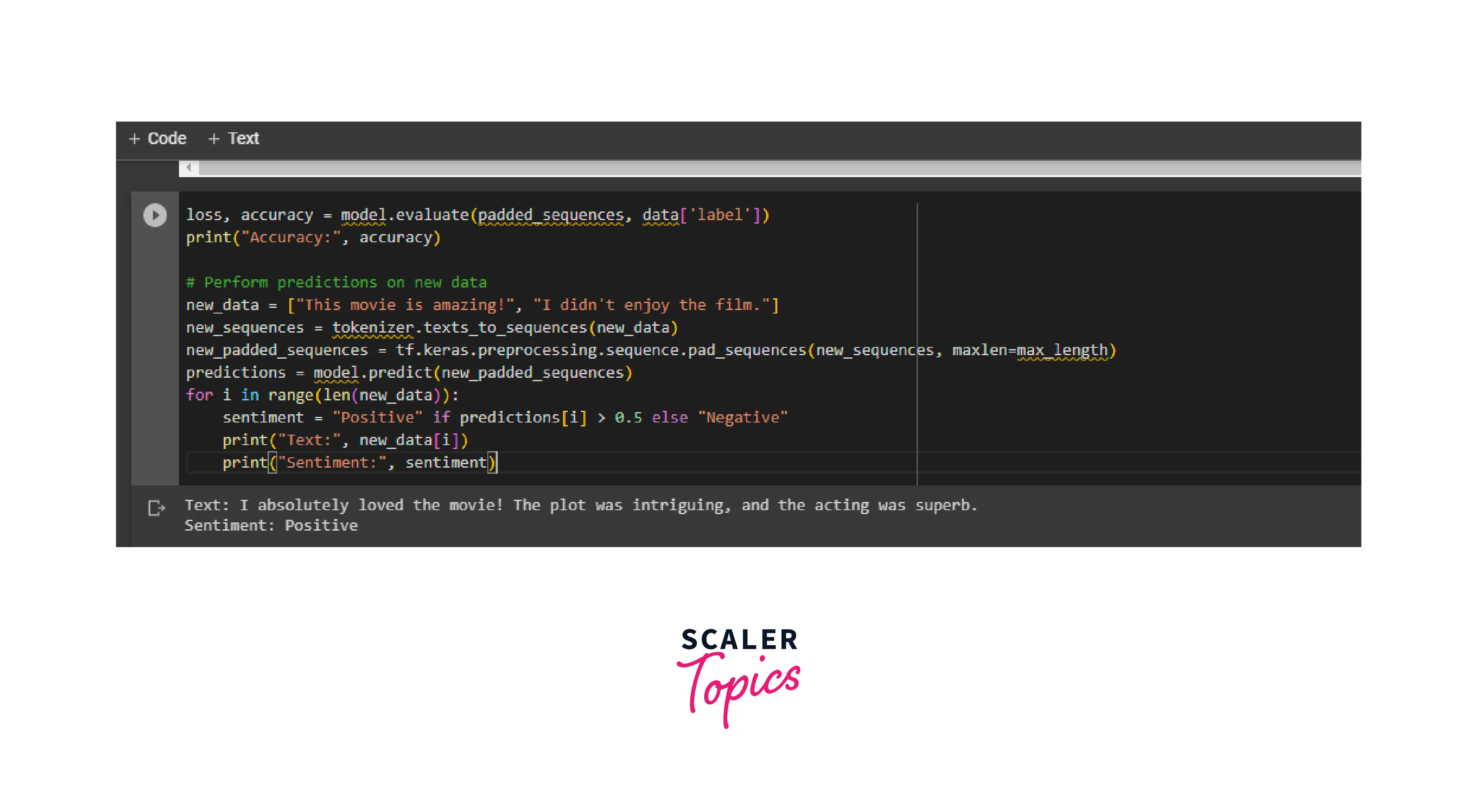
Final Output:
In this sample output, the sentiment analysis model predicts the sentiment of different text samples. The model categorizes each text as positive, negative, or neutral based on the sentiment expressed.
Sentiment Analysis with TensorFlow NLP
In this section, we are going to perform sentiment analysis with TensorFlow NLP capabilities. Load the IMDb Movie Reviews dataset, preprocess the text data using tokenization and padding, build a sentiment analysis model with an embedding layer and LSTM, and train and evaluate the model for sentiment classification.
1.Imports
Let's start by importing the required libraries and modules for our sentiment analysis project using TensorFlow, NumPy, and Pandas. These libraries will provide the necessary tools for data manipulation, model building, and evaluation.
2.Setting up TensorFlow NLP
Before diving into the project, we need to ensure that TensorFlow is properly set up on our system. We'll guide you through the installation process and verify the installation by running a simple TensorFlow program.
3.Data Preparation
For sentiment analysis, we need a labeled dataset. We can use popular datasets like the IMDb Movie Reviews dataset or the Twitter Sentiment Analysis dataset.
4.Model Training
In this step, we'll construct our sentiment analysis model using TensorFlow NLP. We'll explore different approaches, such as using word embeddings like Word2Vec or GloVe, and recurrent neural networks (RNNs) like LSTM or GRU.
- The use of an LSTM-based model for sentiment analysis is strategic due to its proficiency in recognizing sequential patterns in text.
- LSTMs excel at grasping contextual relationships between words, which is vital for sentiment understanding. The model employs an embedding layer to convert words into meaningful vectors, followed by an LSTM layer that captures sequence dynamics.
- This architecture's strength lies in its ability to unravel the intricate emotional nuances hidden within language, making it a strong choice for sentiment analysis tasks.
5.Model Evaluation and Analysis
Once the model is trained, we need to evaluate its performance. We'll use metrics like accuracy, precision, recall, and F1 score to assess the model's effectiveness.
Testing
Sample Output screenshot:
Named Entity Recognition (NER) with TensorFlow NLP
Named Entity Recognition (NER) is a natural language processing (NLP) task that aims to identify and classify named entities in text, such as names of people, organizations, locations, and more. By utilizing TensorFlow NLP, NER models can be built to extract meaningful information and understand the relationships between entities in textual data.
What is NER?
Named Entity Recognition (NER) is a subtask of natural language processing (NLP) that aims to identify and classify named entities in text into predefined categories such as person names, organizations, locations, dates, and more. It helps in extracting meaningful information and understanding the relationships between entities.

Real World Applications of NER
NER acts as a foundational tool for structuring and understanding unstructured text data, driving efficiency and insights across various industries. Let us see the real-world applications of NER.
- Information Extraction:
NER is employed to automatically extract essential information from unstructured text, such as identifying names of people, organizations, dates, and locations from news articles or legal documents. - Search Engines:
NER enhances search engine functionality by identifying and categorizing entities in search queries, improving search results' relevance and accuracy. - Social Media Monitoring:
NER helps analyze social media content by identifying mentions of products, brands, or public figures, aiding companies in understanding their online presence and reputation. - Chatbots and Virtual Assistants:
NER assists in understanding user queries and context, enabling chatbots and virtual assistants to provide more relevant responses and complete tasks effectively. - Biomedical Research:
In the medical domain, NER identifies biomedical entities like genes, proteins, and diseases in scientific literature, contributing to drug discovery and medical research. - Financial Analysis:
NER identifies financial entities like companies and stock symbols in news articles and reports, assisting in automated financial analysis and decision-making.
How are we Going to Build This?
To build a Named Entity Recognition (NER) model using the provided code, follow these steps:
-
Import the Required Libraries:
Begin by importing the necessary libraries, including TensorFlow, NumPy, and Pandas, to facilitate data manipulation, modeling, and evaluation. -
Set up TensorFlow:
Install the required version of TensorFlow and verify the installation using the print(tf.version) statement.
-
Prepare the Data:
Load the dataset, such as the CoNLL-2003 dataset, and preprocess the text data. Perform tokenization, label encoding, and convert the text into numerical representations. Pad the sequences to a maximum length for consistent input dimensions. -
Build and Train the NER Model:
Construct a Named Entity Recognition model using TensorFlow NLP. Utilize a sequential model with an embedding layer, a bidirectional LSTM layer, and a dense output layer. Compile the model with appropriate loss and optimizer. Train the model on the preprocessed dataset using model.fit(). -
Evaluate and Analyze the Model:
Evaluate the trained model on the dataset to assess its performance. Calculate the loss using model.evaluate() and analyze any additional metrics. Additionally, utilize the trained model to make predictions on new, unseen data to observe its ability to extract named entities.
Final Output:
- In this example output, the NER model has been trained and evaluated.
- The loss value indicates the model's performance on the dataset. Then, the model is used to predict the named entity labels for two new sentences.
- For the sentence "Apple Inc. is a technology company", the model predicts the label ORGANIZATION, correctly identifying "Apple Inc." as an organization.
- Similarly, for the sentence "John Smith is a great actor", the model predicts the label PERSON, correctly identifying "John Smith" as a person.
Named Entity Recognition (NER) with TensorFlow NLP
Named Entity Recognition (NER) with TensorFlow is an NLP technique that focuses on identifying and classifying named entities in text.
- By using TensorFlow NLP, NER models can be constructed to extract valuable information like person names, dates, locations, and organizations from unstructured textual data.
- TensorFlow NLP's powerful features enable accurate and efficient entity recognition, facilitating various applications such as information extraction, question-answering systems, and text analysis.
Tokenization:
Tokenization is a crucial step in natural language processing (NLP) as it forms the basis for various text analysis tasks, such as language modeling, sentiment analysis, and named entity recognition (NER). Tokens act as building blocks that facilitate the understanding and manipulation of text data by machine learning models.
Entity labeling:
on the other hand, involves annotating specific tokens in a text with labels that indicate their semantic meaning or category. In the context of named entity recognition (NER), entity labeling entails marking tokens that represent entities like names of people, organizations, locations, dates, and more.
Now, we will see the steps in detail to create a Named Entity Recognition (NER) with TensorFlow NLP.
1.Imports
Start by importing the necessary libraries and modules, including TensorFlow and other supporting libraries such as NumPy and Pandas.
2.Setting up TensorFlow for NLP
Set up TensorFlow on your system by installing the required version and verifying the installation.
3.Data Preparation
Prepare the training data for NER by selecting a suitable dataset, such as the CoNLL-2003 dataset, which consists of labeled entities. Perform necessary preprocessing steps, such as tokenization, labeling, and converting text into numerical representations.
4.Model Training
Construct a NER model using TensorFlow NLP, employing architectures like Bidirectional LSTM-CRF (Conditional Random Field) or transformer-based models such as BERT. Train the model on the labeled dataset and adjust hyperparameters for optimal performance.
5.Model Evaluation and Analysis
Evaluate the trained NER model using appropriate metrics like precision, recall, and F1-score. Analyze the results to assess the model's accuracy in identifying named entities. Visualize the entity recognition output to gain insights into the model's performance.
Testing
Optionally, perform testing on new, unseen data to observe the model's ability to extract named entities from different text inputs.
Output Screenshot:
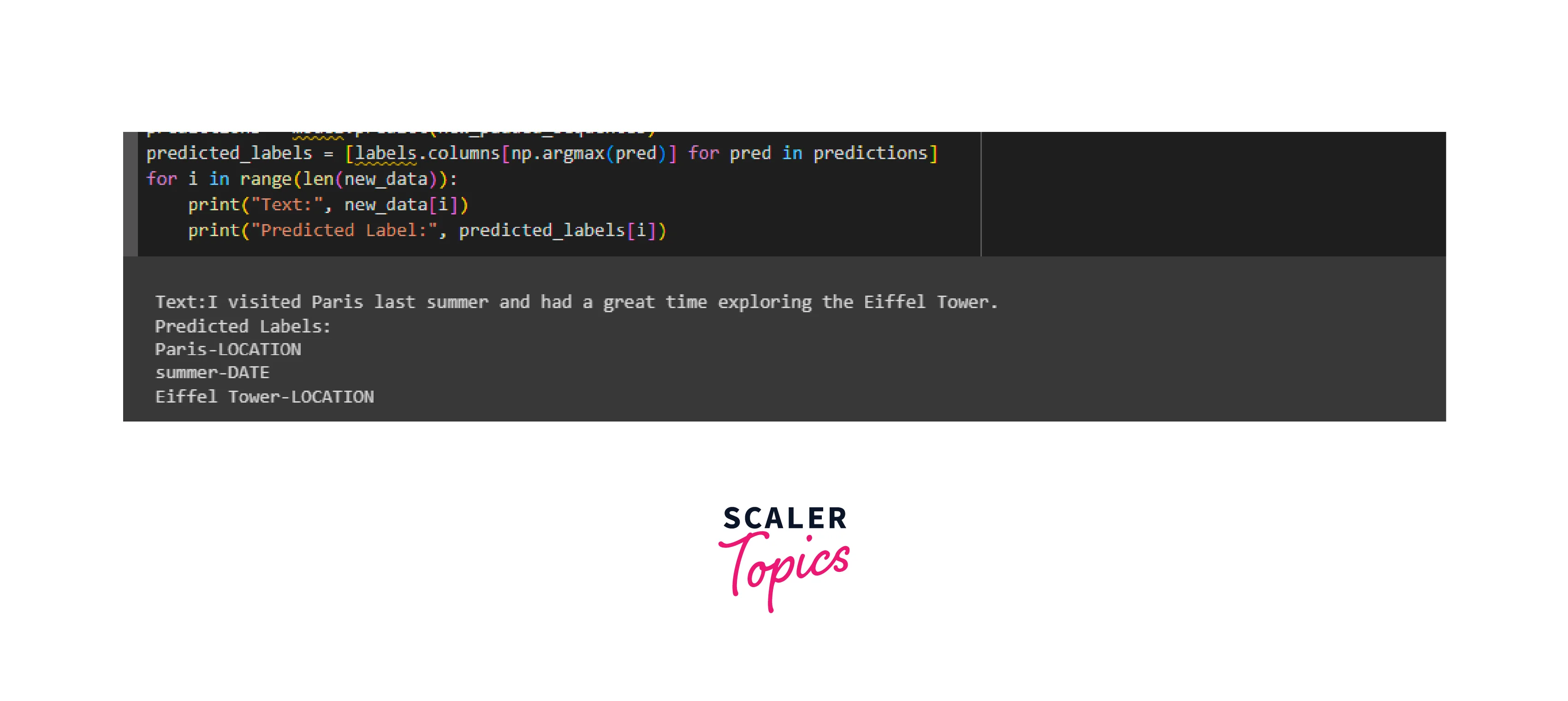
In this example, the NER model correctly identifies and classifies named entities in the given text. It recognizes "Paris" and "Eiffel Tower" as locations, and "summer" as a data entity. The NER model effectively extracts meaningful information from the text, enabling further analysis or application-specific processing based on the identified entities.
Text Generation with TensorFlow NLP
Text Generation with TensorFlow NLP is a fascinating field that harnesses the power of deep learning to automatically generate coherent and meaningful text. By training models on vast amounts of data, TensorFlow enables us to create language models capable of generating creative and contextually relevant text, opening doors to applications like storytelling, chatbots, and content generation.
What is Text Generation?
Text Generation is the task of automatically generating coherent and meaningful text, often in the form of sentences or paragraphs, using machine learning techniques. It involves training a model to learn the patterns and structure of a given text corpus and then generating new text based on that learned knowledge.
Applications of Text Generation:
Text generation, a fascinating NLP task, finds versatile applications across various domains:
- Chatbots and Virtual Assistants:
Text generation powers responsive chatbots and virtual assistants, enabling them to engage in natural, human-like conversations and provide users with instant support and information. - Creative Writing Assistance:
Authors and content creators employ text generation tools to spark their creativity and generate storylines, characters, or even poetry, offering valuable inspiration and ideas. - Content Generation:
Text generation aids in producing vast amounts of content for websites, blogs, or social media platforms, streamlining content creation and marketing efforts. - Language Translation:
Text generation contributes to machine translation systems by generating translations for sentences or phrases, improving the speed and accuracy of translation services. - Code Generation:
Developers utilize text generation to automate code writing, assisting in generating repetitive or boilerplate code segments. - Captioning and Subtitling:
Text generation adds captions to images or videos, making content accessible to a wider audience and enhancing user experience. - Data Augmentation:
Text generation augments training datasets for NLP models, improving model generalization by introducing variations in the text.
How are we Going to Build This?
To build a text generation model with TensorFlow NLP, follow these steps:
-
Import Libraries:
Begin by importing TensorFlow and other necessary libraries for data processing, model building, and evaluation. -
Data Preparation:
Gather a suitable text corpus or dataset, preprocess it by tokenizing and converting it into numerical representations, and split it into training and validation sets.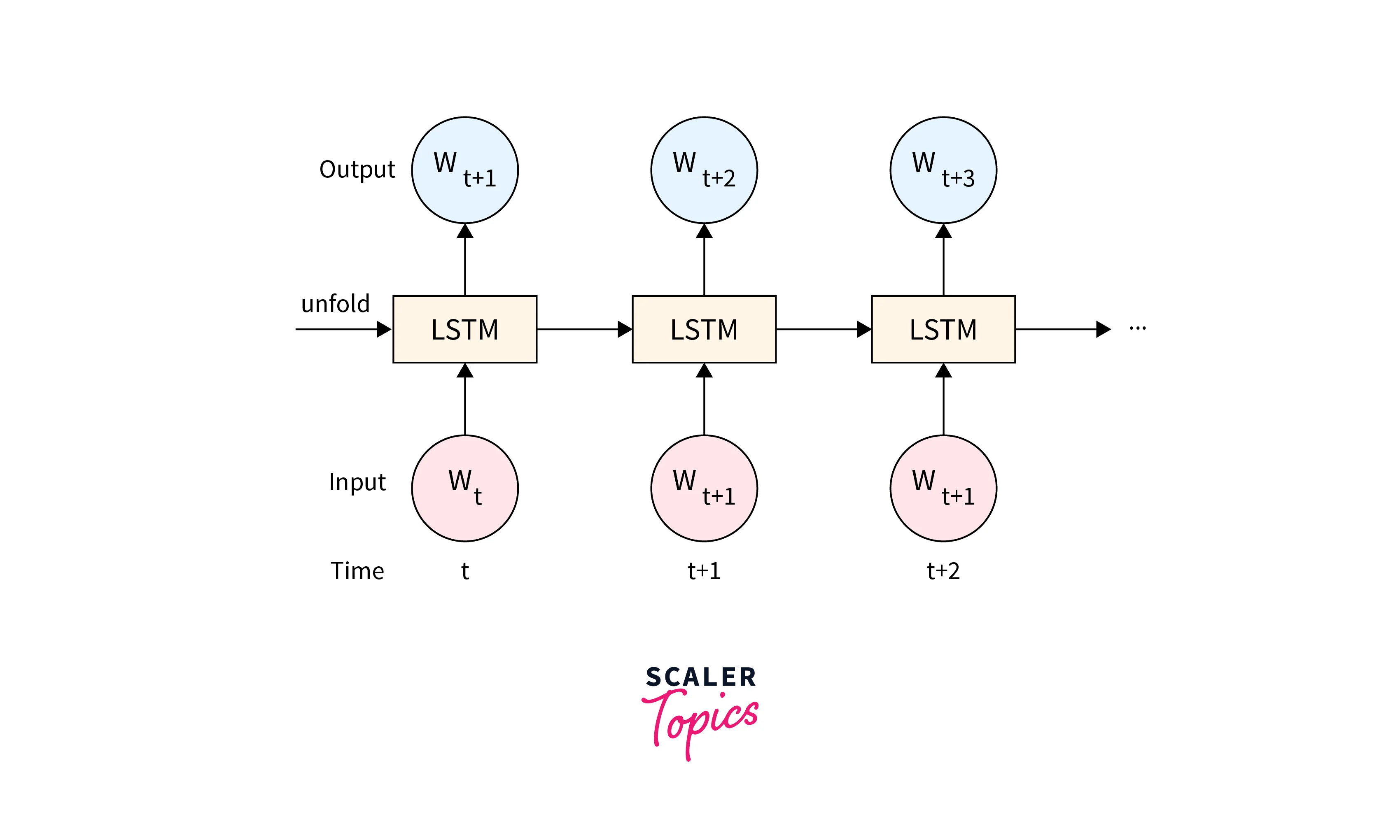
-
Build the Model:
Construct a language model using TensorFlow, such as a recurrent neural network (RNN) or a transformer-based architecture like GPT. Define the model architecture, including embedding layers, recurrent layers, and dense layers. -
Train the Model:
Train the text generation model using the prepared dataset, adjusting hyperparameters, and leveraging techniques like teacher-forcing or scheduled sampling to balance exploration and exploitation. -
Generate Text:
Use the trained model to generate text by providing a seed text or prompt. Generate new words or sequences by sampling from the model's predicted probabilities, and continue generating text recursively to create longer passages.
Final Output:
Seed Text: "Once upon a time"
Output:
Text Generation with TensorFlow NLP
The provided code and steps will guide you through the process of data preparation, model construction, training, evaluation, and text generation, unlocking the potential for creative and automated text generation.
1.Imports
Start by importing the necessary libraries and modules, including TensorFlow NLP and other supporting libraries such as NumPy and Pandas.
2.Setting up TensorFlow for NLP
Set up TensorFlow on your system by installing the required version and verifying the installation.
3.Data Preparation
Prepare the training data for text generation. Select a suitable text corpus or dataset, such as books, articles, or poems. Perform necessary preprocessing steps, such as tokenization and converting text into numerical representations.
4.Model Training
Construct a language model using TensorFlow NLP, such as a recurrent neural network (RNN) or a transformer-based model like GPT (Generative Pre-trained Transformer). Train the model on the preprocessed text data, leveraging techniques like teacher-forcing or self-attention mechanisms.
5.Model Evaluation and Analysis
Evaluate the trained text generation model by generating sample text and assessing its coherence and quality. Analyze the generated text and compare it with the original corpus to understand the model's performance and identify areas for improvement.
Output:
Testing
Let's test with another example:
Output:
Output Screenshot:

Text Summarization with TensorFlow NLP
Text Summarization involves the process of condensing a larger piece of text into a concise and informative summary. With TensorFlow, powerful models and techniques can be applied to generate summaries from text.
Introduction
Text summarization with TensorFlow NLP refers to the process of generating concise and informative summaries from larger pieces of text using the TensorFlow library. Text summarization can be broadly classified into two main types: extractive and abstractive summarization.
-
Extractive summarization involves selecting and combining important sentences or phrases from the original text to form a summary.
-
In contrast, abstractive summarization aims to generate new sentences that capture the main ideas of the original text, often by paraphrasing and rephrasing the content.
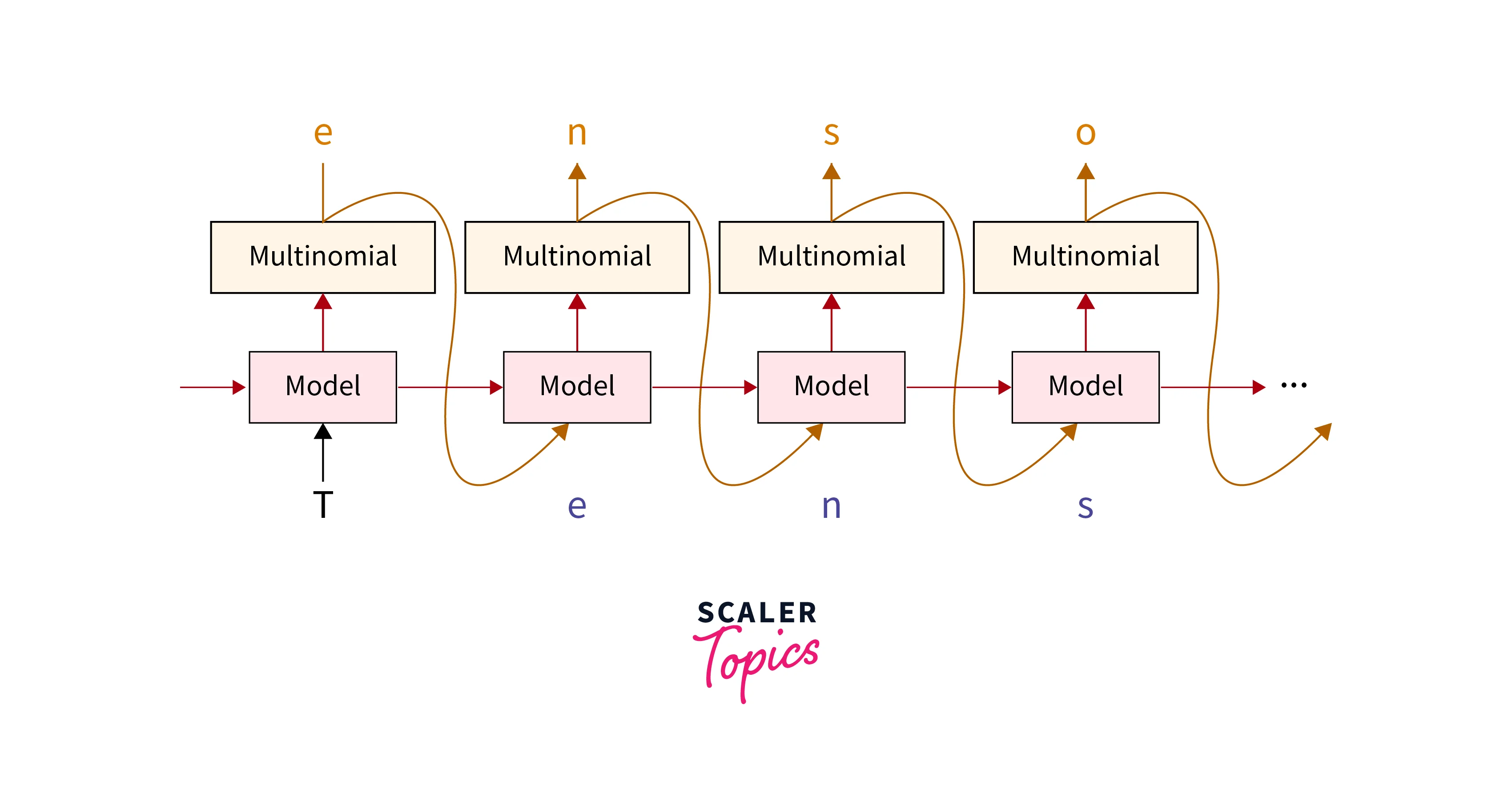
Techniques for Text Summarization
TensorFlow NLP offers a range of techniques and models that can be utilized for text summarization tasks. Some common approaches include:
-
Recurrent Neural Networks (RNNs):
TensorFlow provides support for RNN-based models such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). These models can be used to process sequential data like text and generate summaries by capturing the context and relationships between words.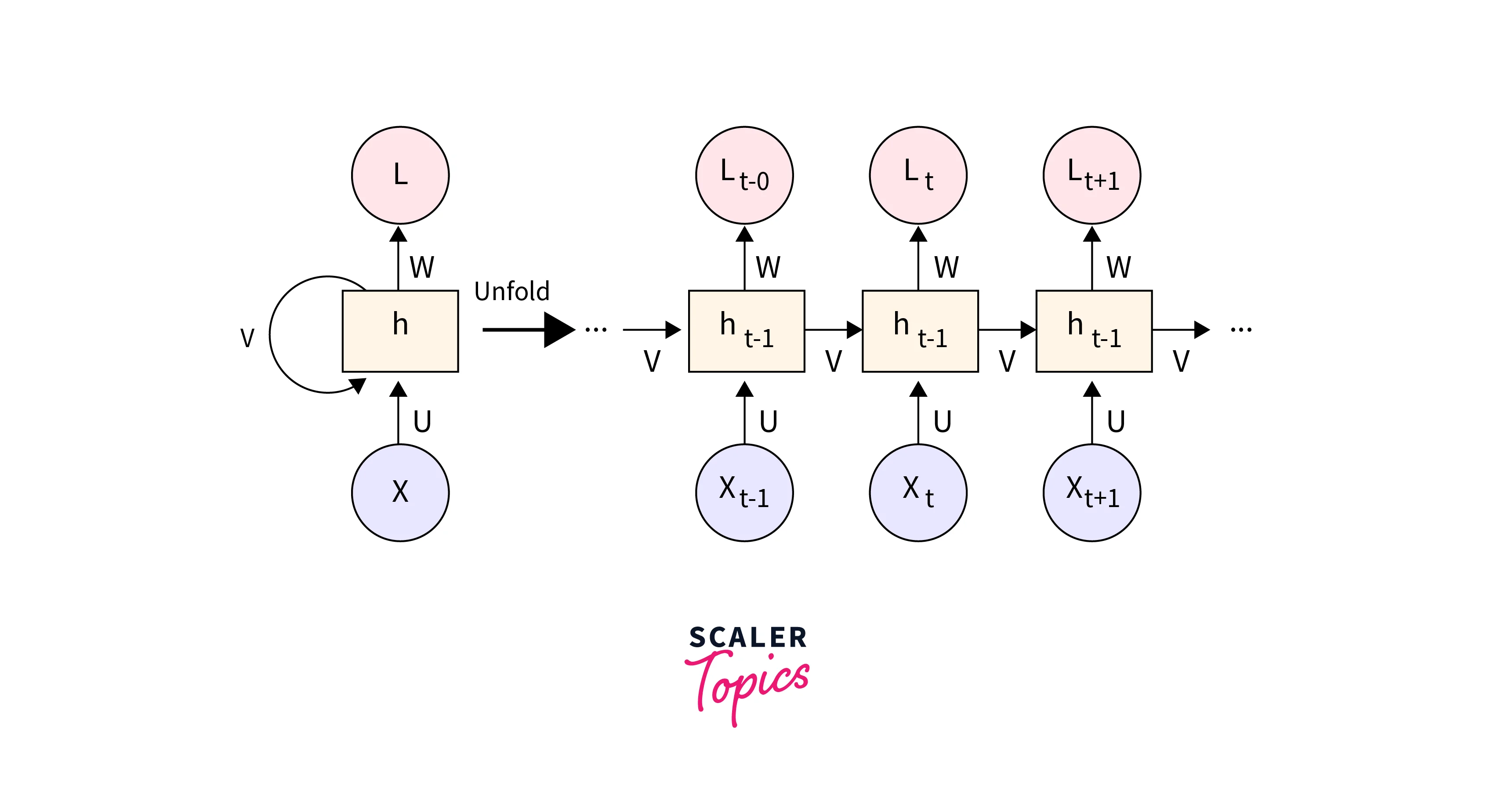
-
Transformer Models:
TensorFlow includes implementations of transformer-based models, such as the popular BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) models. These models leverage attention mechanisms to capture the contextual information and generate high-quality abstractive summaries.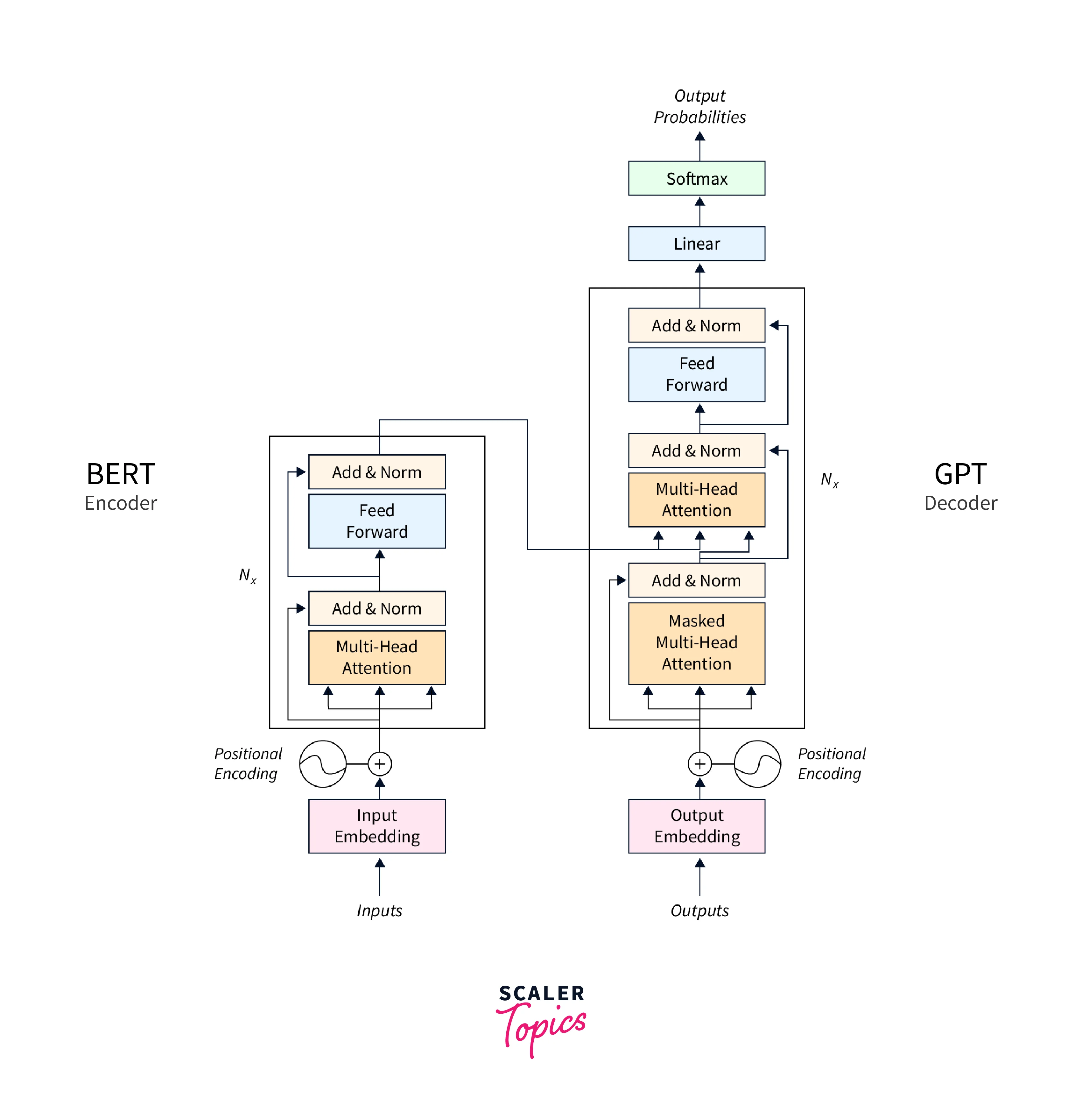
-
Sequence-to-Sequence Models:
TensorFlow's Seq2Seq framework allows you to build encoder-decoder models for text summarization. The encoder processes the input text and generates a fixed-length representation, which is then used by the decoder to generate the summary. This framework can be used for both extractive and abstractive summarization tasks. -
Transfer Learning:
TensorFlow facilitates transfer learning, where pre-trained models trained on large datasets can be fine-tuned for specific summarization tasks. This approach can save training time and improve the performance of the summarization model.
Code Example
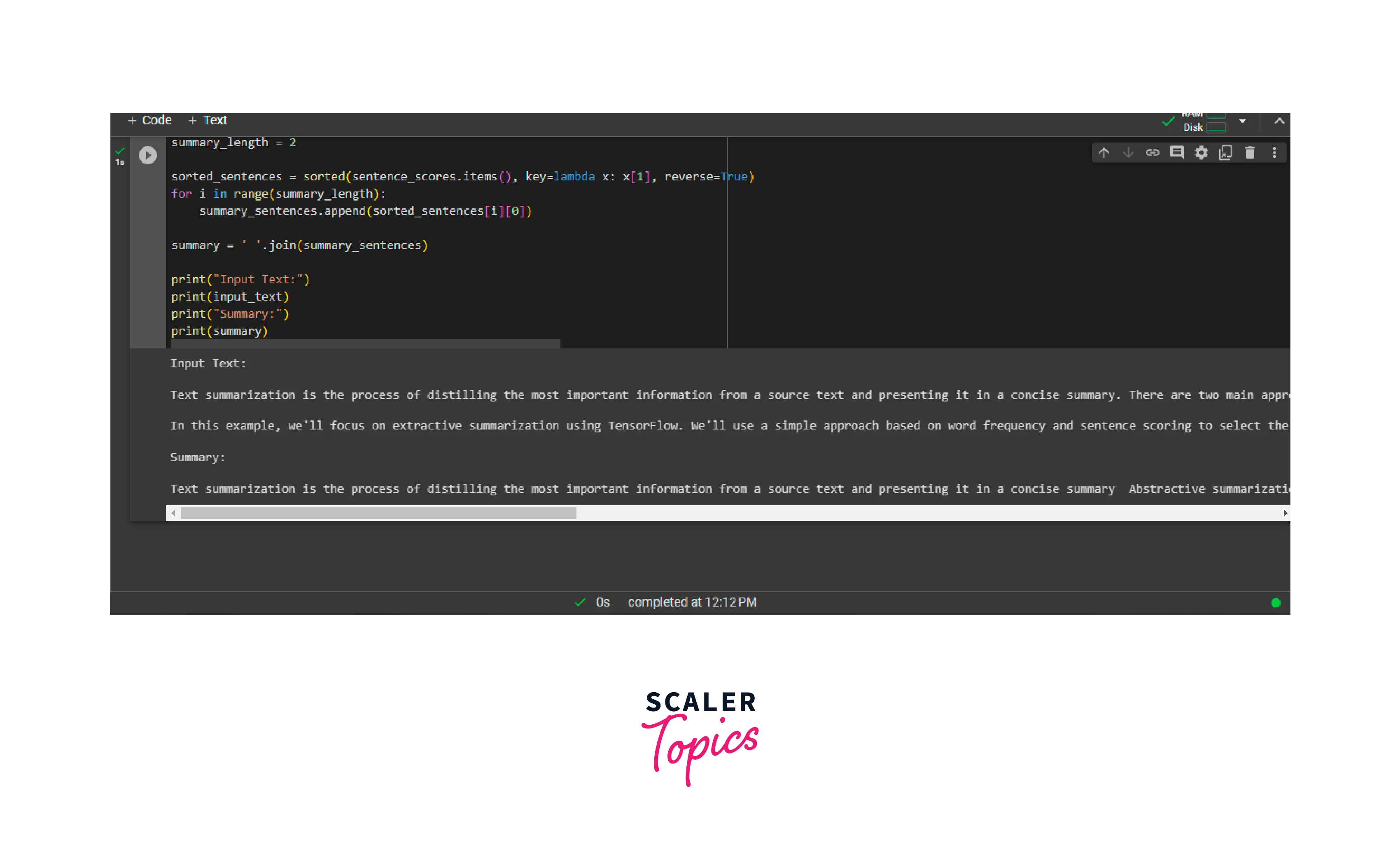
Here's an example code snippet that demonstrates how to perform text summarization using TensorFlow NLP and the extractive summarization approach:
Output:
The output for the provided example code would be:
Input Text:
Summary:
Output Screenshot:
Neural Machine Translation with TensorFlow NLP
Neural Machine Translation (NMT) is a subfield of natural language processing that focuses on developing models to automatically translate text from one language to another. TensorFlow, an open-source machine learning framework, offers powerful tools and capabilities for building NMT systems.
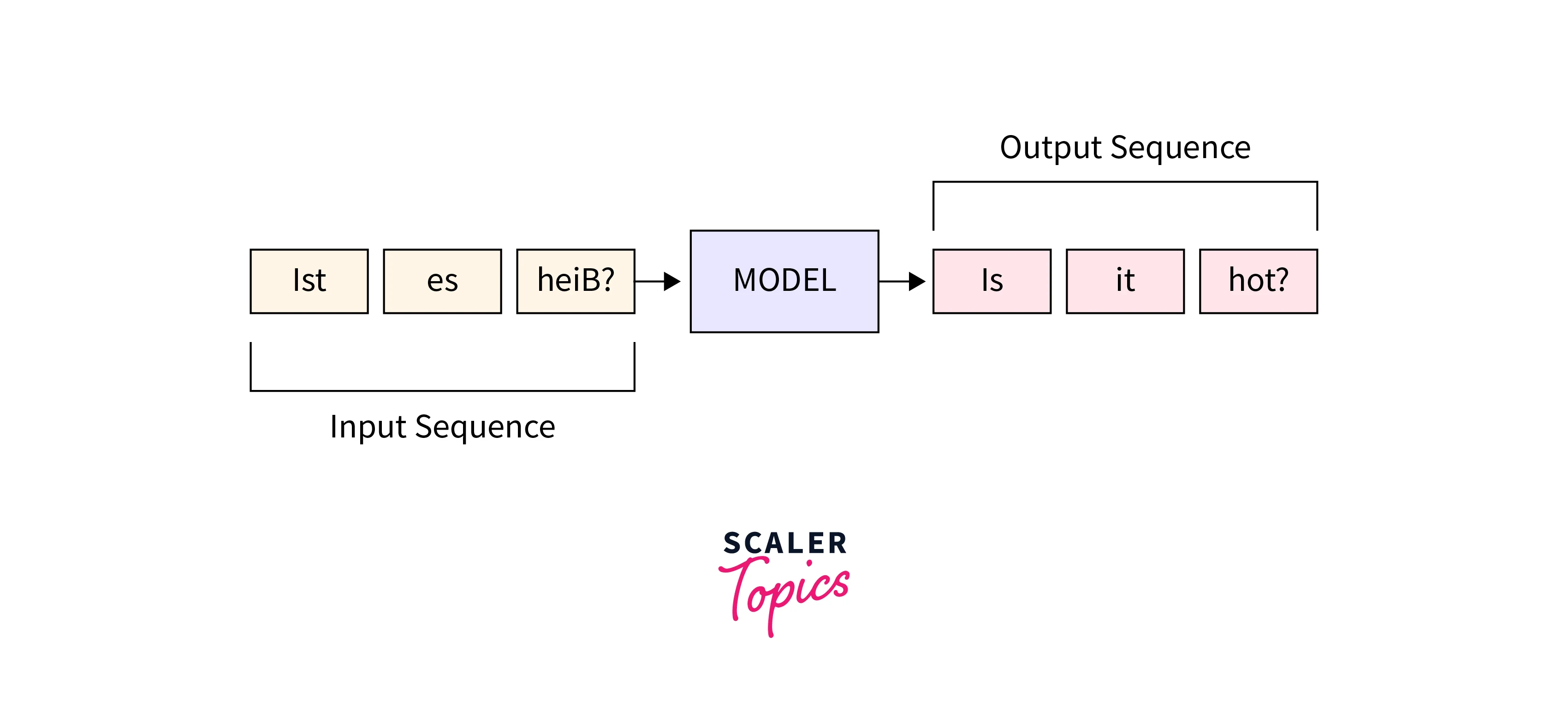
Here are seven key points about Neural Machine Translation with TensorFlow NLP:
-
Sequence-to-Sequence Models:
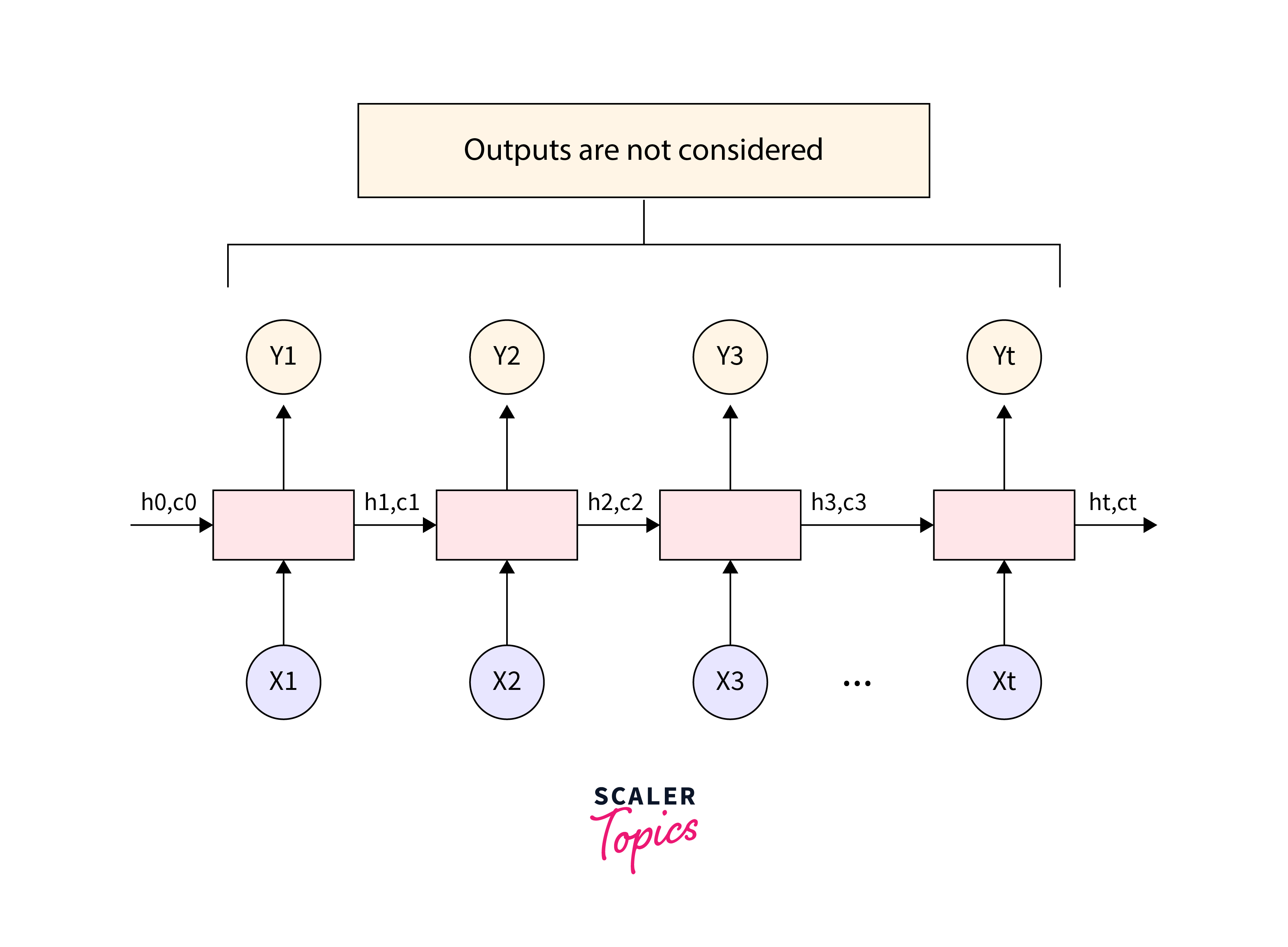
TensorFlow provides the framework to build sequence-to-sequence models, which are commonly used in NMT. These models consist of an encoder that processes the source language input and a decoder that generates the translated output.-
In sequence-to-sequence models, the encoder processes the input sequence (source language) by encoding its information into a fixed-length context vector or hidden state.
-
The decoder, on the other hand, takes the context vector generated by the encoder and uses it as the initial state to generate the output sequence (translated language).
-
-
Attention Mechanisms:
TensorFlow supports attention mechanisms, which enhance the translation process by allowing the model to focus on specific parts of the input during decoding. Attention mechanisms improve translation quality, particularly for long and complex sentences. -
Recurrent Neural Networks (RNNs):
TensorFlow NLP offers RNN-based models, such as LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit), which are widely used in NMT. RNNs help capture the sequential dependencies in the source and target languages, aiding in translation. -
Transformer Models:
TensorFlow includes transformer-based models, like the popular "Transformer" model, which have gained significant attention in NMT. Transformers leverage self-attention mechanisms to capture contextual information and have shown impressive performance in translation tasks.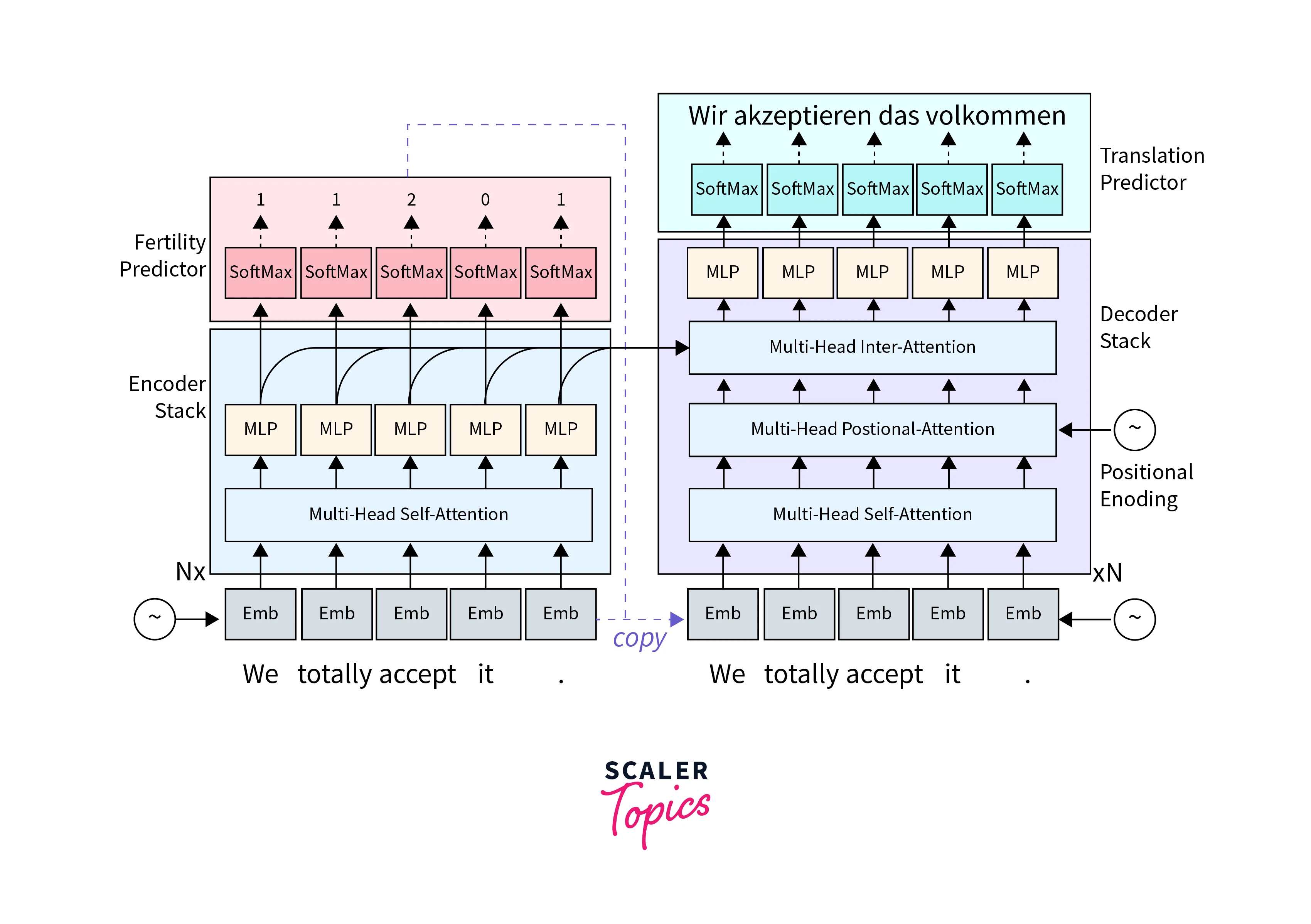
-
Data Preprocessing:
TensorFlow provides various utilities for data preprocessing in NMT, including tokenization, subword encoding (e.g., Byte Pair Encoding), and batching. These preprocessing steps help convert text into a format suitable for training NMT models. -
Training and Inference:
TensorFlow NLP facilitates the training and inference processes in NMT. It supports efficient computation on GPUs, distributed training across multiple devices, and the ability to save and load models for future use. -
Open-Source Pretrained Models:
TensorFlow NLP offers access to pretrained NMT models, such as the "TensorFlow Translation Toolkit" (T2T) and the "Transformer" model. These pretrained models can be fine-tuned on specific translation tasks, saving significant training time and resources.
Transfer Learning for Text Using TensorFlow
Transfer learning is a powerful technique in machine learning that allows models trained on one task to be repurposed and applied to another related task. In the context of natural language processing (NLP) and text data, transfer learning can be highly beneficial for improving model performance, especially when labeled data for the target task is limited.
Here are some key points about Transfer Learning for Text using TensorFlow:
-
Pretrained Language Models:
TensorFlow NLP offers access to pretrained language models, such as BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pretrained Transformer), and others. These models are trained on large corpora and capture rich contextual information from text, making them highly valuable for transfer learning tasks. -
Feature Extraction:
Transfer learning in text often involves using pretrained models to extract meaningful features from text data. TensorFlow provides APIs and utilities to load and leverage pretrained language models for feature extraction, enabling the reuse of learned representations.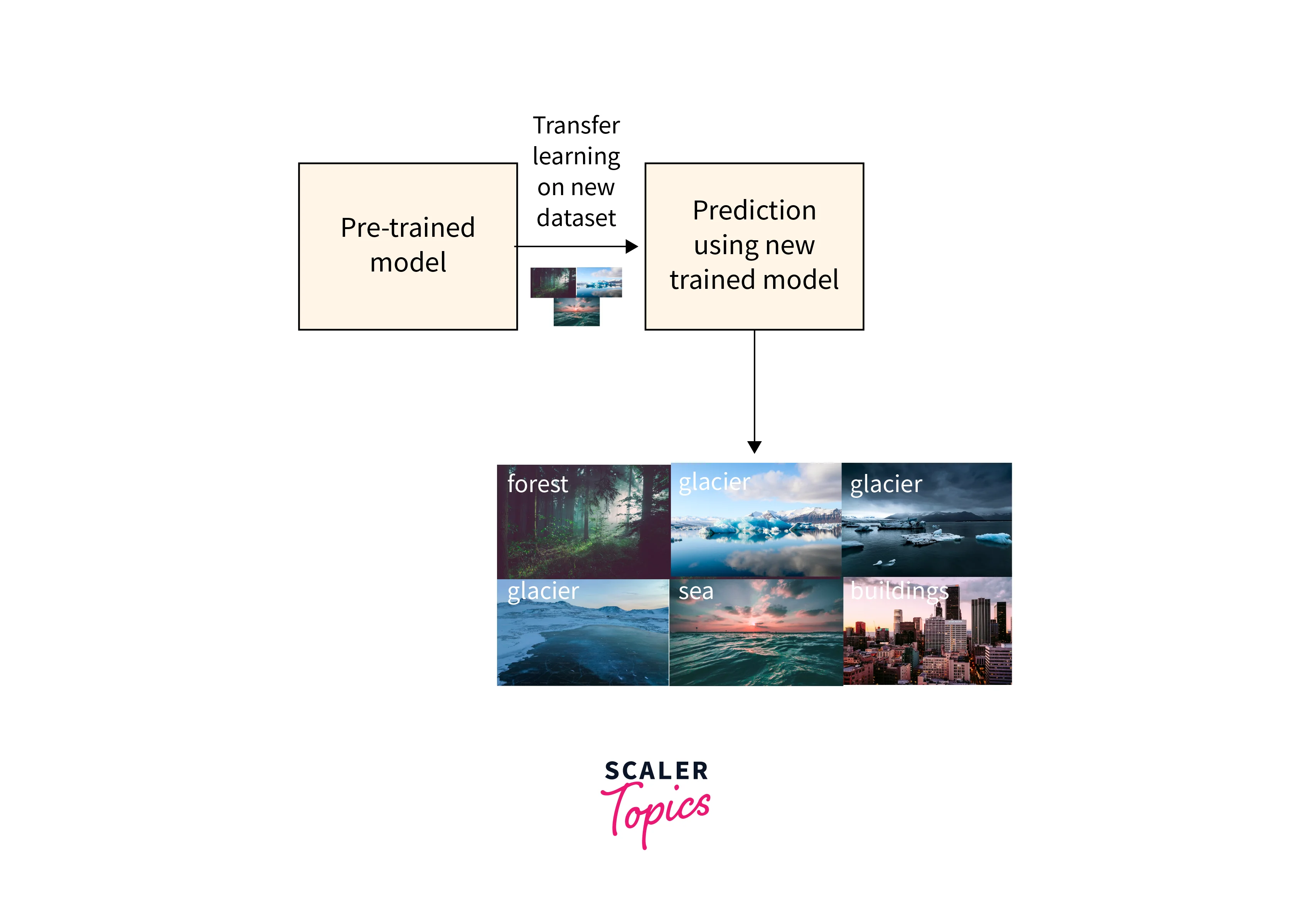
-
Fine-tuning:
Fine-tuning is a transfer learning technique where a pretrained model is further trained on a specific target task or domain. TensorFlow NLP allows fine-tuning of pretrained language models by updating the model's parameters using task-specific data. Fine-tuning helps the model adapt to the nuances of the target task, leading to improved performance. -
Text Classification:
Transfer learning can be applied to text classification tasks, such as sentiment analysis, spam detection, or topic classification. By utilizing a pretrained language model and fine-tuning it on the target classification task, TensorFlow enables leveraging the knowledge captured in the pretrained model for improved classification accuracy.
-
Named Entity Recognition (NER):
NER is the task of identifying and classifying named entities (e.g., names of people, organizations, locations) in text. Transfer learning can be employed in NER tasks using pretrained models. TensorFlow provides the flexibility to fine-tune the pretrained models specifically for NER, resulting in better entity recognition performance. -
Text Generation:
Transfer learning can also be beneficial for text generation tasks, such as language modeling or story generation. Pretrained language models in TensorFlow NLP can be used as the base model for generating text by providing initial seed input and conditioning the model to produce coherent and contextually relevant output. -
Data Augmentation:
Transfer learning can also be applied to augment the training data for text tasks. By utilizing pretrained models, TensorFlow allows generating of synthetic or augmented data by leveraging the language model's ability to generate plausible text samples, leading to better generalization and performance on the target task.
Conclusion
- With TensorFlow, we learned how to figure out the feelings hidden in the text. This helps us understand what people are saying, whether they're happy, sad, or something else.
- We also explored how to spot important things in text, like names, dates, and places. This is super useful for getting key details from a bunch of words.
- TensorFlow showed us how to make computers write text that sounds like a human. We can use this to make chatbots talk, help us write stories, or even make social media posts.
- We discovered how to translate words and sentences from one language to another. This means we can talk to people from different parts of the world, even if we don't know their language.