Object Detection Using TensorFlow
Overview
Object detection, is a crucial computer vision task that enables machines to identify and locate multiple objects within images and videos. We will explore the powerful TensorFlow Object Detection framework and its API, which provides pre-built models and tools to facilitate Tensorflow object detection tasks. We will explore two popular algorithms: Single-shot Object Detection (SSD) and Region-based Object Detection (RCNN), understanding their architecture, mechanics, and trade-offs. By this end, you will have the knowledge and expertise to unleash the potential of visual recognition in your projects using Tensorflow Object Detection.
What is Object Detection?
Object detection goes beyond image classification, allowing machines to locate and identify multiple objects in images and videos precisely. It goes beyond simple image classification, where the goal is to assign a single label to an entire image. We'll explore its significance, real-world applications, and how it enhances computer vision tasks.
Object detection is a computer vision task that involves identifying and localizing objects within an image or video. It is a crucial component in various applications, such as autonomous vehicles, surveillance systems, and image analysis.
The object detection process consists of two key steps:
-
Object Localization:
In this step, the algorithm identifies the bounding boxes that enclose the objects present in the image. Each bounding box represents the position and size of an object. Object localization determines where the objects are located within the image. -
Object Classification:
After localizing the objects, the algorithm assigns a class label to each bounding box, identifying the type of object it represents. For example, if the object is a car, a pedestrian, or a traffic sign.
What is the TensorFlow Object Detection API?
The TensorFlow Object Detection API is a powerful and user-friendly toolkit provided by Google's TensorFlow library, enabling developers and researchers to perform object detection tasks with ease. It simplifies the process of building and deploying object detection models, making it accessible to a broader audience.
Key Features and Components of TensorFlow Object Detection API:
-
Pre-Trained Models:
The API offers a selection of pre-trained models with different architectures and complexities. These models are trained on large datasets, such as COCO (Common Objects in Context) and Open Images, making them suitable for a wide range of object detection tasks. -
Flexibility and Customization:
Developers can fine-tune pre-trained models on their own datasets to adapt them to specific use cases. The API provides flexibility in choosing model architectures and hyperparameters, allowing users to strike the right balance between accuracy and inference speed. -
Single-shot Object Detection (SSD):
SSD is a popular object detection algorithm that efficiently performs both object localization and classification in a single pass. It's known for its real-time processing capabilities, making it suitable for applications where speed is essential. -
Region-based Object Detection (RCNN):
RCNN-based models, such as Faster R-CNN and Mask R-CNN, are another class of object detection algorithms. They use region proposal techniques to identify potential object regions, which are then classified and refined. These models generally provide higher accuracy at the cost of increased inference time. -
Training and Evaluation:
The API provides tools for data preparation, model training, and evaluation. Users can prepare their datasets in the required format, leverage transfer learning with pre-trained models, and evaluate model performance on validation sets.
What is Single-shot object detection (SSD)?
Single-shot Object Detection (SSD) is a state-of-the-art algorithm for object detection in computer vision. It is one of the most efficient and accurate approaches, enabling real-time object detection in images and videos.
The main characteristics and features that make SSD unique are :
- One-stage Detection (both localization and classification):
SSD performs both object localization (determining the bounding box coordinates) and object classification (assigning class labels) in a single forward pass through the network. This is in contrast to two-stage approaches like RCNN, which involve region proposal and object classification in separate steps. The one-stage design of SSD makes it more efficient and faster, especially for real-time applications. - Multi-scale Feature Maps:
SSD uses a set of convolutional feature maps at multiple scales to detect objects of various sizes in the image. These feature maps capture different levels of detail, allowing the model to detect both small and large objects effectively. The use of multi-scale feature maps enables SSD to handle objects of different scales without the need for explicit image pyramids. - Feature Fusion:
SSD utilizes feature fusion techniques to combine information from different layers of the network. It allows the model to capture both low-level details and high-level semantic information, leading to improved detection performance. Feature fusion enhances the model's ability to recognize objects in complex scenes and cluttered backgrounds. - Scalability:
SSD is highly scalable and can be adapted to detect different numbers of objects per image by modifying the number of anchor boxes and feature maps. The flexibility to adjust the number of anchor boxes enables SSD to handle object detection tasks with varying levels of complexity.
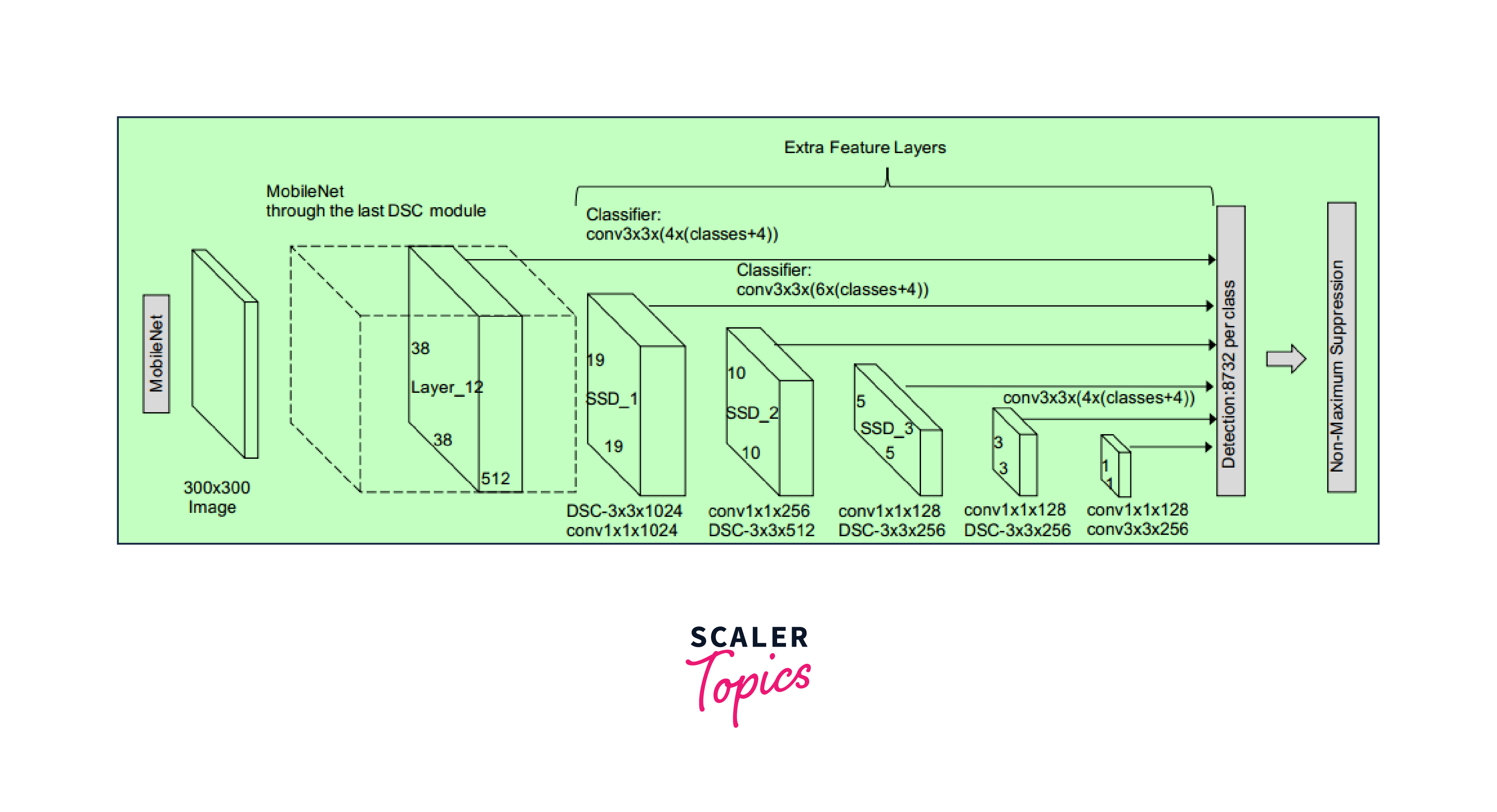
The above image has the mobilenet as the backbone but our example contains simple Convolutional Neural Network Architecture.
What is Region-based object detection (RCNN)?
Region-based Object Detection (RCNN) is an earlier approach that combines classical region proposal techniques with deep learning. It is a seminal algorithm in computer vision known for its accuracy and robustness in object detection tasks.
Key Features of SSD:
- One-Stage Detection:
Unlike two-stage detectors like Faster R-CNN, SSD directly predicts object bounding boxes and class scores without proposing region candidates. This simplifies the pipeline, resulting in faster inference. - Multi-scale Feature Maps:
SSD uses feature maps from multiple layers of a deep neural network to detect objects of different sizes. This allows it to handle objects at various scales effectively. - Feature Fusion:
SSD fuses information from different layers of the network to improve the detection performance. It combines feature maps from different resolutions to capture both fine-grained and context information. - Scalability:
SSD is highly scalable and can be adapted to detect objects at different scales and aspect ratios by adjusting the default anchor boxes used for localization.
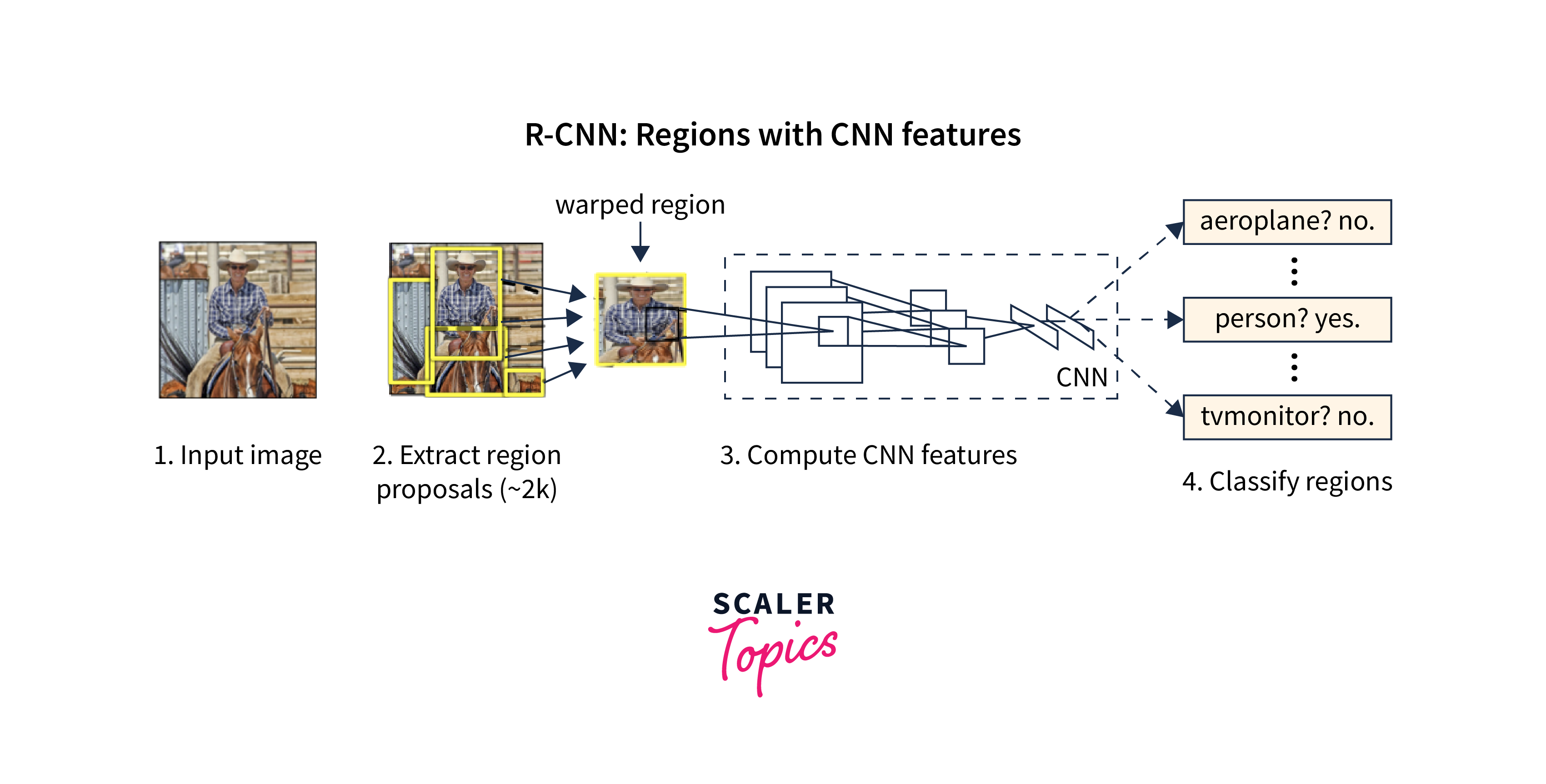
Applications of SSD:
It is most widely used in Autonomous Vehicles, Surveillance Systems, Retail and Inventory Management, Industrial Automation, Healthcare, Augmented Reality etc
Real-Time Object detection using TensorFlow
Real-Time Object Detection using TensorFlow is a cutting-edge computer vision application that enables real-time detection and localization of objects in images and videos. As a powerful deep learning framework, TensorFlow provides the tools and resources to build efficient and accurate object detection models that can process video streams and provide instant results.
Real-time object detection using TensorFlow opens up a world of possibilities for real-time applications in various industries. Developers and researchers can create highly efficient and accurate real-time object detection systems by understanding the key techniques and optimizations.

Face detection and recognition are perhaps the most widely used applications of computer vision. Every time you upload a picture on Facebook, Instagram or Google Photos, it automatically detects the people in the images. This is the power of computer vision at work.
Implementing Object Detection Models in TensorFlow
Implementing object detection models in TensorFlow is a comprehensive and exciting journey that involves building powerful deep-learning models to detect and localize objects within images and videos.
Before that, we should confirm the basic requirements like:
Step 1: Understanding the Key Components of Object Detection:
Before diving into the implementation, it's essential to understand the fundamental components of object detection, such as bounding boxes, class labels, and non-maximum suppression (NMS). Bounding boxes represent the location and size of detected objects. Class labels specify the type of object each bounding box corresponds to. NMS is a post-processing technique used to remove duplicate or overlapping bounding boxes and retain the most confident ones.
Step 2: TensorFlow Object Detection API:
The TensorFlow Object Detection API is a powerful framework that simplifies the process of building and training object detection models. It provides pre-built models, utilities, and tools to streamline the implementation process.
Step 3: Dataset Preparation and Annotation:
Prepare your dataset with labeled images and annotations. Annotations should contain the class labels and bounding box coordinates for each object in the images. You can use annotation tools like LabelImg to create annotations in the PASCAL VOC or COCO formats.
Step 4: Model Selection and Architecture:
Choose a pre-trained object detection model from TensorFlow's model zoo that best fits your task. The model zoo offers a variety of architectures with different trade-offs between speed and accuracy. Select a model that suits your specific requirements.
Step 5: Model Training and Optimization:
Fine-tune the selected pre-trained model on your custom dataset to adapt it to your specific object detection task. Train the model using the TensorFlow Object Detection API, setting up the training pipeline and specifying hyperparameters like learning rate, batch size, and number of training steps.
Step 6: Evaluation and Metrics:
After training, evaluate the model's performance on a separate evaluation dataset using metrics like mean Average Precision (mAP) and Precision-Recall curves. This helps assess the model's accuracy and generalization capability.
Step 7: Fine-Tuning and Hyperparameter Tuning:
Based on the evaluation results, fine-tune the model and experiment with hyperparameter tuning to achieve better performance.
Step 8: Exporting the Trained Model:
Export the trained model in TensorFlow's SavedModel format or convert it to TensorFlow Lite format for deployment on mobile and edge devices.
Step 9: Inference and Visualization:
Load the exported model and run inference on new images or videos to detect and localize objects. Visualize the results with bounding boxes and class labels to verify the model's performance.
Step 10: Deployment and Integration:
Deploy the trained and optimized model in your desired environment, such as a web application, mobile app, or edge device. Integrate the object detection model into your application to enable real-time detection.

Object Detection Using TensorFlow
Object detection Using Tensorflow is a critical computer vision task that allows machines to identify and localize objects within images, enabling them to recognize objects and pinpoint their locations. We will explore implementing object detection using TensorFlow, a powerful deep-learning framework. We'll use the popular Fashion MNIST dataset to demonstrate the step-by-step process, from importing libraries and setting up TensorFlow, Preparing Data, Tuning the Model, Evaluating analysis of the model, fine-tuning the model and making real-time predictions. So, let's get started with the implementation!
Step 1: Imports
Start by importing the necessary libraries and dependencies to lay the foundation for our object detection project. We'll import TensorFlow, NumPy, Matplotlib, and other essential libraries.
Step 2: Setting up TensorFlow
In this section, we'll guide you through the installation and configuration of TensorFlow to ensure a seamless development environment.
Step 3: Data Preparation
Preparing the dataset is crucial for any machine learning project. We'll use the Fashion MNIST dataset, which consists of images of various clothing items.
Step 4: Model Training
Now, let's build and train our object detection model. We'll use a simple convolutional neural network (CNN) for image classification.
Output

Step 5: Model Evaluation and Analysis
This section evaluates the model's performance and analyzes the training and validation results.
Step 6: Fine-tuning the Model
We can fine-tune the model by adjusting hyperparameters or adding more layers to enhance its accuracy.
Add the above code inside the tf.keras.Sequential() in the dense layer section. Add if it is necessary and when you tend to improve the model.
Step 7: Inference and Prediction
Finally, we'll perform real-time predictions using the trained model and visualize the results.
The above image shows inference on a test image by running the given epoch and the test accuracy Ouput
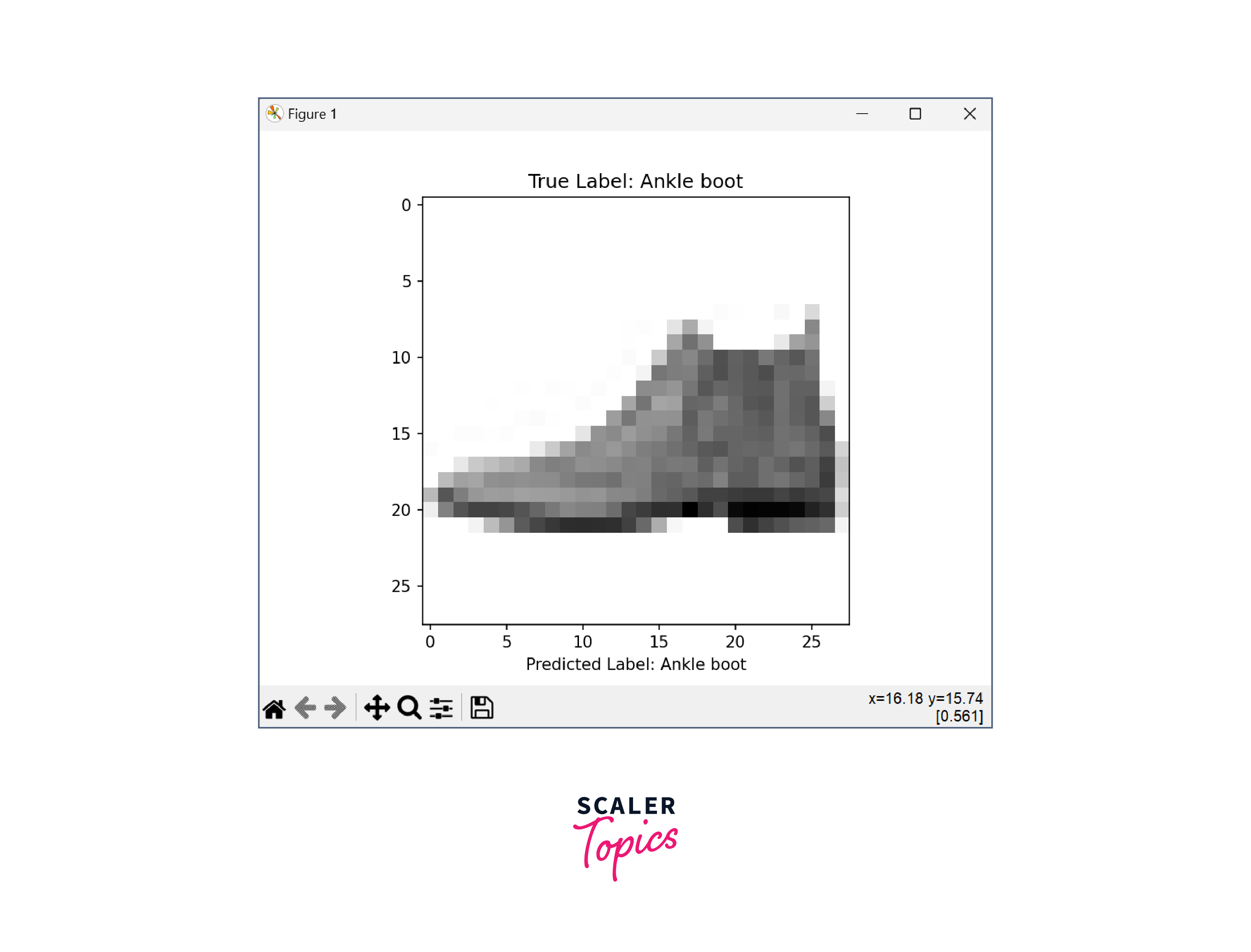
Above images provide the predicted label as the Ankle boot
This code includes the necessary steps for importing libraries, loading and preprocessing the Fashion MNIST dataset, defining and training the object detection model, evaluating its performance, and making real-time predictions on a test image from the dataset. The code uses a simple convolutional neural network (CNN) architecture for image classification with ten output classes corresponding to the ten fashion items in the dataset.
Conclusion
- Object Detection Significance:
Object detection is a critical computer vision task that goes beyond image classification, allowing machines to precisely locate and identify multiple objects within images or videos. - TensorFlow Object Detection API:
The TensorFlow Object Detection API provides a powerful framework with pre-built models and tools to simplify the development of object detection systems.- Single-shot Object Detection (SSD):
SSD is a fast and efficient algorithm for real-time object detection, performing both localization and classification in a single forward pass. - Region-based Object Detection (RCNN):
RCNN is an accurate and robust two-stage approach for object detection, leveraging region proposals and class-specific models.
- Single-shot Object Detection (SSD):
- Real-Time Object Detection:
Real-time object detection requires optimizations in model architecture, inference speed, and hardware utilization to achieve low-latency performance.- Fashion MNIST Example:
Demonstrating object detection using the Fashion MNIST dataset helps in understanding the implementation process with practical code examples. - Model Training and Fine-Tuning:
Training object detection models involves fine-tuning hyperparameters, selecting model architectures, and leveraging transfer learning for optimal performance.
- Fashion MNIST Example:
- Evaluation Metrics:
Object detection models are evaluated using metrics such as mAP (mean Average Precision) and IoU (Intersection over Union) to quantify their accuracy and localization abilities.- Inference and Prediction:
Real-time predictions are performed using trained models, enabling the model to detect objects on new data.
- Inference and Prediction: