Fine-Tuning Pretrained Models
Overview
In the rapidly evolving field of artificial intelligence and machine learning, pretrained models have gained significant attention and importance. These models, trained on vast amounts of data and fine-tuned for specific tasks, have become powerful tools for various applications in natural language processing, computer vision, and more. Fine-tuning pretrained models allows researchers and practitioners to customize these models for their specific needs and achieve higher performance on their specific tasks. In this blog, we will explore the concept of fine-tuning pretrained models, their techniques, challenges, and their relevance in AI and machine learning.
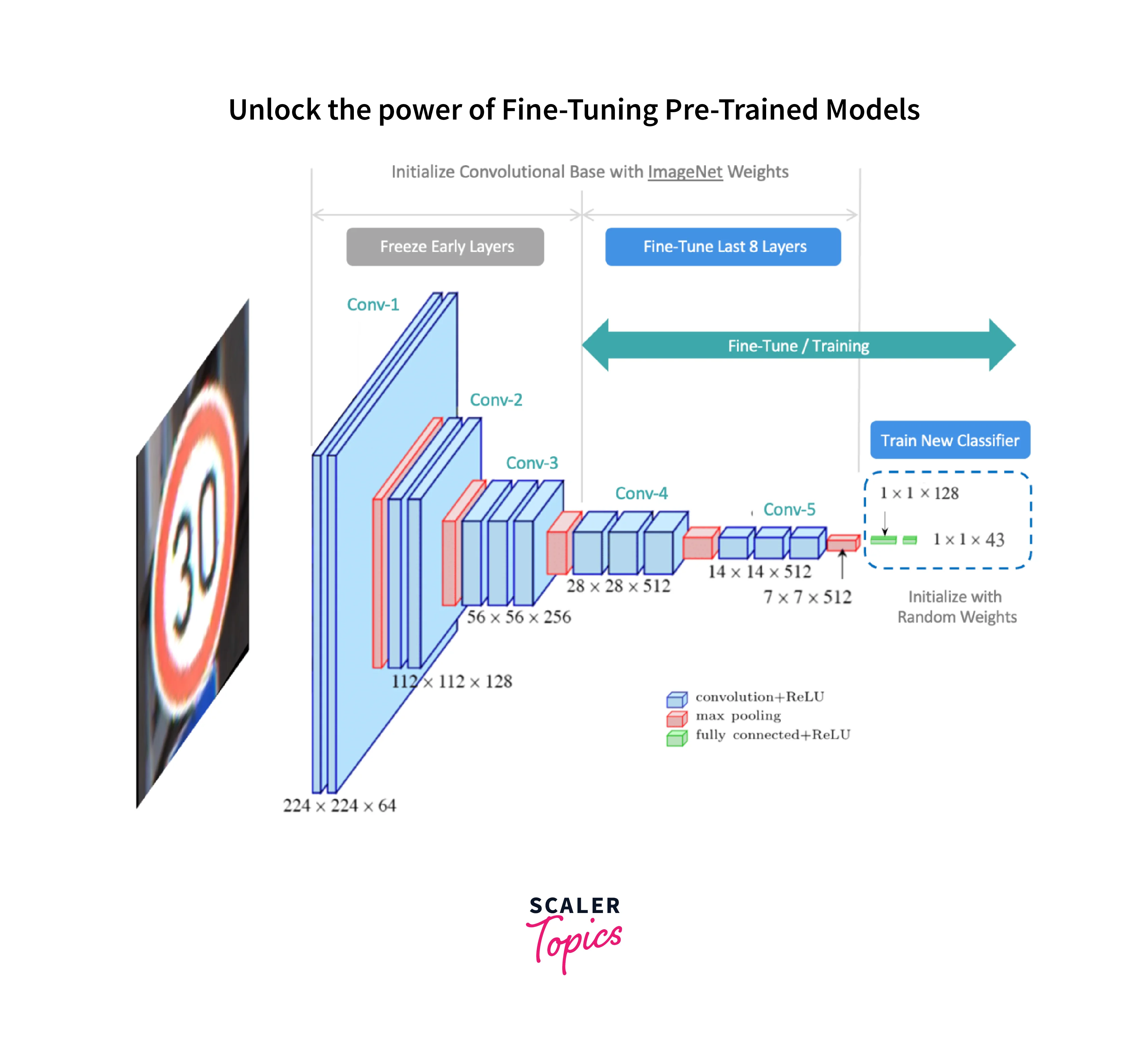
What is Transfer Learning
Transfer learning is a widely used technique in the field of machine learning which leverages the knowledge gained from pre-trained models to solve new and different but related tasks. Instead of starting the training process from scratch, transfer learning allows researchers to use the already learned representations and features from a pretrained model to improve the performance of a new model.
A pretrained model is first trained on a large dataset in transfer learning. This initial training phase helps the model learn general patterns and features that are transferable across different tasks. These pretrained models often come from popular architectures such as VGGNet, ResNet, or BERT, which have been pretrained on massive datasets like ImageNet or Wikipedia.
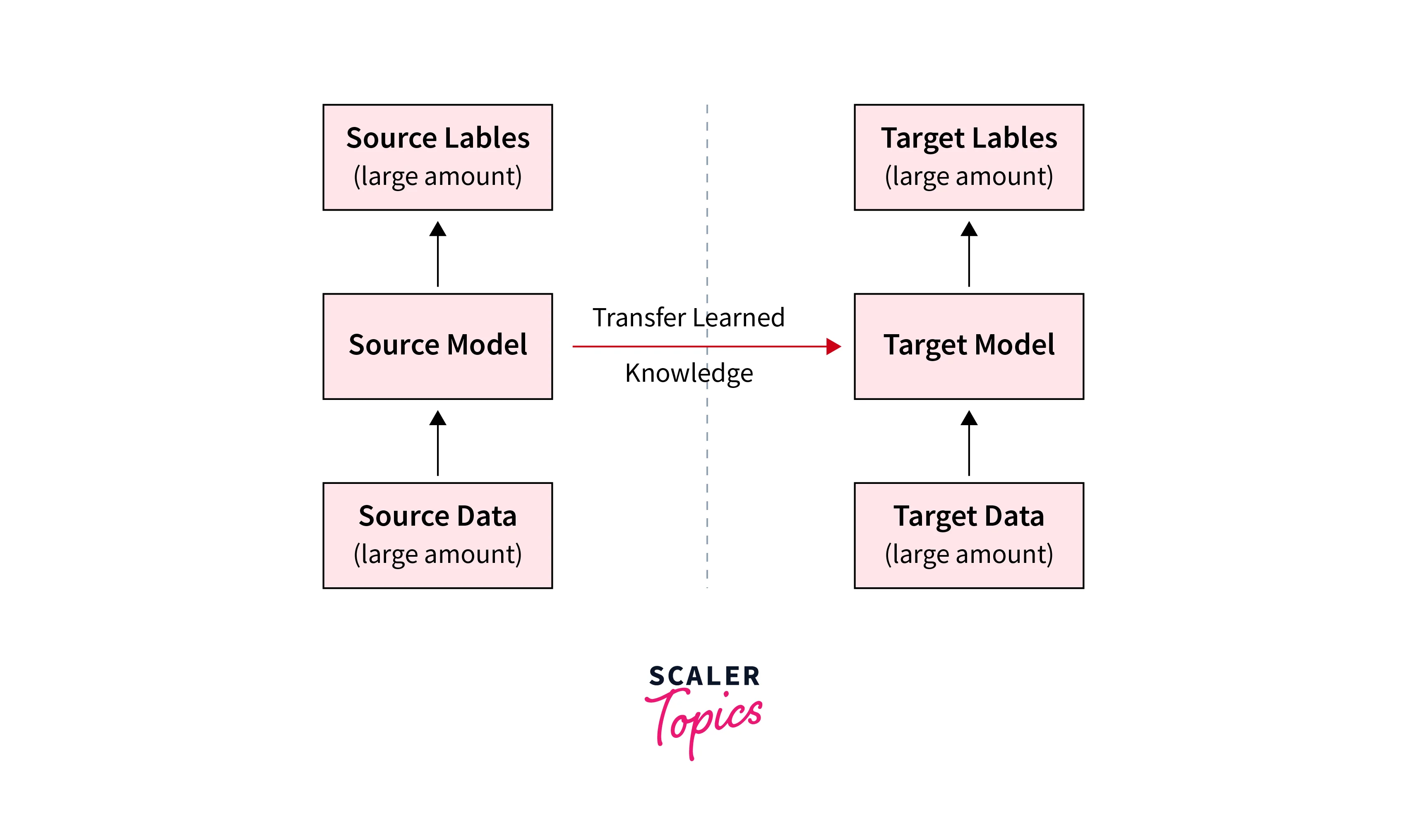
Once the pretrained model is trained, it undergoes a process called fine-tuning, where the model's weights and parameters are adjusted to adapt to the specific task. Fine-tuning involves freezing some layers of the pretrained model to retain the learned knowledge and adding new task-specific layers. These new layers enable the model to learn and specialize for the specific target task while leveraging the general knowledge learned from the pretrained model.
-
Advantages of Transfer Learning
a) Firstly, it reduces the required training data and time, as the model doesn't have to be trained from scratch. The pre-trained model has already learned relevant features and representations, which can significantly speed up the training process for the new task. This is especially beneficial when working with limited resources or small datasets.
b) Secondly, transfer learning improves generalization and reduces the risk of overfitting. Pretrained models have learned representations from large-scale datasets, effectively capturing general patterns. By leveraging these learned representations, the model can extract valuable features and generalize better to unseen data for the new task.
Transfer learning is particularly useful when training data is scarce or in cases where the training data is significantly different from the target task. For example, suppose a model is trained on a large dataset of images. It can leverage this knowledge to perform well on a new image classification task even with limited training data.
However, there are some considerations when using transfer learning. The choice of the pre-trained model architecture should be carefully evaluated based on the similarities between the pretrained and target tasks. Suppose the pretrained model is trained on a completely different domain. In that case, the transfer of knowledge may not be effective, and it may be necessary to choose a different pretrained model or perform more extensive fine-tuning.
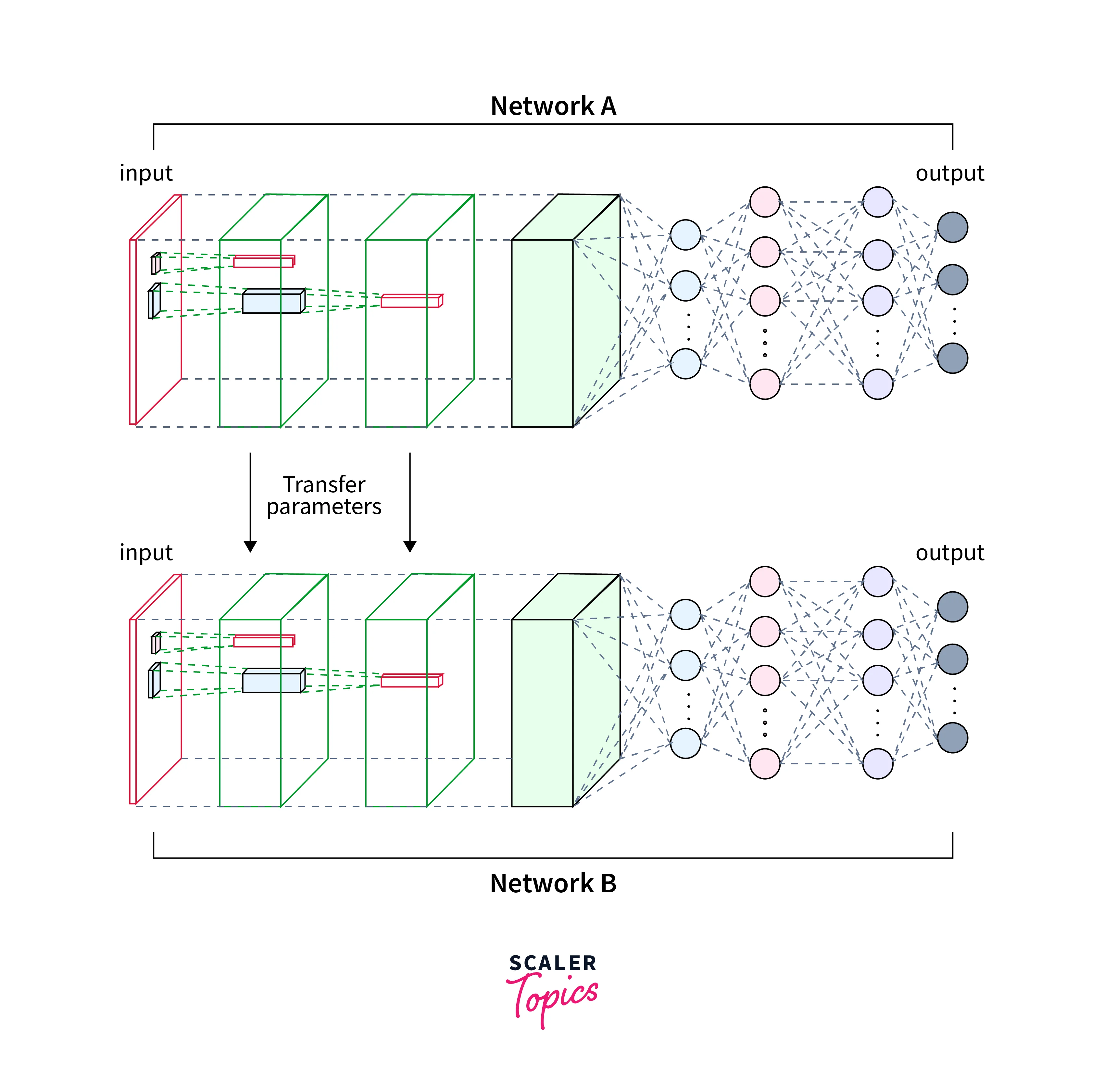
Transfer learning also requires thoughtful selection of which layers to freeze and which to fine-tune. Freezing too many layers may not allow the model to adapt to the target task while fine-tuning too many layers may lead to overfitting. It is important to find the right balance to achieve optimal performance.
Pretrained Models and Datasets
Pretrained models and datasets play a crucial role in the success of transfer learning. A pretrained model is trained on a large dataset for a specific task, such as image classification or natural language processing. These pretrained models have already learned relevant patterns and features from the data, making them valuable for transfer learning.
One of the most popular pretrained model architectures is VGGNet, which has achieved impressive results on the ImageNet dataset. VGGNet has learned to recognize various objects and features in images, making it a powerful tool for image-related tasks. Another widely used pretrained model is ResNet, which has also been trained on ImageNet. ResNet can capture features at different network depths, allowing for more efficient learning and improved performance.

For natural language processing tasks, pretrained models like BERT (Bidirectional Encoder Representations from Transformers) have gained significant attention. BERT has been pretrained on a large corpus of text data, such as Wikipedia, and can generate powerful word embeddings. These word embeddings capture the semantic meaning of words and their relationships, enabling the model to understand the context and generate accurate predictions for downstream tasks like text classification or sentiment analysis.
Alongside pretrained models, pretrained datasets play a critical role in transfer learning. Pretrained datasets, such as ImageNet or Wikipedia, have been extensively labeled and provide a wealth of data for training models. These datasets encompass various categories and concepts, capturing diverse patterns that can benefit transfer learning.
The choice of pretrained model architecture and pretrained dataset depends on the target task and the availability of relevant data. If the task is related to image classification, using VGGNet or ResNet pretrained on ImageNet can provide a solid foundation. Conversely, leveraging BERT pretrained on a large text corpus may yield better results if the task involves text analysis.
It is important to note that pretrained models and datasets are not one-size-fits-all solutions. Knowledge transfer from pretraining to the target task depends on the similarity between the two tasks and the data domains. Suppose the pretrained model is trained on a completely different task or domain. In that case, the transfer may not be effective, and it may be necessary to choose a different pretrained model or adapt the model through extensive fine-tuning.
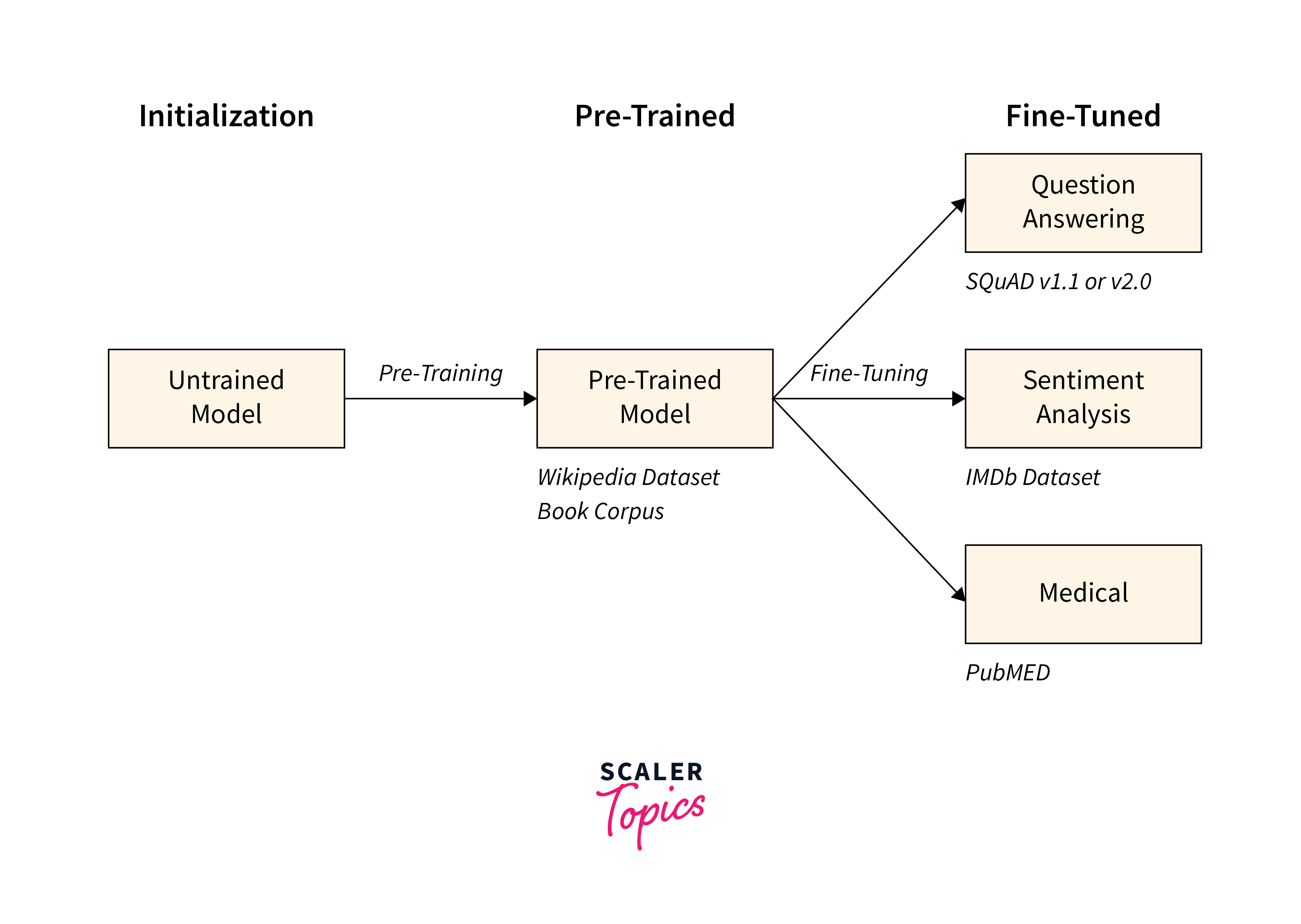
Fine-tuning the pretrained model with task-specific data is crucial to ensure optimal performance. By freezing some layers of the pretrained model and adding new task-specific layers, the model can adapt to the target task while leveraging the learned representations from pretraining. This process allows the model to specialize and improve performance on the specific task.
In conclusion, pretrained models and datasets are valuable resources in transfer learning. They provide a foundation of learned representations and features that can be leveraged to improve performance on new tasks. By understanding the principles and considerations behind choosing the right pretrained models and datasets, researchers, and practitioners can enhance the efficiency and effectiveness of their transfer learning projects.
What is Fine-Tuning?
Fine-tuning is a technique used in machine learning and deep learning to adapt a pretrained model to a specific task or domain. It involves taking a pretrained model trained on a large dataset for a general task and customizing it for a more specific task or dataset. When a pretrained model is fine-tuned, some model layers are frozen, meaning their weights and parameters are kept fixed and not updated during training. This allows the model to retain the learned representations and features from the pretrained model. New task-specific layers are then added to the frozen layers, which are trained using task-specific data.
The fine-tuning process allows the pretrained model to adapt to the target task or domain by leveraging the knowledge and patterns learned from pretraining. By using pretrained models as a starting point, the model benefits from the general knowledge captured by the pretrained model while focusing on learning the specific features and patterns relevant to the new task.
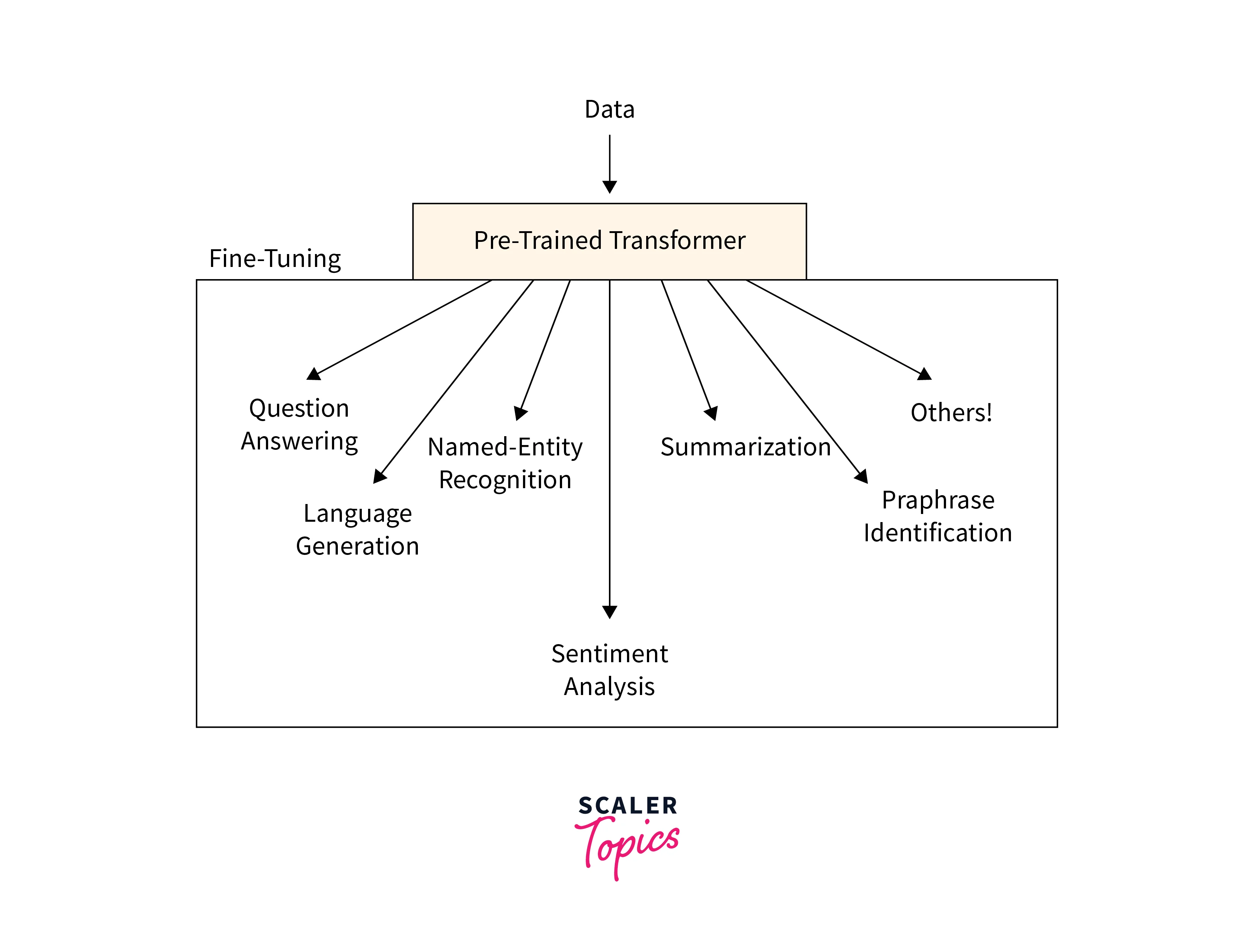
Fine-tuning is particularly useful when the amount of task-specific data is limited. By starting with a pretrained model, which has already been learned from a large dataset, the model can overcome the limitations of small task-specific datasets and achieve better performance on the target task. However, it is important to note that fine-tuning is not a one-size-fits-all solution. The success of fine-tuning depends on the similarity between the pretrained task and the target task, as well as the domains of the data. Suppose the pretrained model is trained on a completely different task or domain. In that case, the transfer may not be effective, and it may be necessary to choose a different pretrained model or adapt the model through extensive fine-tuning.
For instance, let's consider the popular VGG16 architecture pretrained on the ImageNet dataset. We can load this model using a deep learning library like TensorFlow or PyTorch:
Additionally, the process of fine-tuning requires careful consideration and experimentation. The frozen layers and the architecture of the new task-specific layers need to be determined based on the specific task and dataset. Hyperparameters, such as learning rate and regularization, also need to be carefully tuned to achieve optimal performance.
Fine-Tuning Workflow
Fine-tuning is a crucial step in harnessing pretrained models for your projects. In this section, we will explore the fine-tuning workflow, an essential aspect that can significantly impact the success of your project.
-
Step 1: Choose a Pretrained Model:
The foundation of fine-tuning lies in selecting an appropriate pretrained model that aligns with your project's objectives. For instance, if your project involves sentiment analysis of movie reviews, you might opt for a model like BERT, renowned for its natural language understanding capabilities.
-
Step 2: Data Preparation:
Before diving into fine-tuning, meticulous data preparation is necessary. Let's assume our goal is sentiment analysis, and we have a collection of movie reviews along with their sentiment labels. To prepare the data, we perform tokenization to convert the text into a format the model understands.
-
Step 3: Load Pretrained Model:
Loading the pretrained model is a straightforward process. Customize the model's output layer to match the number of classes in your target task. We have two classes for our sentiment analysis example: positive and negative sentiment.
-
Step 4: Fine-tuning:
The heart of the fine-tuning process lies in iterating through your dataset in mini-batches, computing gradients, and updating the model's parameters. This process enhances the model's ability to understand the nuances of your specific task.
The fine-tuning workflow gracefully transforms pretrained models into powerful tools for your task. This elegant yet potent process encapsulates the essence of model adaptation.
Fine-tuning pretrained models is a dynamic technique that unlocks the potential of transfer learning, enabling you to tackle complex tasks efficiently. By carefully selecting models, preparing data, loading pretrained weights, and fine-tuning iteratively, you can tailor a model to your project's requirements and achieve remarkable results.
Training and Optimization
In the realm of fine-tuning pretrained models, training and optimization form the backbone of the process. This section will delve into the intricacies of training your model on task-specific data and optimizing its performance to achieve remarkable results. Let's embark on this journey of refining your model to its full potential.
Training involves exposing the model to task-specific data and optimising its parameters. In our sentiment analysis scenario, the following steps outline the training process:
-
Data Loader Setup:
Create a DataLoader to handle batches of data during training efficiently.
-
Optimizer Selection:
Choose an optimizer that suits your task. Common choices include SGD, Adam, and AdaGrad. Here, we'll use AdamW.
-
Fine-Tuning Loop:
Iterate through the data in mini-batches and perform the following steps:
a. Zero out the gradients to prevent accumulation from previous batches.
b. Pass the input data through the model to obtain predictions.
c. Compute the loss based on the predictions and target labels.
d. Backpropagate the loss to compute gradients.
e. Update the model's parameters using the chosen optimizer.
Optimization Techniques
Optimization techniques are pivotal to ensure your model converges efficiently and avoids pitfalls like overfitting. For fine-tuning, consider these strategies:
-
Learning Rate (LR):
Use a lower LR than usual to prevent drastic changes that could erase useful information encoded in the pretrained model.
-
Weight Decay:
Apply weight decay (L2 regularization) to prevent excessive reliance on a few features.
-
Learning Rate Scheduling:
Experiment with learning rate schedules that adjust the LR during training. Techniques like learning rate decay or warm-up can be beneficial.
Monitoring and Validation
While training, monitoring the model's performance to ensure it's learning effectively is essential. A common practice is to validate the model's performance on a separate validation dataset. For our sentiment analysis project, we can use validation data similar to our training data:
After each epoch, calculate the validation loss and monitor metrics like accuracy to prevent overfitting.
By preparing data, setting up training loops, selecting optimizers, and employing optimization techniques, you steer your model towards mastery of your specific task. Regular monitoring and validation allow you to fine-tune confidently, unlocking the model's full potential and achieving exceptional performance.
Handling Overfitting and Catastrophic Forgetting
Addressing overfitting and catastrophic forgetting becomes of paramount importance when it comes to the fine-tuning process. In this section, we'll explore these challenges in the context of sentiment analysis and provide code examples showcasing strategies to overcome them.
Understanding Overfitting
Overfitting can hinder a model's generalization to new data. Let's incorporate strategies into our sentiment analysis example to combat this challenge.
Strategies to Combat Overfitting
Regularization: Dropout Layer
Adding dropout layers introduces randomness during training, preventing the model from overfitting to the training data.
Understanding Catastrophic Forgetting
Catastrophic forgetting can occur during fine-tuning when the model loses knowledge acquired during the original task.
Strategies to Mitigate Catastrophic Forgetting
-
Replay Buffer
Implement a replay buffer to periodically train the model on samples from previous tasks, maintaining a balance between old and new knowledge.
Combining Strategies for Success
Integrating these strategies into your fine-tuning process can lead to remarkable results. By enhancing your model's resistance to overfitting and catastrophic forgetting, you ensure it adapts effectively to new tasks while retaining its acquired knowledge.
Stay tuned for the final section, where we'll unveil best practices for a seamless fine-tuning process that optimally leverages pretrained models.
Best Practices of Fine-Tuning
Fine-tuning pretrained models is an art that requires a blend of techniques, intuition, and systematic approaches. In this final section, we'll unravel the best practices to help you navigate the fine-tuning journey effectively. Let's dive into the strategies that ensure your model unlocks the full potential of transfer learning.
Understand Your Task
Before you embark on fine-tuning, immerse yourself in the specifics of your task. Understand the nuances, data distribution, and objectives of your project. This deep understanding will guide your choices in model selection, modifications, and evaluation metrics.
Start with Smaller Models
If computational resources are limited, consider beginning with smaller pretrained models before moving to larger, more complex ones. Smaller models train faster and can provide insights into whether your approach is heading in the right direction.
Monitor and Iterate
Continuous monitoring of your model's performance during fine-tuning is crucial. Monitor metrics such as loss, accuracy, and validation scores. If the model's performance plateaus or degrades, don't hesitate to iterate by adjusting hyperparameters or strategies.
Use Task-Specific Metrics
Choose evaluation metrics that align with your task's objectives. For example, if your sentiment analysis project involves imbalanced classes, accuracy might not be the best metric. Consider using precision, recall, or F1-score, which provide a more comprehensive view of performance.
Leverage Preprocessing Techniques
Preprocessing plays a vital role in fine-tuning success. Techniques like data augmentation, text cleaning, and careful handling of special characters can significantly improve the quality of your training data.
Experiment with Learning Rates
The learning rate is a critical hyperparameter that affects convergence and generalization. Experiment with different learning rates for different layers of the model. Lower learning rates for lower layers help retain the general knowledge, while higher rates for task-specific layers promote adaptation.
Gradual Unfreezing
A technique known as gradual unfreezing can enhance fine-tuning. Start by training only the top layers while keeping the lower layers frozen. Gradually unfreeze and fine-tune the lower layers as the training progresses. This approach ensures that the model remembers valuable knowledge during adaptation.
Regular Validation
Regularly validate your model on a separate dataset to ensure it's balanced. Validation helps you detect issues early and make necessary adjustments.
Embrace Transfer Learning Libraries
Leverage specialized libraries like Hugging Face Transformers, which provide easy access to pretrained models, data processing pipelines, and optimization tools. These libraries streamline the fine-tuning process and allow you to focus on model adaptation.
Conclusion
In machine learning, fine-tuning pretrained models is a game-changing approach that empowers us to achieve remarkable results with less effort. As we conclude our exploration of this transformative technique, let's recap the key takeaways.
-
Transfer Learning Revolution:
Fine-tuning allows us to leverage the wealth of knowledge stored in pretrained models, adapting them to our specific tasks. This approach accelerates model training and enhances performance.
-
Strategic Adaptation:
The fine-tuning workflow involves choosing a relevant pretrained model, preparing task-specific data, modifying model layers, and training iteratively. This strategic adaptation balances existing knowledge with new insights.
-
Challenges Addressed:
Overfitting and catastrophic forgetting are challenges inherent to fine-tuning. We can ensure a robust and adaptable model by employing strategies like regularization, data augmentation, replay buffers, and gradient scaling.
-
Best Practices Empower Success:
Understanding your task, starting with smaller models, continuous monitoring, task-specific metrics, and gradual unfreezing are among the best practices that guide a successful fine-tuning journey.
-
Endless Possibilities:
Fine-tuning is an art that empowers us to unlock the full potential of pretrained models. With careful experimentation, optimization, and strategic adaptation, we can create models that tackle diverse tasks excellently.
By embracing these insights and practices, you can confidently embark on your fine-tuning endeavors. As machine learning continues to evolve, your mastery of fine-tuning will be a valuable asset that propels you toward groundbreaking achievements.