TensorFlow Quantization
Overview
In the world of deep learning, model size and inference speed are critical factors for deployment on resource-constrained devices such as mobile phones and edge devices. TensorFlow Quantization addresses these challenges by optimizing deep learning models to be more efficient, making them suitable for deployment in real-world scenarios where computational resources are limited. This blog will provide a comprehensive guide to TensorFlow Quantization, exploring the concept of quantization, quantization-aware training, TensorFlow quantization tools, and how to deploy quantized models.
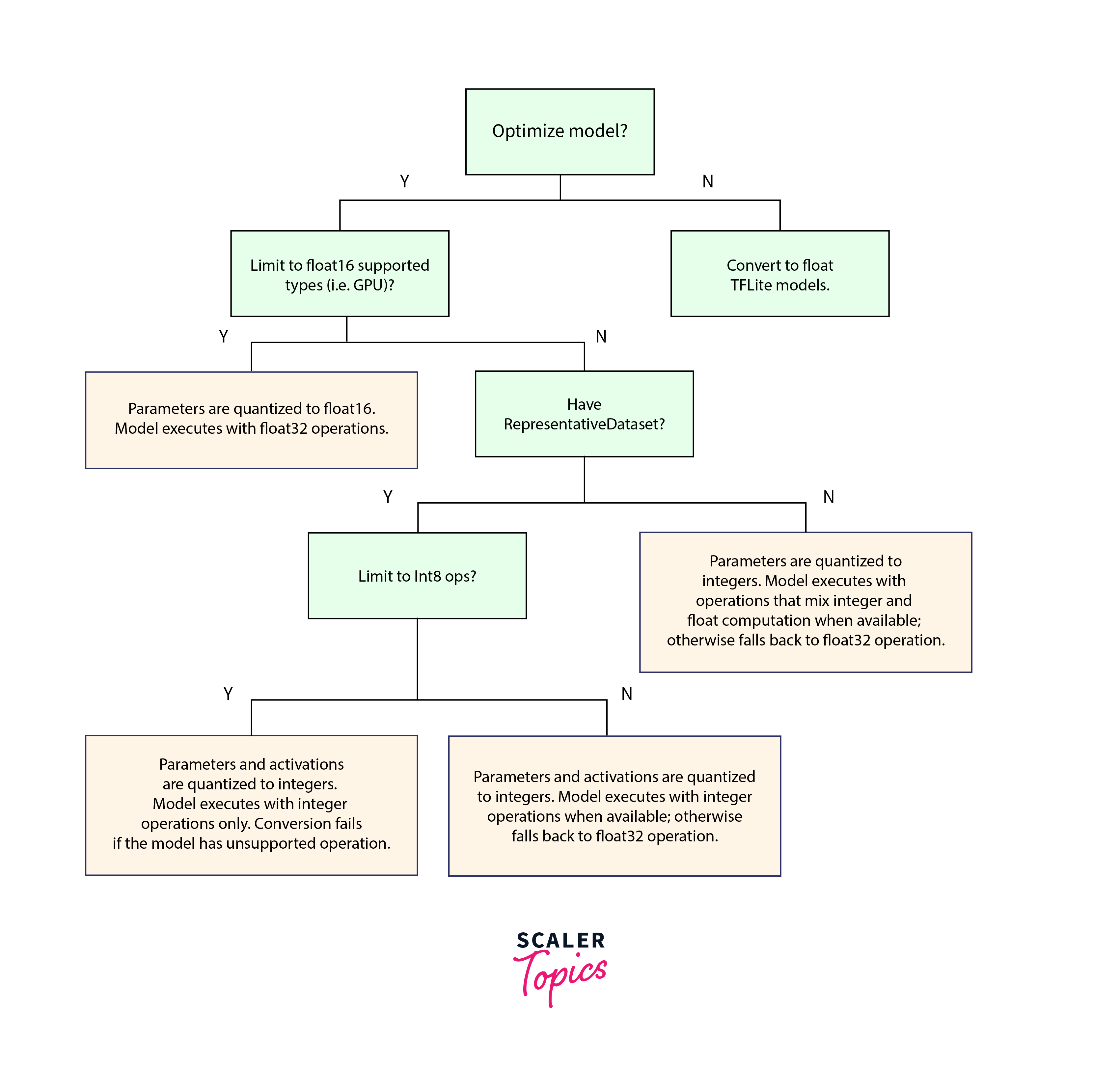
What is Quantization?
Quantization is a powerful optimization technique used by TensorFlow Lite (TFLite) to reduce the memory and computational cost of deep learning models. It involves downscaling the precision of the model parameters such as 32-bit floating-point numbers, with non floating-point integers, like 8-bit integers. This results in a significant reduction in model size without compromising too much on accuracy.
During model training, weights and biases are typically stored as 32-bit floating-point numbers to ensure high precision calculations. However, after training, these parameters can be converted to 8-bit integers or 16-bit floating-point numbers in the quantization process. This reduction in precision leads to a smaller model size, making it more suitable for deployment on resource-constrained devices like mobile phones.
Quantization is not limited to just weights and biases; activation values can also be quantized. However, quantizing activation values requires a calibration step to determine appropriate scaling parameters from a representative dataset.
Empirical studies have shown that quantizing models to 16-bit floating-point numbers usually results in a negligible impact on accuracy while reducing the model size by half. Similarly, full quantization, which involves quantizing both weights and activation values to 8-bit integers, can lead to a 4x reduction in model size with minimal loss in accuracy.
The following images demonstrate the effects of full quantization on model size, latency time, and accuracy, respectively, using experiments conducted on Google Android Pixel 2. These results highlight the benefits of quantization in optimizing deep learning models for efficient deployment on mobile and edge devices.
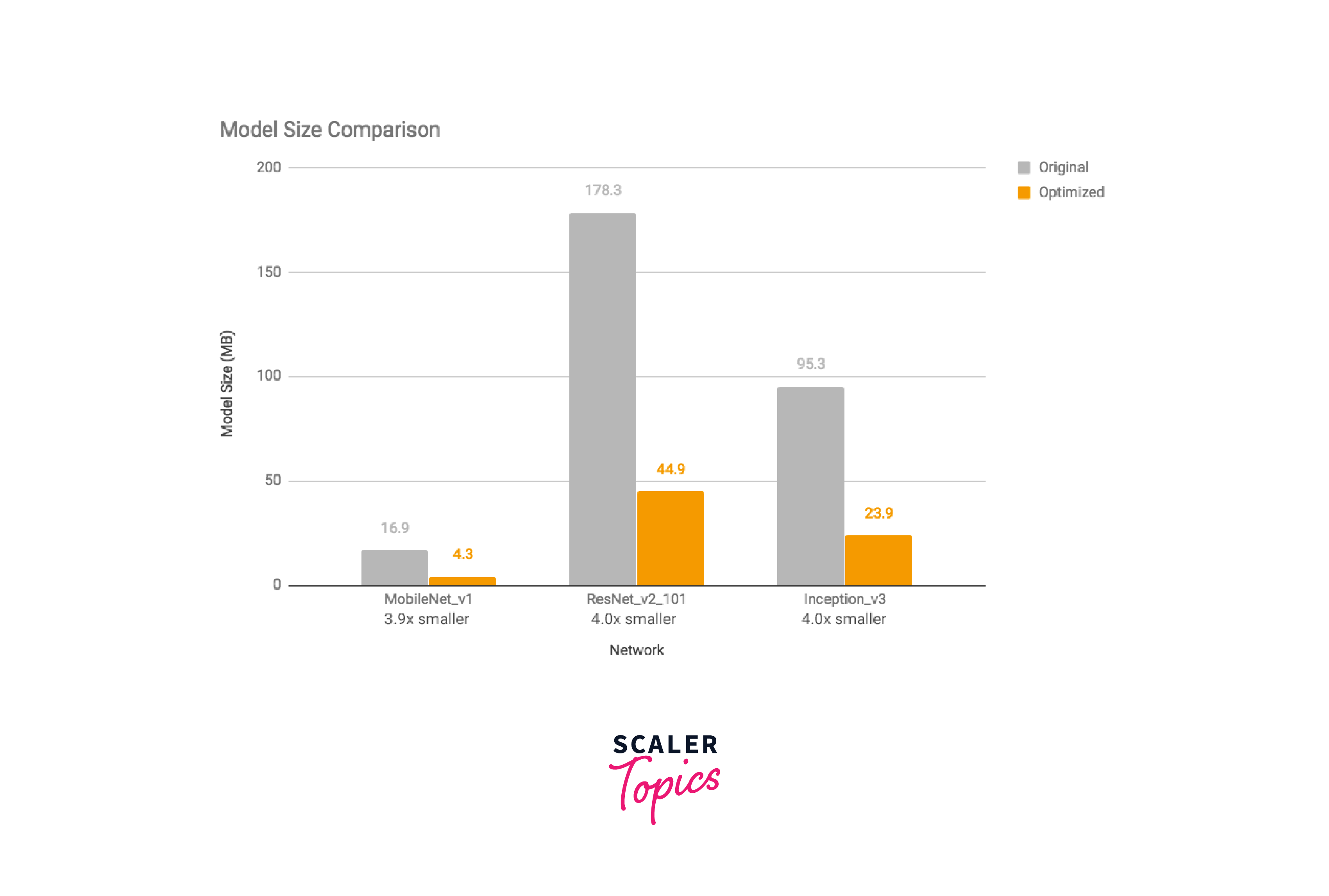
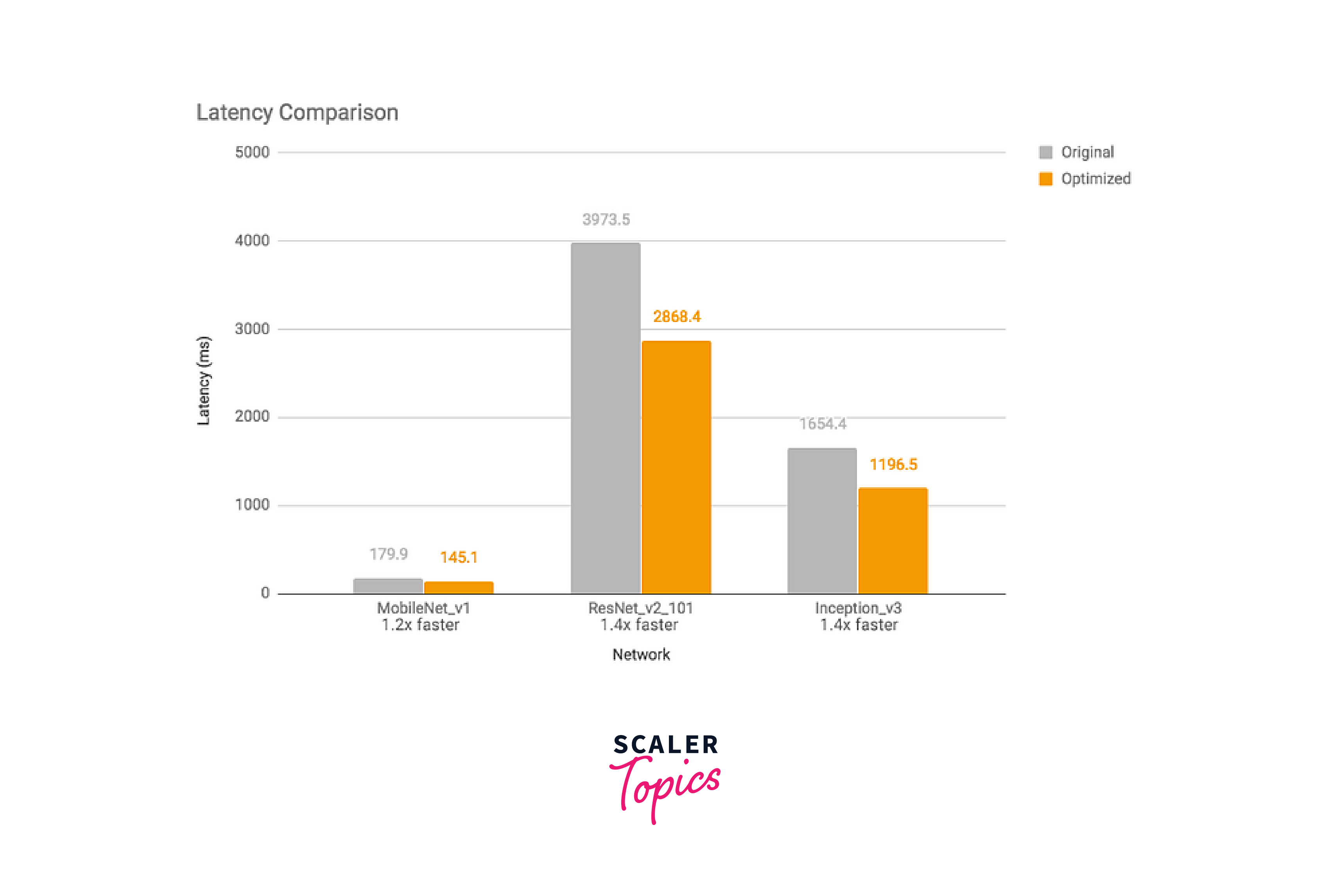
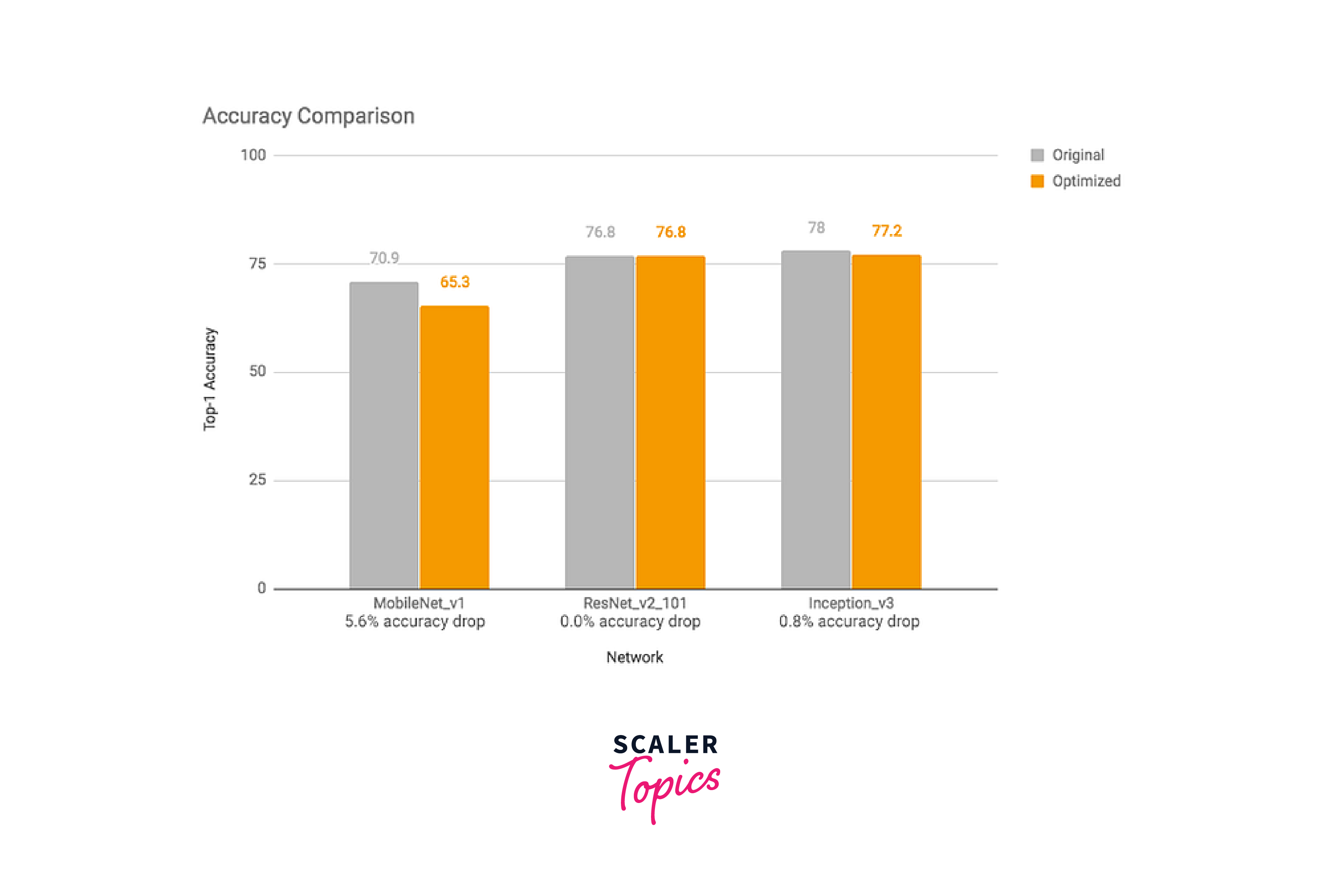
Types of Quantization
There are two main types of quantization used in deep learning:
- Post-Training Quantization:
Post-training quantization quantizes both the model's parameters and the activations during inference. This type of quantization further improves memory efficiency and inference speed, however it costs the accuracy of the model during inference. - Dynamic Range Quantiation:
Dynamic Range Quantization provides faster computation and reduced memory usage without a representative dataset for calibration. Dynamic Range Quantization strictly quantizes weights from float to 8-bit integer at conversion time. - Full Integer Quantization:
Full Integer Quantization requires a representative dataset for calibrate or estimate the range of all floating-point tensors in the model. - Float16 Quantization:
This type of Quantization involves conversion of model from float32 to 16-bit floating point numbers. This type of quantization has minimal loss in accuracy but it won't reduce much latency
What is Quantization-Aware Training?
Quantization aware training emulates inference-time quantization, creating a model that downstream tools will use to produce actually quantized models. The quantized models use lower-precision (e.g. 8-bit instead of 32-bit float), leading to benefits during deployment.
Instead of training the model using full precision, QAT introduces quantization during the training process, simulating the effects of quantization on model performance. By doing so, the model learns to be more robust to reduced precision and ensures that quantization does not significantly impact accuracy.
What are TensorFlow Quantization Tools?
TensorFlow offers a set of tools and APIs to facilitate the quantization process. Some of the essential TensorFlow quantization tools are:
-
Quantization-Aware Training API:
TensorFlow provides APIs to enable quantization-aware training. Developers can use these APIs to create quantization-aware models and train them with reduced precision. -
Post-Training Quantization Tools:
TensorFlow supports post-training quantization, where a pre-trained model is quantized after training. The TensorFlow Lite (TFLite) converter is a valuable tool for converting a floating-point model to a quantized model suitable for inference on edge devices. -
Quantization-Aware Autoencoders:
TensorFlow also offers quantization-aware autoencoders, which are neural network architectures specifically designed to learn compact representations of data suitable for quantization.
Quantizing Models with TFLite
TensorFlow Lite (TFLite) is a lightweight version of TensorFlow designed for mobile and edge devices. TFLite includes several tools to facilitate the quantization process and deploy quantized models efficiently. Let's explore the steps to quantize a model using TFLite:
-
Training the Model:
First, we need to train the model using standard training procedures in TensorFlow. -
Post-Training Quantization:
After training, we can quantize the model using TFLite's post-training quantization tools. This process converts the model's weights and activations from floating-point to 8-bit integers, reducing the model's memory footprint. -
Model Conversion:
The next step is to convert the quantized model to the TFLite format, optimized for inference on edge devices.
Here's an example of how to quantize a pre-trained model using TFLite:
Evaluate Quantized Models
After quantizing the model, it is crucial to evaluate its performance to ensure that the quantization process does not significantly impact accuracy. The quantized model should be tested on a representative test dataset to measure its accuracy and other relevant metrics.
Output:
Deployment and Integration
Once the quantized model is evaluated and deemed satisfactory in terms of accuracy and performance, it is ready for deployment. Deploying a quantized model typically involves integrating it into a larger application or service. For example, the quantized TFLite model can be embedded into a mobile app or used as part of an edge computing solution.
TensorFlow Lite offers a range of integration options, including direct C++ API integration for Android and iOS, TensorFlow Lite Task Library for specific ML tasks, and Edge TPU for optimized deployment on Google Coral devices.
Limitations and Future Developments
While quantization is an effective technique for optimizing deep learning models, it may not be suitable for all applications. Some models may be sensitive to reduced precision, leading to significant accuracy degradation. In such cases, advanced quantization methods and techniques may be necessary.
The field of model quantization is continually evolving, and researchers are actively working on developing more efficient quantization methods. Future developments may include improved post-training quantization techniques, support for quantizing more complex model architectures, and integration of quantization-aware training with transfer learning.
Conclusion
- TensorFlow Quantization is a powerful set of tools and techniques that enable the optimization of deep learning models for efficiency without compromising accuracy.
- By reducing the model's memory footprint and improving inference speed, quantized models become suitable for deployment on resource-constrained devices, making deep learning accessible to a broader range of applications.
- With TensorFlow's extensive quantization capabilities, developers and researchers can create and deploy efficient machine learning models that meet the demands of real-world scenarios.