TensorFlow Regularization
Overview
TensorFlow is an open-source machine learning framework developed by Google. It provides a comprehensive set of tools and libraries for building and deploying various machine learning models. TensorFlow supports a wide range of applications, including neural networks, deep learning, natural language processing, and computer vision. In this article we will learn more about Tensorflow Regularization techniques.
Introduction
Regularization is a technique used in machine learning to prevent overfitting, which occurs when a model becomes too complex and performs well on the training data but fails to generalize to new, unseen data. TensorFlow regularization provides different regularization techniques to help control the complexity of models.
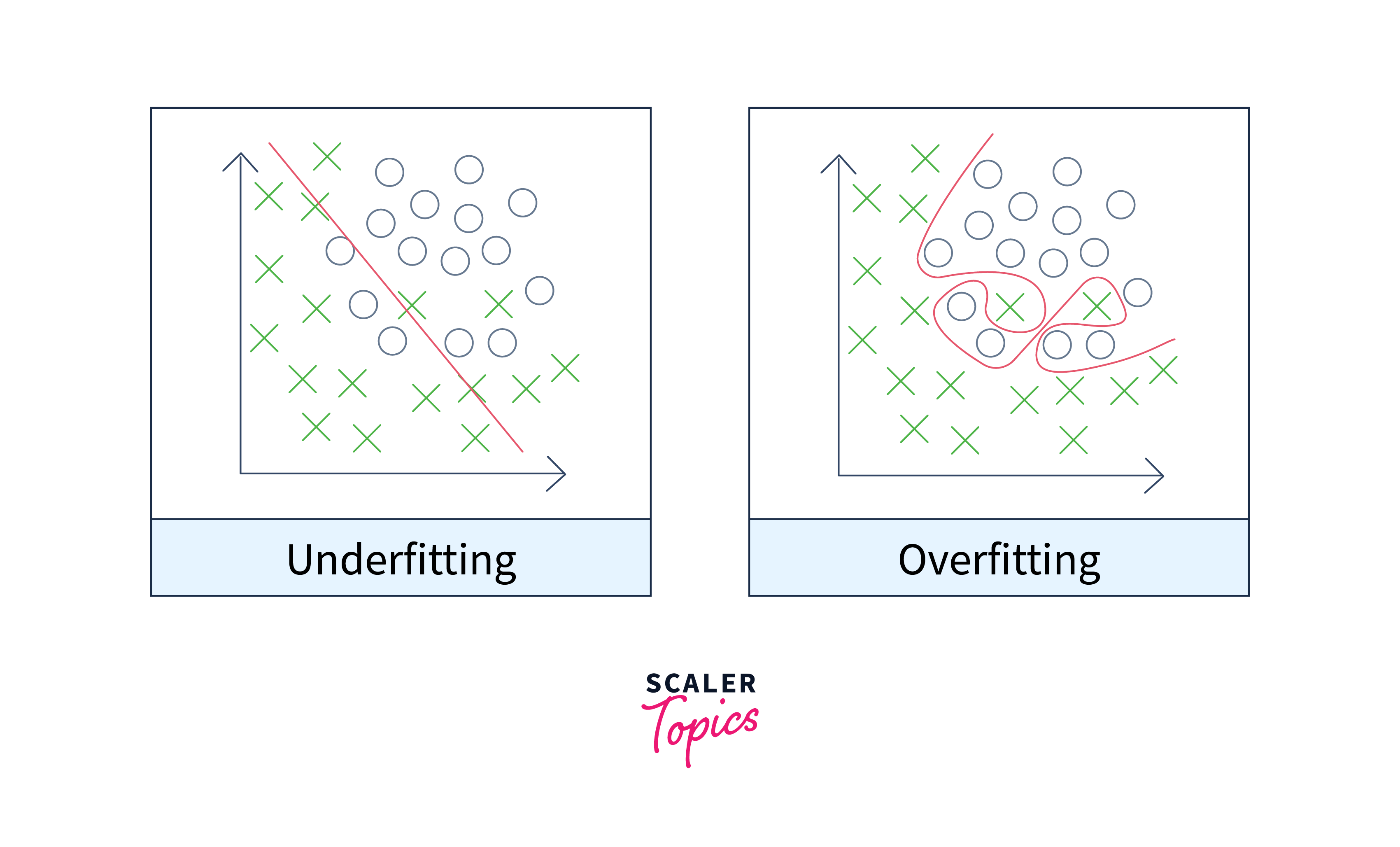
What is Overfitting & Underfitting in Machine Learning?
Overfitting refers to a situation in machine learning where a model performs extremely well on the training data but fails to generalize well to new, unseen data. It occurs when the model becomes too complex and starts to memorize the noise or outliers in the training set. Underfitting, on the other hand, occurs when a model is too simple to capture the underlying patterns in the data, resulting in poor performance both on the training set and new data. You can find a detailed explanation of overfitting and underfitting in this article:
https://www.scaler.com/topics/overfitting-and-underfitting-in-machine-learning/
What are L1 and L2 Regularizers?
L1 and L2 regularization are techniques used to prevent overfitting in machine learning models by adding a penalty term to the loss function. These penalties encourage the model to have smaller parameter values, effectively reducing the complexity of the model.
L1 Regularization
L1 Regularization (Lasso regularization) adds the sum of the absolute values of the model's parameters to the loss function. It encourages sparsity by driving some of the parameter values to zero.
L2 Regularization
L2 Regularization (Ridge regularization) adds the sum of the squared values of the model's parameters to the loss function. It tends to distribute the impact of the penalty more evenly across all the parameters.
L1 and L2 Regularization in TensorFlow
You can apply L1 or L2 regularization to various layers of a neural network by specifying the kernel_regularizer argument when defining the layers.
Regularization strength can be adjusted by setting the appropriate value in the regularization functions, such as l1(0.01) or l2(0.01).
By adding regularization penalties to the loss function during model training, TensorFlow automatically includes the regularization term in the overall loss calculation.
Regularization techniques like L1 and L2 regularization help prevent overfitting, improve model generalization, and control model complexity by encouraging smaller parameter values.
In TensorFlow, L1 and L2 regularization are powerful tools to regularize your models, strike a balance between fitting the training data and preventing overfitting, and improve the model's ability to generalize to new, unseen data.
Implementing regularization in TensorFlow helps mitigate overfitting by controlling model complexity and improving generalization to new data.
Concept of Regularization Penalties and How They Help Control Model Complexity
Regularization penalties help control model complexity by adding a penalty term to the loss function. This penalty encourages the model to find a balance between fitting the training data well and keeping the parameter values small.
By penalizing large parameter values, regularization prevents the model from becoming too complex, reducing the risk of overfitting. The choice of L1 or L2 regularization and the regularization strength determines the impact on the model's complexity.
Differences between L1 and L2 Regularization
| Regularization | Penalty Calculation | Effect on Parameter Values | Geometric Interpretation |
|---|---|---|---|
| L1 (Lasso) | Sum of absolute values | Can drive some parameters to zero (sparsity) | Sparse solutions, fewer features |
| L2 (Ridge) | Sum of squared values | Shrinks all parameter values towards zero, but non-zero | Smaller parameter values, less impact of less important features |
How to Implement L1 and L2 Regularization in TensorFlow
Implementing L1 and L2 regularization in TensorFlow is relatively straightforward. TensorFlow provides built-in functions to apply both types of regularization to the model's parameters. Regularization is typically applied during the model's training process to prevent overfitting.
Step 1. Import the necessary modules:
Step 2. Define your model:
To implement L2 regularization, replace regularizers.l1(0.01) with regularizers.l2(0.01) in the code above.
Step 3. Train your model as usual:
Here, you compile the model with an optimizer, loss function, and metrics. Then, you train the model using the training data and labels.
Adding regularization penalties to the loss function during model training helps control model complexity and prevent overfitting. TensorFlow automatically includes regularization terms through the kernel_regularizer argument. The combined loss guides optimization to find a balance between data fit and smaller parameter values. Regularization strength can be adjusted to achieve the desired balance. It improves generalization and prevents overfitting during model training.
During training, when the model is compiled with the loss function set to 'sparse_categorical_crossentropy', TensorFlow automatically includes the regularization penalties in the overall loss calculation. The optimizer then minimizes this combined loss, optimizing the model's parameters while considering the regularization penalties.
By incorporating regularization penalties into the loss function during model training, you can effectively control model complexity, prevent overfitting, and improve generalization.
What is Dropout Regularization?
Dropout regularization is a technique used in deep learning to prevent overfitting and improve the generalization ability of neural networks. It works by randomly dropping out a certain percentage of units, or neurons, in a neural network during training. This means that the output of these dropped units is set to zero, and they do not contribute to the forward pass or backward pass of the network during that particular training iteration.
By dropping out units, dropout regularization forces the network to learn redundant representations. It prevents individual neurons from relying too heavily on specific input features or co-adapting with other neurons. This encourages the network to be more robust and generalizable because it cannot rely on any single set of features or interactions.
Implementing Dropout Regularization in TensorFlow
To implement dropout regularization in TensorFlow, you can use the tf.keras.layers.Dropout layer. This layer can be added to your neural network architecture to apply dropout to the desired layers. During training, the Dropout layer randomly sets a fraction of the input units to zero. The fraction is defined by the dropout rate, which is typically set between 0.2 and 0.5.
The dropout rate is set to 0.2, meaning that during training, 20% of the input units to these dropout layers will be randomly set to zero.
Controlling Dropout Regularization Strength
Controlling the dropout regularization strength is crucial. A dropout rate of 0.2 means that 20% of the units will be randomly dropped during training, while a dropout rate of 0.5 means that 50% of the units will be dropped. Higher dropout rates generally result in more regularization, but if the rate is set too high, the network may underfit the data and lose valuable information.
One important aspect to note is that dropout is typically only applied during training, not during testing. During inference, the complete network is used, but the weights of the dropped-out units are scaled by the probability of being retained. This scaling ensures that the expected output of the network remains the same, even though some units are dropped.
Impact on Model Complexity
The impact of dropout regularization on model complexity is that it effectively creates an ensemble of multiple subnetworks. Each training iteration samples a different set of units to drop, which means that different subsets of units are active in each iteration. This ensemble nature of dropout regularization can be seen as a form of model averaging, where the final prediction is an average of the predictions made by the different subnetworks. This ensemble helps to reduce overfitting and improve the overall performance of the model.
Benefits of Using Dropout Regularization in TensorFlow
The benefits of using dropout regularization in TensorFlow are as follows:
-
Improved generalization:
Dropout regularization helps prevent overfitting by reducing the reliance of individual neurons on specific features, leading to better generalization and performance on unseen data.
-
Ensemble learning:
Dropout can be seen as training multiple subnetworks simultaneously, resulting in an ensemble of models. This ensemble nature helps capture different patterns and reduces the risk of overfitting.
-
Computational efficiency:
Dropout provides a computationally efficient way to regularize neural networks by randomly dropping units during training. It does not require additional model architecture or complex calculations.
-
Easy to Implement:
TensorFlow provides a simple and intuitive way to implement dropout regularization using the tf.keras.layers.Dropout layer, making it easy to incorporate dropout into your neural network architectures.
What is Batch Normalization?
Batch Normalization is a technique used in deep learning models, particularly in neural networks, to normalize the inputs of each layer. It helps in improving the training process and generalization of the model. The idea behind batch normalization is to normalize the mean and variance of each mini-batch during the training phase.
Batch Normalization addresses the issue of internal covariate shift, which refers to the change in the distribution of network activations as the parameters of the previous layers change during training. By normalizing the inputs to each layer, batch normalization reduces the effects of covariate shift and makes the training process more stable.
The process of batch normalization involves calculating the mean and variance of each mini-batch during training. Then, the inputs of each mini-batch are normalized by subtracting the mean and dividing by the standard deviation. Additionally, batch normalization introduces learnable scale and shift parameters, which allow the model to adapt the normalized inputs to better suit the data.
Regularization is an essential aspect of deep learning to prevent overfitting and improve the generalization of the model. Batch normalization acts as a form of regularization by adding noise to the inputs of each layer. This noise helps in reducing overfitting by forcing the model to be more robust and less sensitive to small changes in the input distribution.
Implementing Batch Normalization in TensorFlow
To include batch normalization in your TensorFlow model, you can add tf.keras.layers.BatchNormalization() layers after each dense layer.
Batch normalization layers are added after the first and second dense layers. The batch normalization layer normalizes the outputs of the previous dense layer across the batch dimension, helping to stabilize and accelerate the training process.
Remember to compile and train your model using the appropriate dataset.
Controlling Batch Normalization Strength
The strength of batch normalization can be controlled by adjusting the momentum parameter of the BatchNormalization layer in TensorFlow. The momentum determines how much of the current batch statistics are used to update the population statistics. A higher momentum value (e.g., 0.99) means that the population statistics change slowly, while a lower value (e.g., 0.9) allows them to adapt more quickly.
Impact on Model Complexity
Batch normalization increases the complexity of the model by adding extra trainable parameters for scale and shift. However, the additional complexity is typically small compared to the overall size of the model, and the benefits of batch normalization often outweigh the increased complexity.
Benefits of Using Batch Normalization in TensorFlow
-
Convergence speed:
Batch normalization helps in faster convergence during training by reducing the internal covariate shift. It allows for higher learning rates and facilitates training deeper neural networks.
-
Reduced sensitivity to initialization:
Batch normalization makes neural networks less sensitive to the choice of initial weights. It helps in avoiding the vanishing or exploding gradient problem by normalizing the inputs.
-
Regularization effect:
Batch normalization acts as a regularizer by adding noise to the inputs of each layer. This helps in reducing overfitting and improving the generalization of the model.
-
Better gradient flow:
Batch normalization improves the flow of gradients through the network, making the optimization process more efficient and stable.
-
Increased stability:
Batch normalization makes the model more robust to changes in the input distribution. It reduces the likelihood of the model getting stuck in saturated regions of activation functions.
What is Early Stopping?
Early stopping is a technique used during the training of machine learning models to prevent overfitting. Overfitting occurs when a model learns to perform well on the training data but fails to generalize to new, unseen data. Early stopping helps combat this issue by monitoring the validation loss during training and stopping the training process when the validation loss starts to increase.
The concept of early stopping involves dividing the dataset into training and validation sets. The training set is used to update the model's parameters, while the validation set is used to evaluate the model's performance on unseen data. As the model is trained, the validation loss is computed at regular intervals. If the validation loss consistently increases for a certain number of epochs (known as the patience parameter), it indicates that the model's performance is deteriorating on unseen data, and early stopping is triggered.
Implementing Early Stopping in TensorFlow
To implement early stopping in TensorFlow, you can use the EarlyStopping callback provided by the Keras API. This callback monitors a specified metric (usually validation loss) and stops the training process when the monitored metric stops improving.
Here,the EarlyStopping callback is created with a monitor set to 'val_loss' (validation loss) and a patience of 5 epochs. The restore_best_weights parameter ensures that the model's weights are restored to the best observed state based on the monitored metric.
Controlling Early Stopping Strength
Controlling the strength of early stopping can be achieved by adjusting the patience parameter. A smaller patience value stops training early, potentially leading to underfitting, while a larger value allows the training to continue for a longer time, increasing the risk of overfitting.
Impact on Model Complexity
The impact of early stopping on model complexity is that it helps prevent the model from becoming too complex or overfitting the training data. By stopping training when overfitting occurs, early stopping effectively limits the model's complexity and encourages it to generalize better to new data.
Benefits of Using Early Stopping in TensorFlow
-
Prevention of Overfitting:
Early stopping prevents the model from overfitting by stopping training when the model's performance on unseen data starts to degrade.
-
Improved Generalization:
By stopping the training process at the right time, early stopping encourages the model to generalize well to new, unseen data, leading to better performance on test or validation datasets.
-
Time and Resource Efficiency:
Early stopping allows you to save time and computational resources by stopping the training process once the model's performance saturates or starts to decline.
What is Hyperparameter Tuning?
Hyperparameter tuning refers to the process of selecting the optimal values for hyperparameters of a machine learning model. Hyperparameters are parameters that are not learned from the data but rather set by the model developer before the training process. These parameters control the behavior of the model and have a significant impact on its performance.
Regularization hyperparameters, such as the regularization strength, dropout rate, and batch normalization parameters, play a crucial role in controlling the complexity and generalization of a model.
Regularization strength:
Regularization is used to prevent overfitting, which occurs when a model performs well on the training data but fails to generalize to new, unseen data. The regularization strength hyperparameter determines the amount of regularization applied to the model. Higher values of regularization strength lead to more regularization, which reduces the model's ability to fit the training data precisely but can improve its generalization on unseen data.
Dropout rate:
Dropout is a regularization technique that randomly sets a fraction of the inputs to zero during training, which helps prevent overfitting. The dropout rate hyperparameter determines the probability of dropping out a unit in a neural network layer. Higher dropout rates introduce more randomness and can prevent the model from relying too heavily on specific features or connections, improving its generalization.
Batch normalization parameters:
Batch normalization is a technique used to standardize the inputs of each layer in a neural network. It helps in stabilizing the learning process and accelerating convergence. The batch normalization parameters, such as momentum and epsilon, control how the batch normalization is applied. Adjusting these parameters can impact the model's training speed, stability, and generalization.
Implementing Hyperparameter Tuning in TensorFlow
Implementing hyperparameter tuning in TensorFlow involves defining a search space for the hyperparameters, selecting an optimization method, and evaluating the model's performance for different hyperparameter configurations. Here's an example of how you can implement hyperparameter tuning using TensorFlow and the Keras API:
Controlling Hyperparameter Tuning Strength
Controlling the strength of hyperparameter tuning allows you to find a balance between underfitting and overfitting. If the hyperparameter tuning is too weak, the model may underfit the data, resulting in poor performance. On the other hand, if the hyperparameter tuning is too strong, the model may overfit the data and fail to generalize well to new data. Finding the right level of hyperparameter tuning strength is essential for achieving optimal model performance.
Impact on Model Complexity
Hyperparameter tuning impacts the model complexity. By adjusting the regularization strength, dropout rate, and batch normalization parameters, you can control the complexity of the model. Higher regularization strength and dropout rates tend to reduce the complexity of the model by discouraging overfitting. Batch normalization helps stabilize the learning process and can improve model performance by controlling the distribution of inputs at each layer.
Benefits of Using Hyperparameter Tuning in TensorFlow
-
Improved model performance:
By finding optimal hyperparameter values, you can improve the model's performance on the validation or test data, leading to better predictions.
-
Generalization ability:
Hyperparameter tuning helps prevent overfitting, enabling the model to generalize well to new, unseen data. It helps strike a balance between model complexity and generalization.
-
Efficient resource utilization:
Hyperparameter tuning allows you to fine-tune the model's behavior without the need for extensive computational resources or manually exploring a large parameter space.
-
Robustness and stability:
By carefully selecting hyperparameter values, you can make the model more robust and stable, reducing its sensitivity to variations in the input data.
-
Reproducibility:
By tuning hyperparameters and documenting the selected values, you can ensure that your model's performance is reproducible and consistent across different runs.
Conclusion
- Regularization is a crucial technique in TensorFlow for preventing overfitting in machine learning models. It helps to improve the model's ability to generalize well to unseen data.
- TensorFlow provides various regularization methods, such as L1 and L2 regularization, dropout, and batch normalization, which can be easily incorporated into the model architecture.
- L1 and L2 regularization add penalty terms to the loss function, encouraging the model to have smaller weights. This helps prevent the model from relying too heavily on a few features and reduces overfitting.
- Dropout regularization randomly sets a fraction of the input units to zero during training, which reduces the model's reliance on specific connections and features. It introduces stochasticity and helps prevent complex co-adaptations between neurons.
- Batch normalization is a technique used to normalize the inputs of each layer in a neural network. It helps stabilize the learning process, speeds up convergence, and reduces the impact of small changes in the network's parameters.