Serving TensorFlow Models with TF Serving
Overview
TensorFlow Serving is an open-source library developed by Google that facilitates the deployment of machine learning models for production use cases. It serves as a bridge between trained models and the production environment, enabling seamless deployment and serving of TensorFlow models.
TensorFlow Serving provides a scalable and efficient architecture for managing, updating, and monitoring machine learning models in production. It addresses the challenges of handling concurrent requests, scaling to serve high traffic, and allowing seamless updates without causing downtime.
In this article, we will explore TensorFlow Serving in detail. We will cover its architecture, the steps to set it up, and how to deploy and manage TensorFlow models using TensorFlow Serving.nent in real-world machine learning applications.
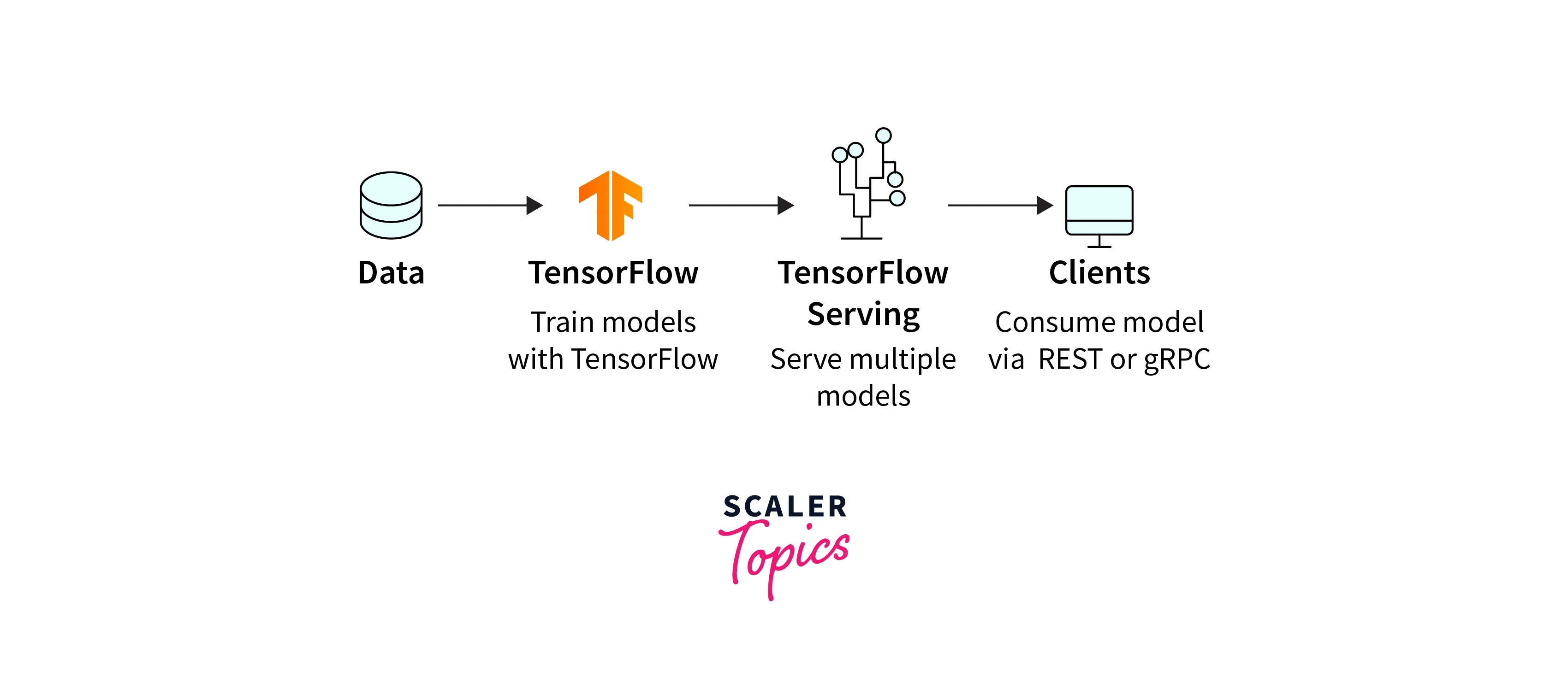
TensorFlow Serving Architecture
TensorFlow Serving's architecture is designed to be scalable, modular, and extensible. It follows a client-server paradigm, where the client sends a request containing input data, and the server responds with the model's predictions. Let's take a closer look at the key components of TensorFlow Serving's architecture:
-
Client:
The client is responsible for sending prediction requests to the TensorFlow Serving server. It can be any application that needs predictions from the deployed model, such as a web service or mobile application.
-
Model Server:
The model server is the core component of TensorFlow Serving. It manages the loading and unloading of models, serves predictions, and handles various model versions. It exposes a well-defined API that clients can use to request predictions.
-
Servables:
A servable is a loadable unit of a TensorFlow model. It can represent different versions of the same model or multiple models. The model server can handle multiple servables concurrently, enabling model versioning and A/B testing.
-
Loader:
The loader is responsible for loading the servables into memory. TensorFlow Serving uses a lazy loading approach, which means the model is loaded into memory only when a prediction request arrives.
Setting up TensorFlow Serving
Before deploying models with TensorFlow Serving, you need to set it up on your system. TensorFlow Serving can be installed using Docker or as a system package. We'll outline the steps to set up TensorFlow Serving using Docker:
-
Install Docker:
If you don't have Docker installed, follow the instructions for your operating system from the official Docker website.
-
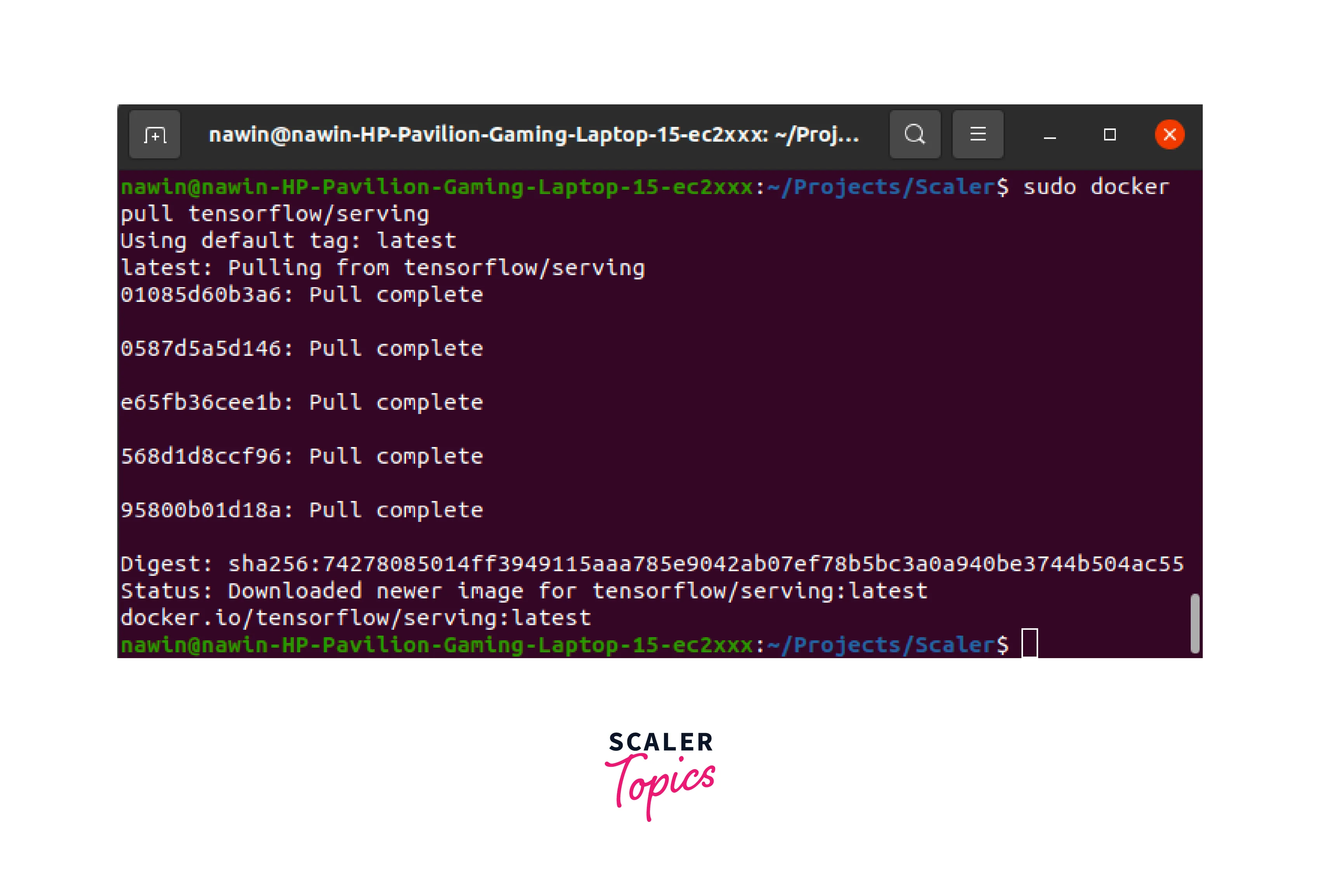
Pull TensorFlow Serving Image:
Use the following command to pull the TensorFlow Serving Docker image:
Output:
-
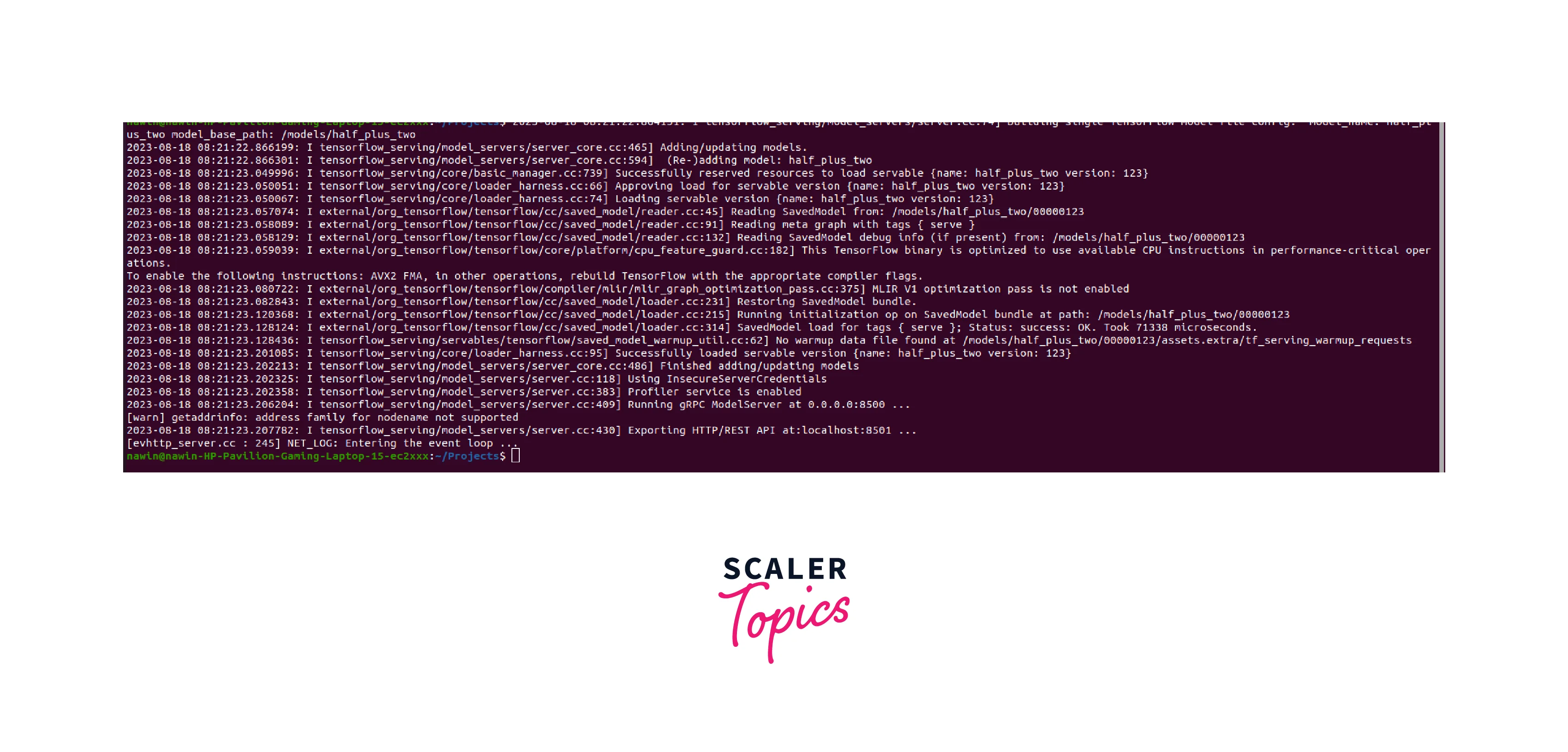
Run TensorFlow Serving:
After pulling the image, start the TensorFlow Serving container with the desired model by specifying the model's location. For example:
Output:
Here, replace /path/to/model/directory with the path to the directory containing your saved TensorFlow model, and model_name with the name of your model.
-
Test the Deployment:
Once TensorFlow Serving is up and running, you can send test requests to ensure everything is working correctly. Use the following command to send a test request:
Output:
Replace input_data with the test data for which you want to get predictions.
With TensorFlow Serving set up, let's move on to the steps involved in serving TensorFlow models using TensorFlow Serving.
Serving TensorFlow Models with TensorFlow Serving
In order to deploy models using Tensorflow serving, we need to follow these steps:
- Step 1. Installing Dependencies.
- Step 2. Building the Model.
- Step 3. Preprocessing the inputs.
- Step 4. Postprocessing the predictions.
- Step 5. Save the Model.
- Step 6. Examine the trained model.
- Step 7. Exporting the model.
- Step 8. Deploying the models using Tensorflow serving.
Now we'll see how to deploy models using Tensorflow serving by using MobileNet pre-trained model.
Step 1: Dependencies
To begin with, you need to install the necessary dependencies, including TensorFlow and TensorFlow Serving. Make sure you have the appropriate versions installed to avoid compatibility issues.
Step 2: Model
For the purpose of this article, we'll use a handwritten digit classifier with a simple Softmax Regression model.
We'll use MobileNet pre-trained model to illustrate the process of saving a model to disk.
The above code can be used to train and export the model to serve using Tensorflow Serving.
Step 3: Preprocessing
Before serving the model, it's crucial to preprocess the input data to match the model's input format. In this example, the input images are expected to be grayscale images with a shape of (28, 28, 1). If the incoming data is in a different format, it should be preprocessed accordingly.
Step 4: Postprocessing
Similarly, after receiving predictions from the model, postprocessing may be necessary to transform the output into a human-readable format or perform any required additional operations.
To check the process, let's download a banana picture,
Output:
Step 5: Save the Model
To deploy the model using TensorFlow Serving, we need to save it in the SavedModel format, which is a serialized version of the model containing both the model architecture and its trained weights.
Output:
Step 6: Examine Your Saved Model
You can examine the contents of the SavedModel using the saved_model_cli tool provided by TensorFlow:
Output:
This will display information about the model's inputs, outputs, and signatures.
Step 7: Exporting and Saving TensorFlow Models for Serving
TensorFlow Serving requires models to be saved in a specific directory structure called the "servable" format. When using the SavedModel format, the model directory should have the following structure:
To install tensorflow serving use the following command
The above command installs the Tensorflow serving to our system. Now, we'll start running Tensorflow serving and load our model. After loading, we can make inference by making requests using REST. The important parameters to be considered are:
- port: The port that you'll use for gRPC requests.
- rest_api_port: The port that you'll use for REST requests.
- model_name: You'll use this in the URL of REST requests. It can be anything.
- model_base_path: This is the path to the directory where you've saved your model.
Step 8: Deploying Models with TensorFlow Serving
Once you have prepared your model in the servable format, you can deploy it using TensorFlow Serving. We already covered the steps to set up TensorFlow Serving with Docker. When deploying a new model or updating an existing one, ensure that the model server is configured to serve the correct version of the model.
With the updated model directory mounted, the model server will serve the latest version of the model.
Clients can now send prediction requests to the server to obtain model predictions.
Managing Model Versions and Serving Multiple Models
TensorFlow Serving allows you to manage multiple versions of a model and serve them concurrently. When you deploy a new version of a model, it doesn't affect the existing versions being served. Clients can explicitly request a specific version for prediction.
To serve a single model, use the following command:
Output:
To serve multiple models, follow a similar directory structure for each model:
The following code can be used serve multiple models using tensorflow serving

Output:

Serve Your Model with TensorFlow Serving
To test the model's deployment, you can send prediction requests to the model server using tools like curl or through custom applications. Ensure that the input data is properly formatted and matches the model's input requirements.
Make a Request to Your Model in TensorFlow Serving
We can now use REST API to make predictions using a Tensorflow Serving Model. It starts by converting a batch of images into a JSON format compatible with the model's input. Then, it sends a POST request to the model's prediction endpoint using the given URL. The response from the model is parsed, the prediction outputs are extracted, and the shape of the outputs is printed. Finally, the postprocess() function is assumed to be used to determine and print the predicted class based on the model's output.
Output:
Best Practices of Using TensorFlow Serving
When deploying machine learning models with TensorFlow Serving, there are several best practices to ensure optimal performance and maintainability:
-
Monitor Model Performance:
Keep track of your model's performance metrics in the production environment. Monitor factors such as request latency, error rates, and resource utilization to identify any issues.
-
Versioning:
Implement model versioning to allow seamless updates and A/B testing of different model versions. This allows you to roll back to previous versions if needed.
-
Health Checks:
Set up health checks for your model server to ensure that it is responsive and functioning correctly. This helps in quickly identifying any service interruptions.
-
Scaling:
Configure TensorFlow Serving to scale dynamically based on traffic demands. Use load-balancing mechanisms to distribute requests across multiple instances if required.
-
Graceful Shutdown:
Implement graceful shutdown procedures to avoid disruption of service during model updates or server maintenance.
-
Security:
Protect your model server with appropriate security measures, such as access controls and encryption, especially when serving sensitive data.
-
Model Optimization:
Optimize your models for serving. Consider reducing the model's size, leveraging TensorFlow Lite for mobile applications, or TensorFlow.js for browser-based applications.
-
Logging and Error Handling:
Implement robust logging and error handling to facilitate debugging and issue resolution.
Conclusion
- TensorFlow Serving is a valuable tool for deploying machine learning models in production environments.
- Its scalable and efficient architecture allows for easy management, updating, and monitoring of models, making it a critical component for real-world applications.
- By following best practices and adhering to the guidelines provided in this article, you can effectively deploy and serve TensorFlow models using TensorFlow Serving, empowering your applications with powerful machine learning capabilities.