Building a Transformer with TensorFlow
Overview
Transformers have been gaining popularity recently due to GPT models by OpenAI. Transformers have made a huge impact on the Natural Language Processing domain, especially in solving the long-term dependencies of the traditional sequence models. Transformers aided in successfully establishing “Transfer Learning” in NLP by enabling the features extracted from a pretrained model. In this blog, we will look into the architecture of Transformers and build a Tensorflow transformer model.
Introduction
Traditional sequence models, such as recurrent neural networks (RNNs), have difficulty capturing long-term dependencies and exhibit vanishing or exploding gradients.
When we use activation functions like Sigmoid, there will be a huge difference between the variance of their input space and the output space. They will shrink from a larger input space to a smaller output space between [0,1].
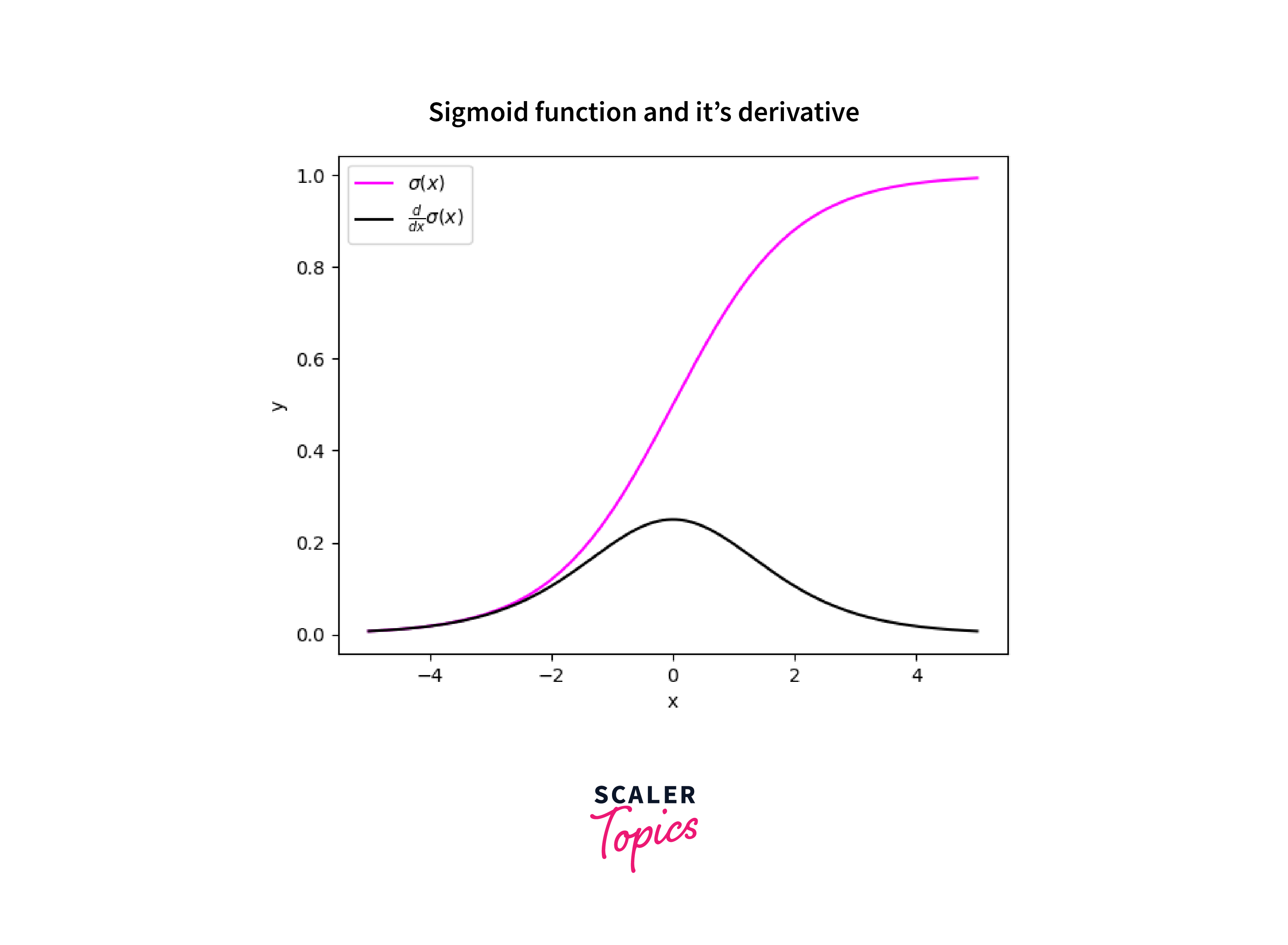
Also, in specific cases, suppose the initial weights assigned to the neural network will have a large loss due to gradient accumulation during each update, resulting in larger gradients and, thus, an unstable network. This phenomenon is called vanishing and exploding gradients.
-
Exploding Gradients:
In exploding gradients, the gradients keep getting larger and larger, causing very large weight updates, which leads to diverging of gradients.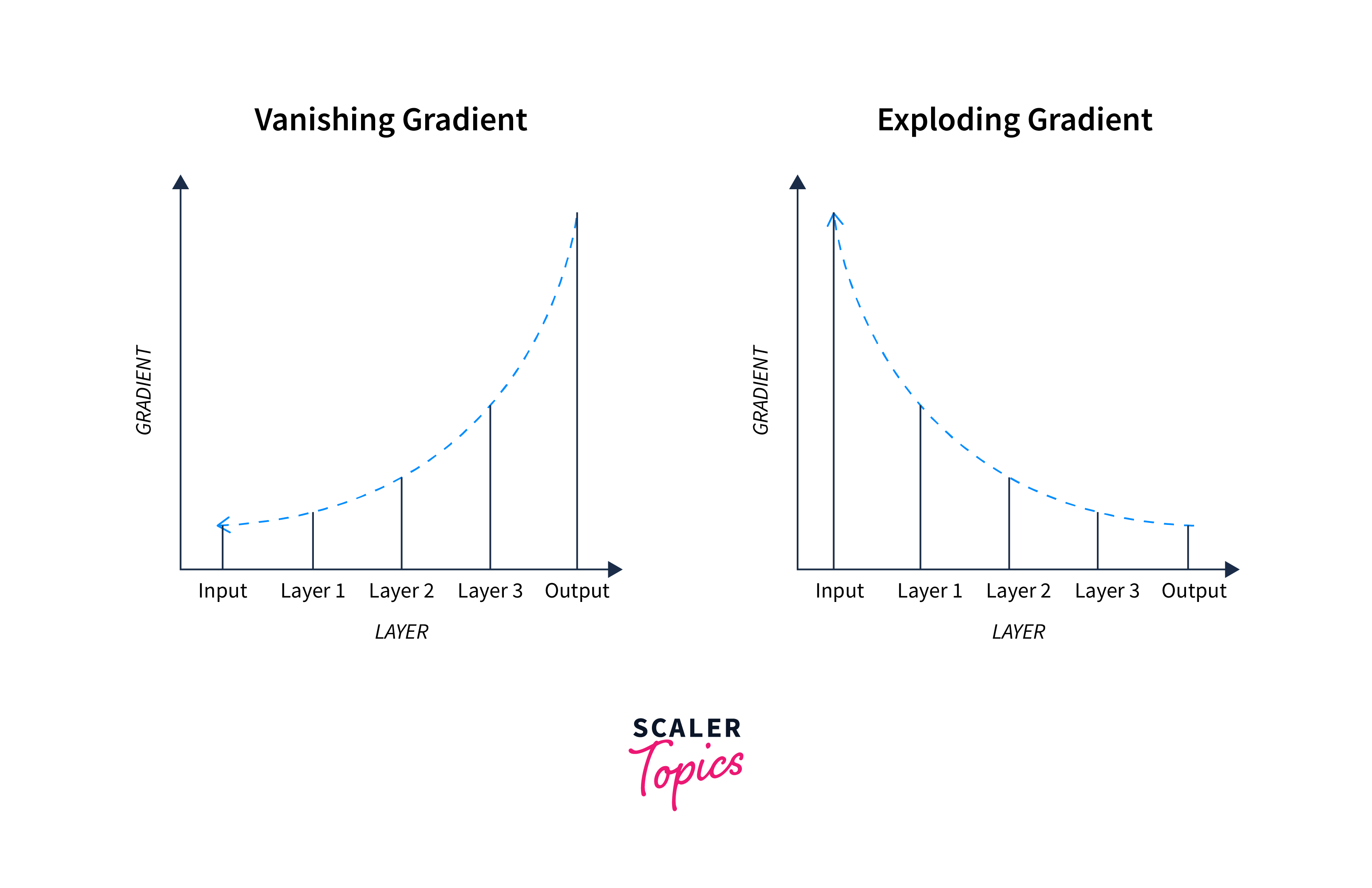
Transformers solve these restrictions and have become the foundation of many cutting-edge NLP models, such as machine translation, text generation, and language understanding tasks.
In this blog post, we will look at the working principle of transformers, including their architecture, components, and information flow inside the model.
What is Transformer?
A transformer refers to a type of deep learning model architecture that has gained significant popularity and success in various natural language processing (NLP) tasks. It was introduced in a groundbreaking research paper called Attention Is All You Need by Vaswani et al. in 2017.
The transformer architecture deviates from sequential processing and adopts a parallel and attention-based approach. It consists of an encoder and a decoder, which work together to process input sequences and generate output sequences. Attention mechanisms play a pivotal role in allowing the model to focus on relevant information.
Components of the Transformer Architecture
The Transformer Architecture comprises two main components: an encoder and a decoder. These components collaborate to process and produce sequences of text. The encoder's role is to encode the input sequence, while the decoder is responsible for generating the output sequence.
The heart of the transformer lies in its attention mechanism, which enables the model to focus on different parts of the input sequence with varying importance.
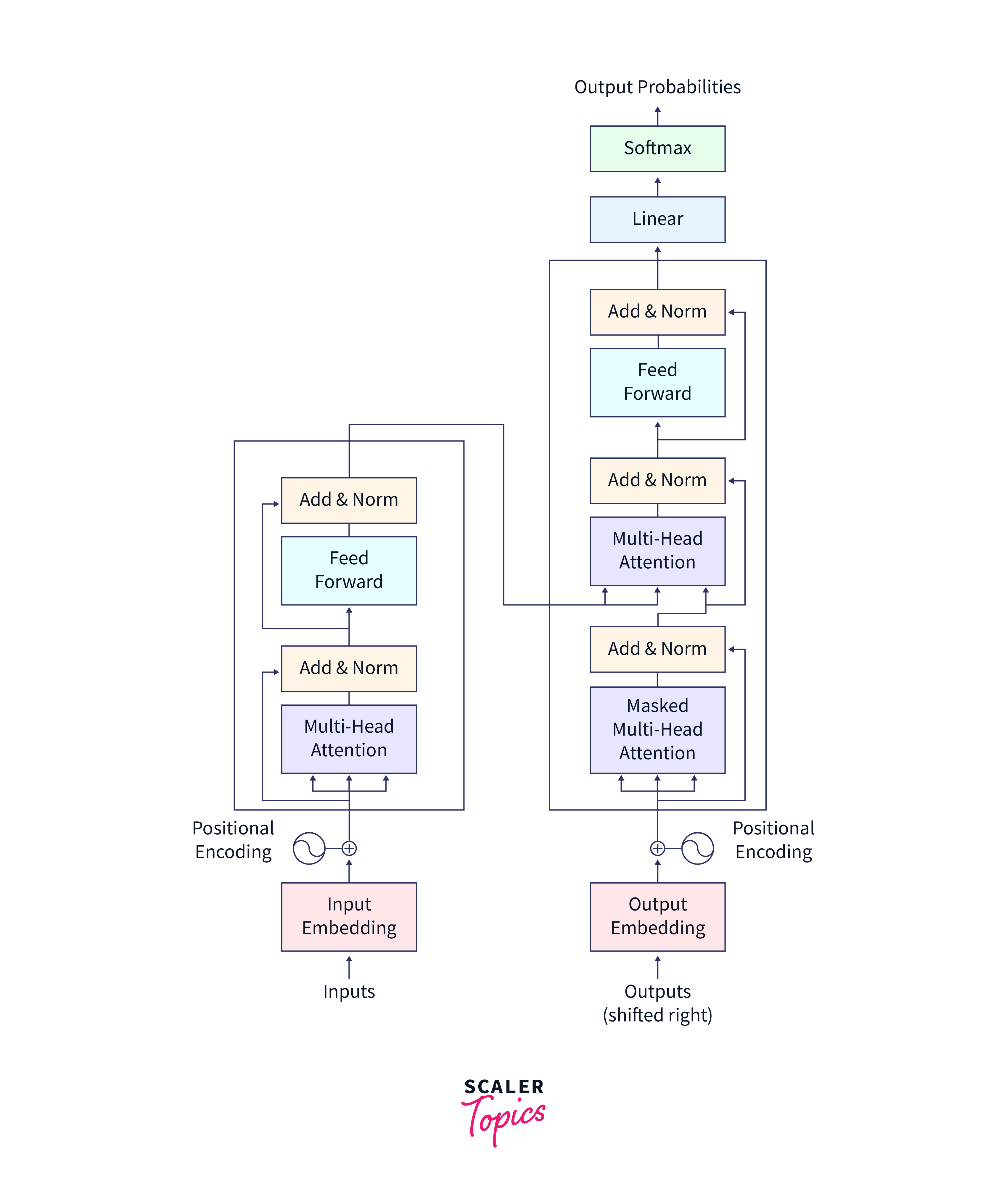
The different components of Transformer architecture are as follows:
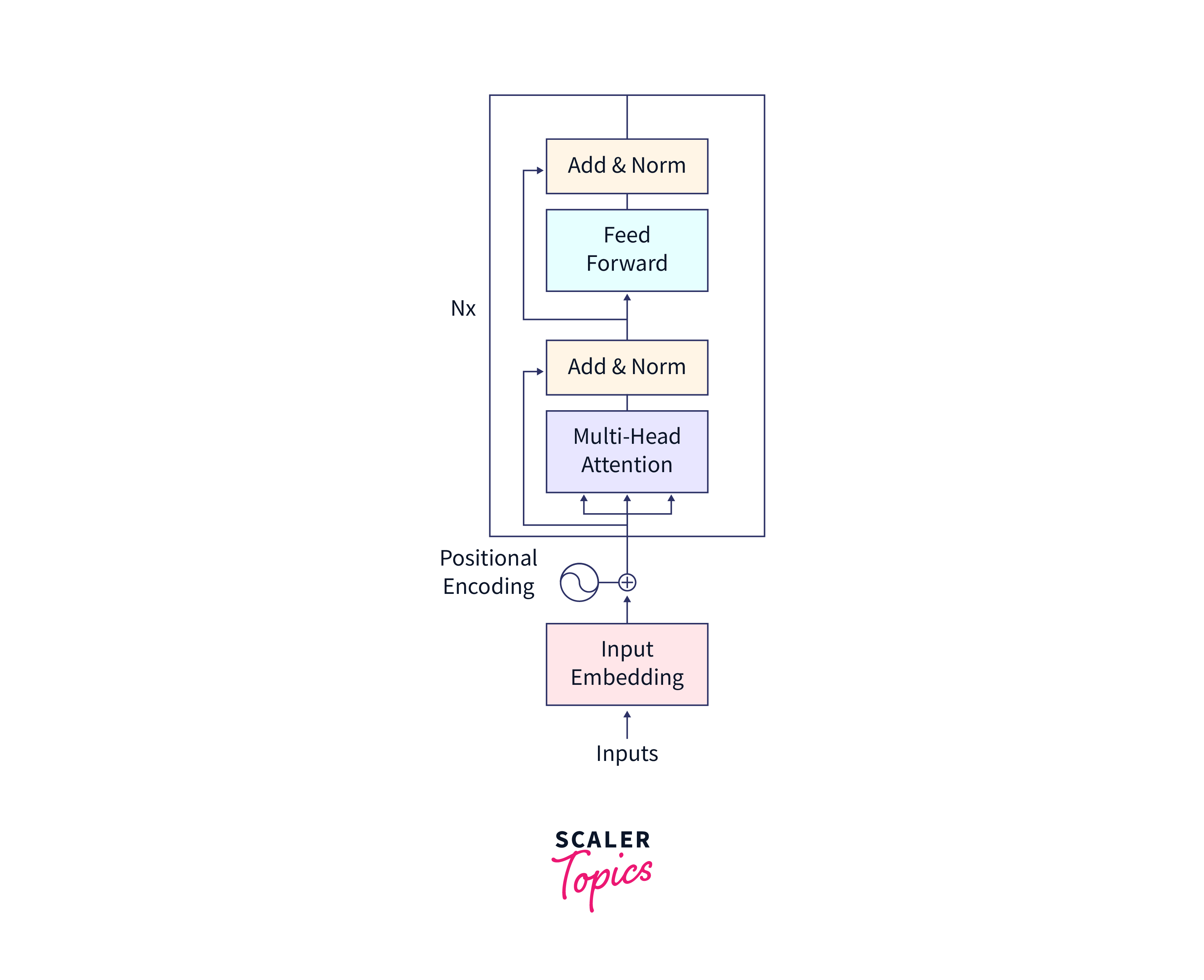
Encoder
The encoder takes an input sequence and transforms it into a set of encoded representations. It consists of multiple identical layers, each of which performs two main operations: self-attention and feed-forward neural networks.
-
Self-Attention:
Self-attention is a mechanism that allows the encoder to weigh the importance of different words or tokens in the input sequence when processing each element. It captures dependencies between words by assigning attention scores to different positions in the sequence.These attention scores determine the influence of each word on the representation of other words in the sequence. By attending to the entire input sequence, the encoder can effectively capture long-range dependencies.
-
Feed-Forward Neural Networks:
After self-attention, the encoder passes the outputs through a feed-forward neural network. This network consists of fully connected layers and applies a non-linear transformation to the representations. It allows the model to capture complex patterns and relationships between words.The encoder repeats the self-attention and feed-forward operations for a fixed number of layers, enabling the model to refine and extract high-level representations of the input sequence.
Decoder
The decoder takes the encoded representations generated by the encoder and produces an output sequence. It also consists of multiple identical layers but with some additional components compared to the encoder.
-
Self-Attention (masked):
Similar to the encoder, the decoder uses self-attention to attend to the encoded representations. However, there is a crucial difference called masking. During training, the decoder is not allowed to look ahead and attend to future positions in the output sequence. This masking ensures that the model generates the output sequence autoregressively, one position at a time, following the left-to-right order. -
Encoder-Decoder Attention:
In addition to self-attention, the decoder incorporates an attention mechanism that allows it to attend to the encoded representations produced by the encoder. This attention mechanism helps the decoder focus on relevant parts of the input sequence while generating the output. -
Feed-Forward Neural Networks:
The decoder also employs feed-forward neural networks to process the representations obtained from the self-attention and encoder-decoder attention steps. These networks transform the representations and capture intricate relationships between the input and output sequences.By stacking multiple layers of self-attention, encoder-decoder attention, and feed-forward neural networks, the decoder learns to generate accurate and coherent output sequences based on the encoded representations.
The encoder-decoder architecture in tensorflow transformers enables the model to effectively handle tasks such as machine translation, where an input sequence in one language is transformed into an output sequence in another language.
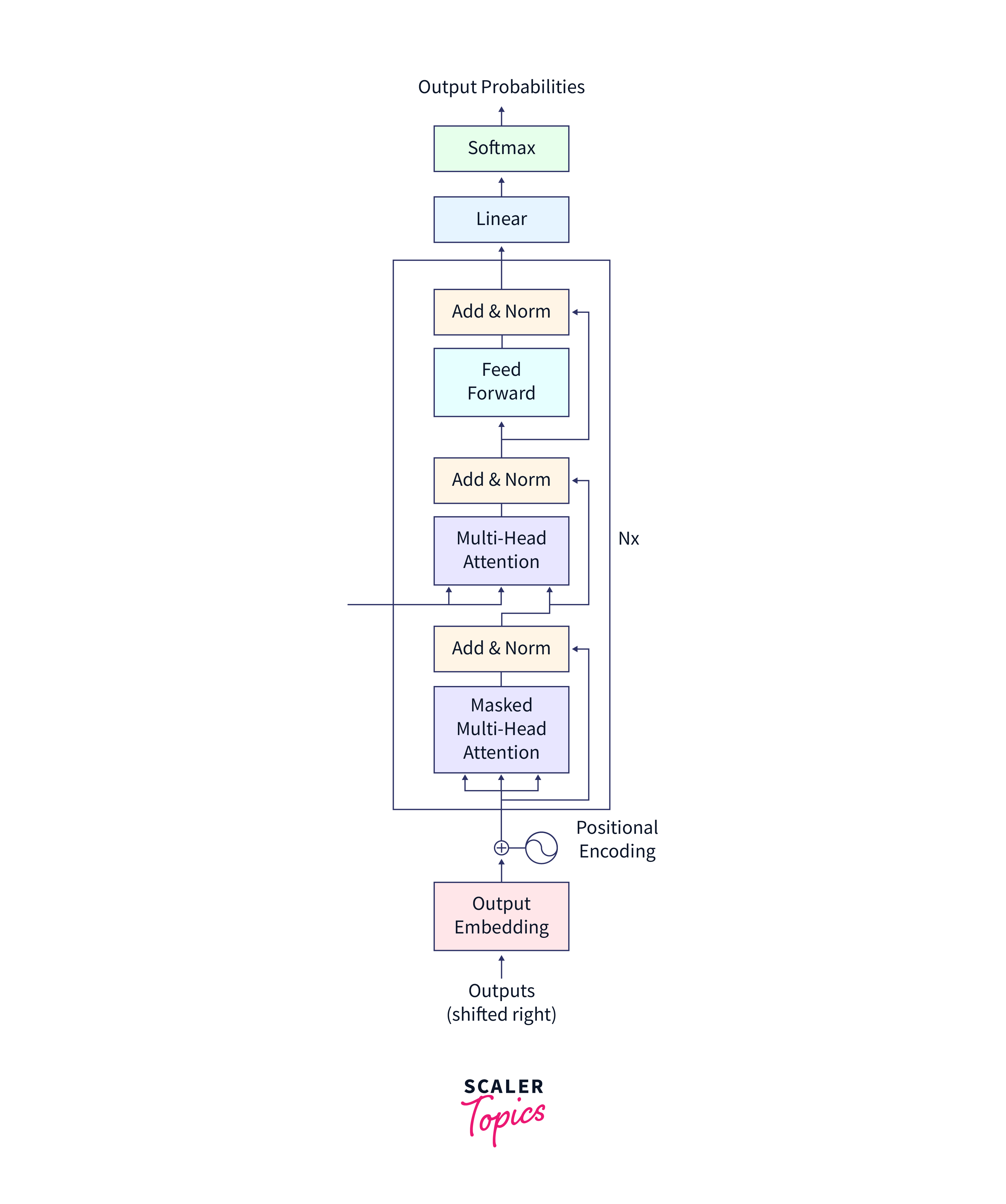
Data Preparation for the Transformer Model
Before getting started with the Tensorflow transformer model we need to prepare the dataset for our model. For that, we need to set up the environment.
Step - 1: Getting Started
To get started, we need to set up our environment by installing TensorFlow and TFDS. Open a Python environment and run the following commands:
Step - 2: Importing the Necessary Libraries
Next, we import the required libraries in our Python script:
Step - 3: Fetching the Portuguese/English Translation Dataset
Now, let's fetch the Portuguese/English translation dataset from TFDS:
Step - 4: Preparing the Data
After fetching the dataset, we need to preprocess and prepare the data for training the Tensorflow transformer model. This involves tokenization and padding.
Tokeninzation is the process of breaking up text into 'tokens' representing pieces, words, subwords, or charecters. Tensorflow transformers can be tokenized using the tokenize method. Before setting up the
Building a Transformer with TensorFlow
Step - 1: Defining the Components
1. Positional Encoding:
The below function generates positional encodings for a given sequence length and depth. Positional encodings are used in tensorflow transformer models to provide positional information to the model, enabling it to understand the order and relative positions of words or tokens in a sequence.
2. Positional Embeddings:
The positional embedding layer takes an input sequence, applies word embeddings, and adds positional encodings to provide semantic and positional information to the model.
3. Base Attention layer:
The base Attention layer encapsulates a multi-head attention mechanism with layer normalization and addition operations.
4. Self Attention Layer:
It allows the model to attend to different parts of the input sequence to capture dependencies and relationships between the elements within the sequence. Here's an example of a self-attention layer:
5. Feed Forward Layer:
The feed-forward network is responsible for applying non-linear transformations to the input representation.
6. Encoder

-
encoder layer:
The Encoder consists of sub-layers that process the input sequence and capture relevant information.
-
encoder:
The encoder consists of multiple encoder layers stacked on top of each other. Each encoder layer consists of sub-layers that perform specific operations, such as self-attention and feed-forward transformations.
7. Decoder

-
The Decoder layer:
The decoder layer closely resembles the encoder layer but includes extra sub-layers to facilitate output sequence generation. Typically, it comprises three sub-layers: masked multi-head self-attention, encoder-decoder attention, and a feed-forward network.
These sub-layers work together to capture relevant information from the encoded input and generate the output sequence.
- Testing the decoder layer
-
The Decoder
The decoder in a tensorflow transformer model is responsible for generating the output sequence by sequentially decoding the encoded input. It consists of multiple decoder layers, which are stacked on top of each other.
-
Testing the decoder:
Step - 2: Build the Transformer Model
Finally, the implementation of the Tensorflow Transformer model is given below:
Step - 3: Train the Transformer Model
Before training the tensorflow transformer model. We need to set the hyperparameters for the tensorflow transformer model. The hyperparameters of the tensorflow transformer model have been reduced for a fast training period suitable for this tutorial.
In the original Transformer paper, the base model was configured with six layers, a model dimension (d_model) of 512, and a feed-forward network dimension (dff) of 2048.
These parameters are instantiated in the tensorflow transformer model:
Get the model architecture of the tensorflow transformer model using model.summary()
Output:
now, we define the loss and accuracy of the tensorflow transformer model using the following functions.
Now, the tensorflow transformer model can be trained using the transformer.fit() method.
Step - 4: Evaluate and Fine-Tuning the Transformer Model
After training the model, we can evaluate its performance and make any necessary fine-tuning adjustments. This involves running the model on a test dataset and measuring relevant metrics, such as accuracy and loss. Additionally, fine-tuning techniques like learning rate schedules or early stopping can be applied to optimize the model's performance.
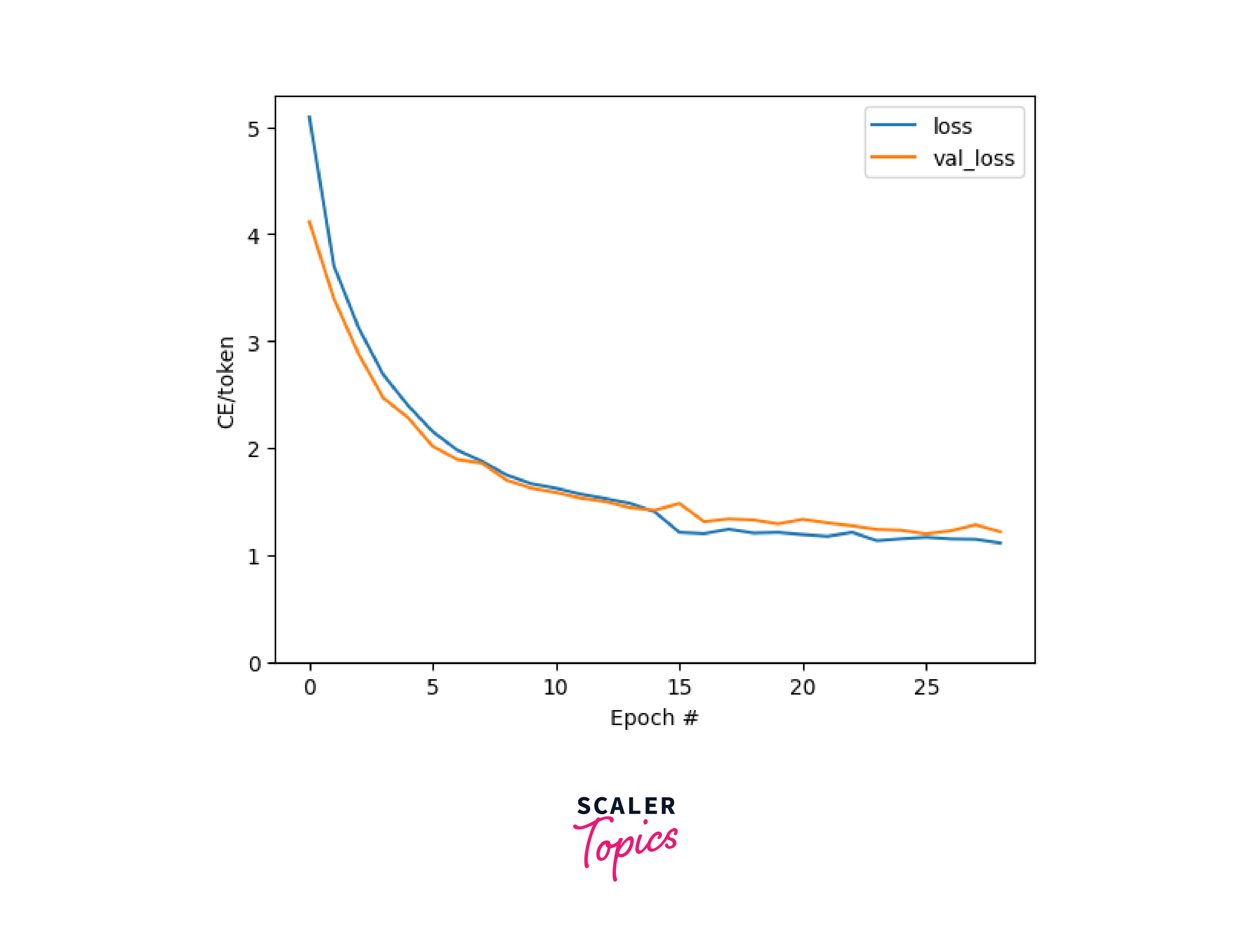
The Tensorflow transformer model's loss graph can be plotted using here using the following code.
Output:
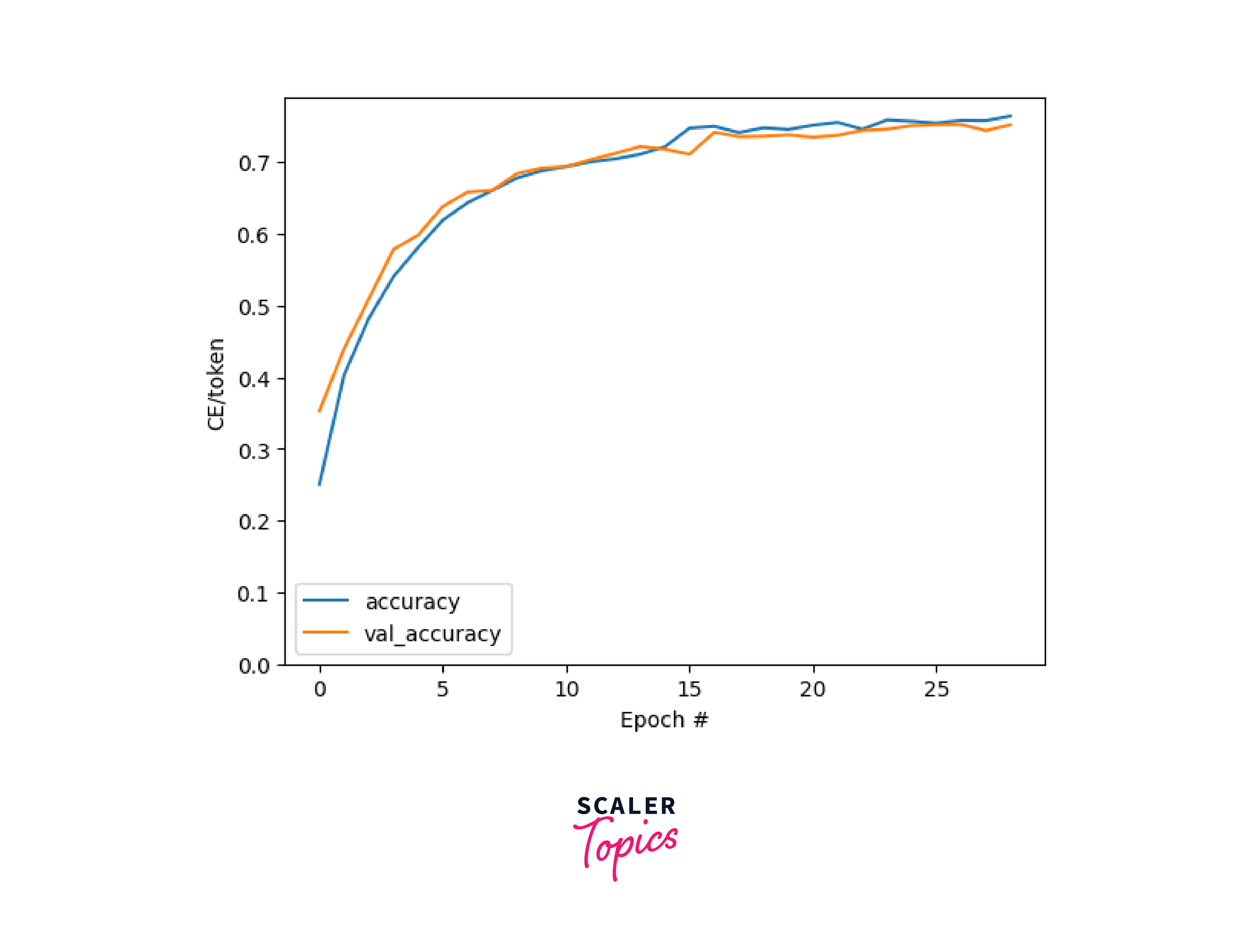
The Tensorflow transformer model's masked accuracy graph can be plotted here using the following code.
Output:
Step - 5: Advanced Techniques and Extensions
The Transformer architecture offers several advanced techniques and extensions to further enhance its capabilities. Some of these techniques include,
- Incorporating positional encoding:
Introduce the notion of sequence order into the model by adding positional information to the input embeddings to understand relative token positions. - Exploring different attention mechanisms:
Enhance information extraction and learning by using various attention mechanisms like multi-head attention, scaled dot-product attention, etc., to focus on different aspects of the input sequence simultaneously. - Applying regularization methods:
Prevent overfitting and improve generalization by adding dropout regularization to the layers of the model during training. - Utilizing pre-trained transformer models:
Benefit from pre-trained transformer models (e.g., BERT, GPT) that capture complex language patterns and representations, which can be fine-tuned for specific tasks or used as feature extractors for downstream tasks.
Conclusion
- Building a Transformer model using TensorFlow provides a powerful tool for text classification tasks.
- By understanding the different components of the Transformer architecture, preparing the data, and implementing the model using TensorFlow, you can leverage the potential of deep learning to achieve state-of-the-art results in NLP tasks.
- The Transformer's ability to capture long-range dependencies and its parallelizable nature make it an ideal choice for various natural language processing applications