Word Embeddings with TensorFlow
Overview
Word embeddings have become indispensable tools in natural language processing (NLP). They enable machines to understand the meaning and context of words in a way that goes beyond traditional encoding methods. This article thoroughly explores tensorflow word embeddings. We will delve into the Word2Vec and GloVe models, discuss using word embeddings in TensorFlow, explore transfer learning possibilities, and cover evaluation and visualization techniques.

What is Word Embeddings?
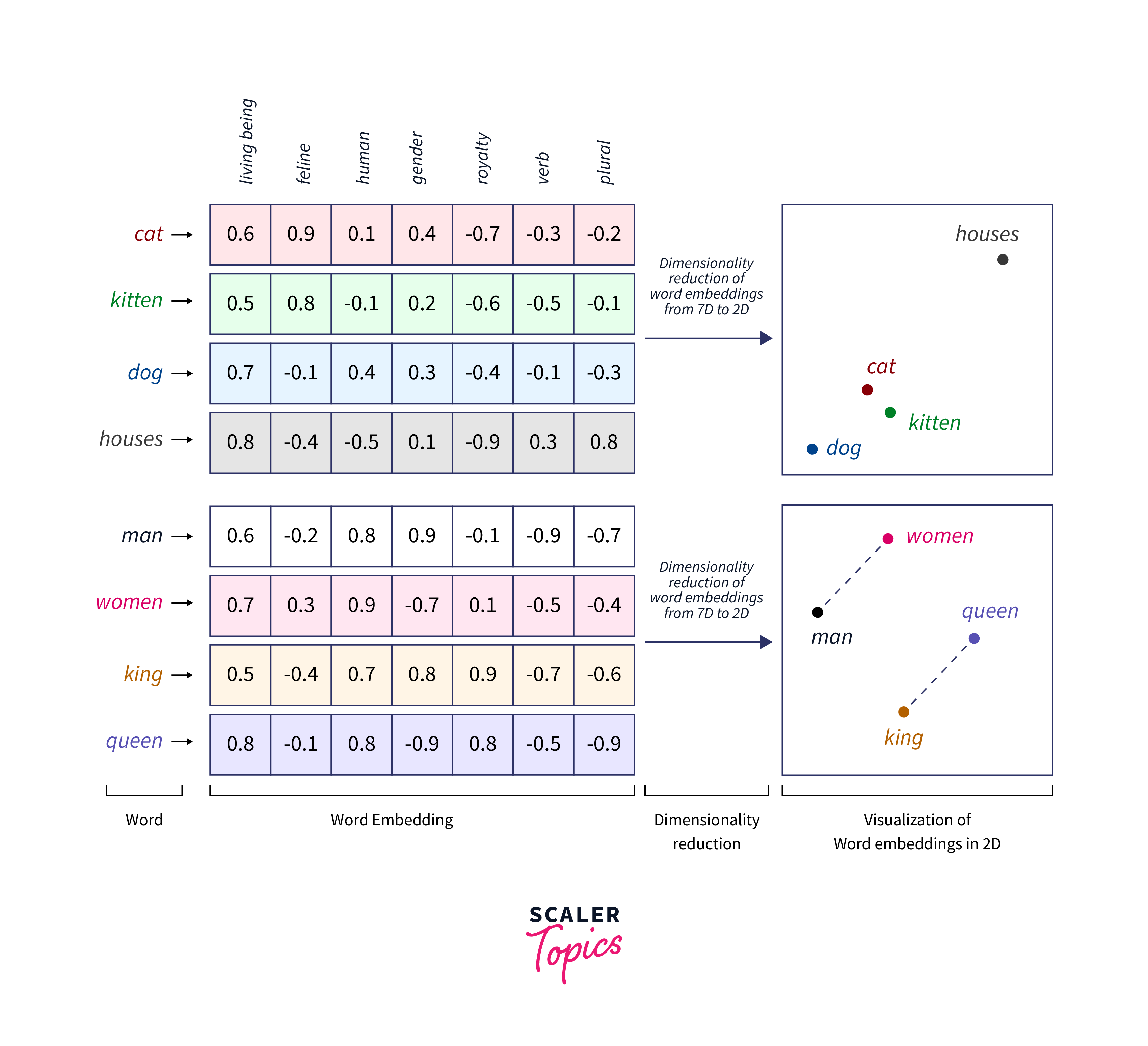
Word embeddings, often called word vectors, represent words as dense vectors in a continuous numerical space. These vectors capture the relationships between words, allowing models to understand the semantics and context of words. Word embeddings have numerous advantages over traditional methods, such as one-hot encoding or bag-of-words representations. They address the issue of high dimensionality and offer insights into word meanings and similarities. Two prominent approaches to generating tensorflow word embeddings are the Word2Vec and GloVe models, each with its unique methodology.
Word2Vec Model
The Word2Vec model is a popular algorithm for generating word embeddings, which are vector representations of words in a continuous vector space. Word2Vec is designed to capture semantic relationships between words by learning from large text corpora. Developed by Tomas Mikolov and his team at Google, Word2Vec has become a fundamental tool in natural language processing (NLP) and word representation learning. Word2Vec offers two main training approaches: Continuous Bag of Words (CBOW) and Skip-gram. Let's explore each of these approaches:
- Continuous Bag of Words (CBOW):
In the CBOW approach, the Word2Vec model predicts a target word based on its context, which consists of surrounding words. It operates like a "fill-in-the-blank" task, where the model tries to predict the target word using the context words. Here's how CBOW works:- Input:
A window of context words (e.g., "the cat sat on the ____"). - Output:
The target word ("mat" in this example). The model learns to associate words that appear in similar contexts, effectively capturing semantic meaning. CBOW is often faster to train and is a good choice when you have a large amount of training data.
- Input:
The CBOW model aims to maximize the probability of the target word given the context words:

- Skip-gram:
In contrast to CBOW, the Skip-gram approach flips the prediction task. Instead of predicting the target word from context words, Skip-gram predicts context words based on a target word. It's like guessing the context based on a single-word clue.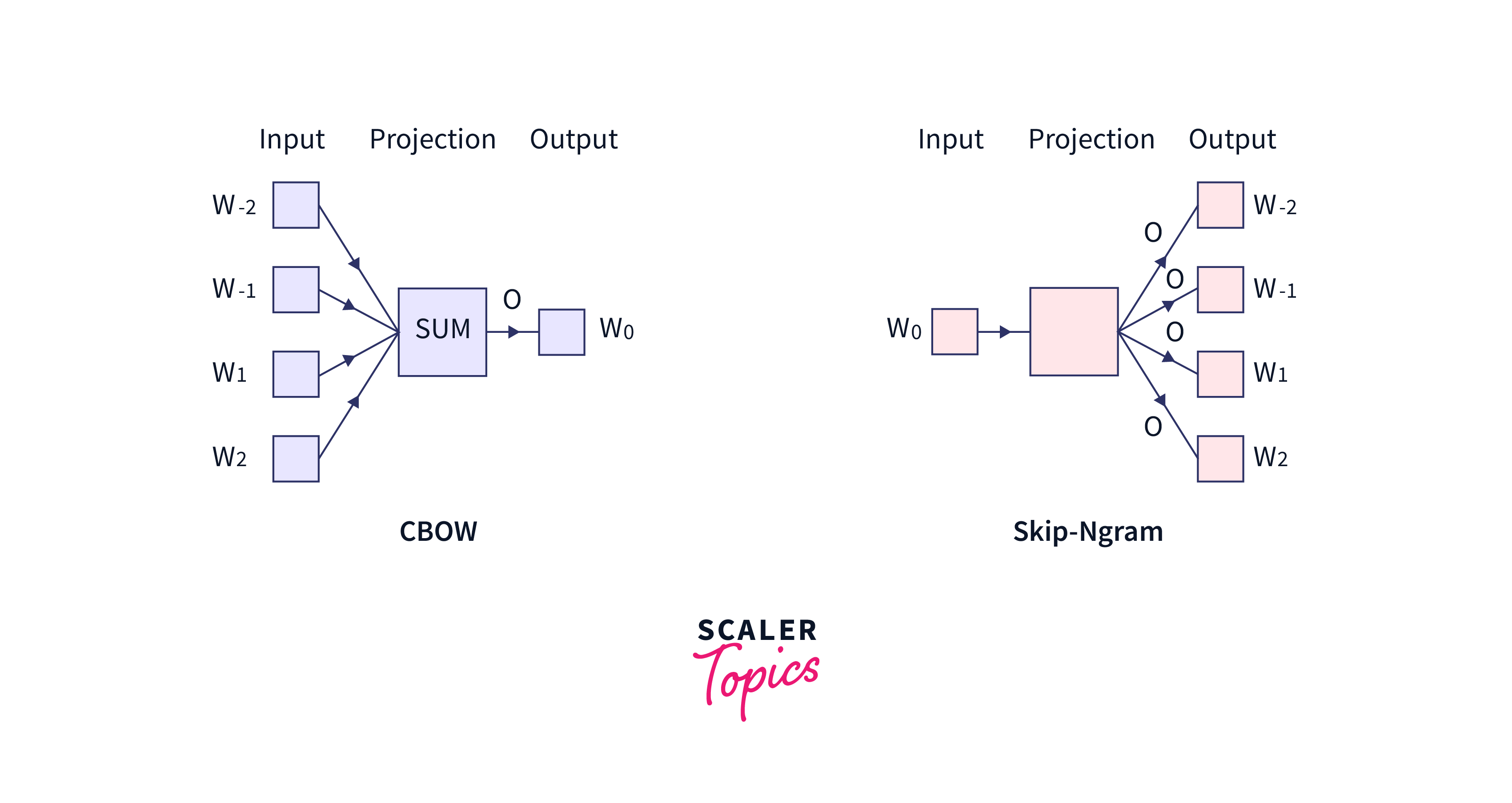 Here's how Skip-gram works:
Here's how Skip-gram works:
- Input:
A target word (e.g., "cat"). - Output:
A set of context words (e.g., "the," "sat," "on"). Skip-gram learns to capture the relationships between a target word and the words that typically surround it. While it might be slower to train than CBOW, it often produces better word embeddings, especially for infrequent words.
- Input:
The Skip-gram model tries to maximize the probability of the context words given the target word:

GloVe Model
The GloVe (Global Vectors for Word Representation) model is another widely used method for learning word embeddings, similar to Word2Vec. Developed by researchers at Stanford University, GloVe is designed to capture the global co-occurrence statistics of words in a large corpus of text. It excels at producing word embeddings that capture semantic relationships and word similarities.
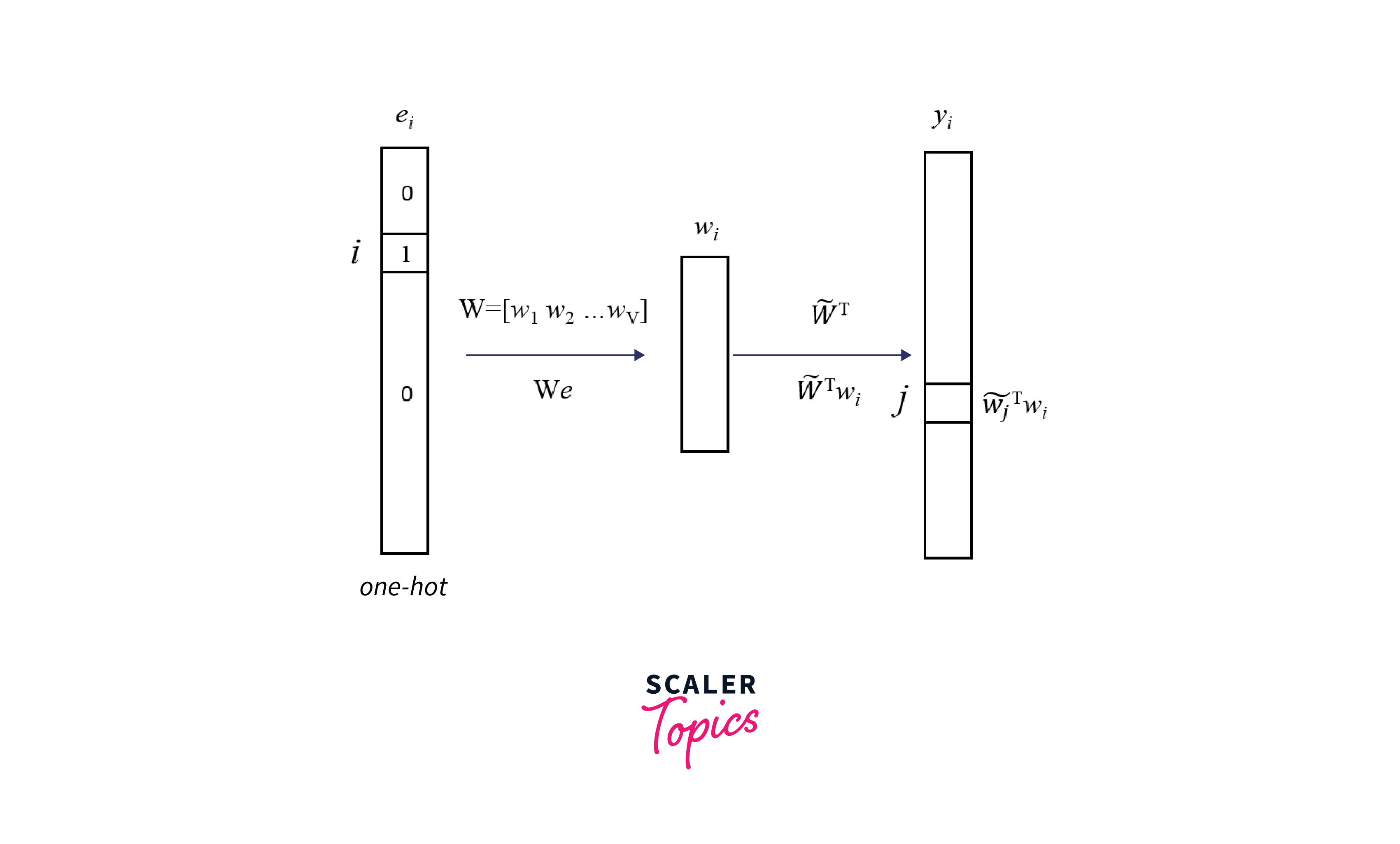
Here are the key aspects of the GloVe model:
- Co-Occurrence Matrix:
GloVe starts by constructing a global word-word co-occurrence matrix from a large corpus of text. Each entry in the matrix represents the number of times a word appears in the context of another word within a specific window size. The co-occurrence matrix effectively encodes how often words appear together in sentences, paragraphs, or documents. - Objective Function:
GloVe's training objective is to learn word vectors (embeddings) that are useful for predicting word co-occurrence probabilities. It does this by minimizing an objective function that quantifies the difference between the actual word co-occurrence probabilities and the predicted probabilities based on the word vectors. - Vector Arithmetic and Relationships:
Similar to Word2Vec, GloVe embeddings allow for vector arithmetic operations on words. For example, "king - man + woman" may yield "queen," showcasing GloVe's ability to capture semantic relationships and analogies. - Efficiency and Scalability:
GloVe is known for its efficiency and scalability. It can handle large text corpora and is designed to train relatively quickly compared to some other word embedding methods. - Pre-Trained Embeddings:
Pre-trained GloVe embeddings are available for various languages and corpus sizes. Researchers and practitioners often use these pre-trained embeddings as a starting point for various natural language processing tasks, such as text classification, sentiment analysis, and machine translation. - Hyperparameters:
Hyperparameters in the GloVe model, such as vector dimensionality, context window size, and the weighting function, significantly impact learned word embeddings. Vector dimensionality affects the granularity of semantic information, with higher dimensions capturing finer details but demanding more data. Context window size determines the scope of context considered, impacting contextual specificity. The weighting function influences how co-occurrence frequencies are weighted; linear weighting treats all word pairs equally, while non-linear options favour rare word relationships. The choice of hyperparameters should align with the specific NLP task and dataset characteristics, optimizing embeddings for tasks like semantic similarity, document classification, word sense disambiguation, and computational resources.
Word Embeddings in TensorFlow
TensorFlow, a prominent deep learning framework, offers robust support for working with word embeddings. You can utilize TensorFlow word embeddings for various purposes :
- Creating Custom Word Embeddings:
TensorFlow provides the flexibility to design and train custom TensorFlow word embeddings. By defining a neural network architecture that inputs text data, you can learn word representations tailored to your specific application. This is particularly useful when you have domain-specific data or unique embedding requirements. - Transfer Learning with Pre-trained Embeddings:
TensorFlow also offers pre-trained tensorflow word embeddings, including Word2Vec and GloVe. These pre-trained embeddings can be employed for transfer learning, allowing you to leverage the knowledge encapsulated in these embeddings. By initializing your NLP model with pre-trained embeddings, you can fine-tune it for specific tasks, saving time and resources. - Text Classification:
TensorFlow facilitates the construction of text classification models that leverage word embeddings. These models can classify text, such as sentiment analysis, spam detection, or topic classification, with the help of tensorflow word embeddings to capture context and meaning. - Sequence-to-Sequence Tasks:
Sequence-to-sequence models can be enhanced with tensorflow word embeddings for tasks like machine translation or text summarisation. This integration enhances translation quality and content summarization by enabling the model to understand the semantics of words and their relationships.
Output
Transfer Learning with Word Embeddings
Transfer learning with word embeddings is a powerful technique in natural language processing (NLP). It involves using pre-trained tensorflow word embeddings to enhance the performance of NLP models on particular tasks, even when you have limited training data. This approach leverages the knowledge captured by embeddings trained on large text corpora and transfers it to your NLP task. In this section, we'll explore the concept of transfer learning with tensorflow word embeddings and provide a code example using Python.
- Why Use Transfer Learning with Word Embeddings?
- Transfer learning with word embeddings offers several advantages:
- Reduced Data Requirements:
By starting with pre-trained embeddings, you require less labelled data for your specific task, which is especially valuable when annotated data is scarce or expensive to obtain. - Faster Convergence:
Pre-trained embeddings provide a solid starting point for your model. Training from scratch can be time-consuming and require extensive computational resources, while transfer learning speeds up the process. - Improved Generalization:
Pre-trained embeddings capture semantic relationships between words, leading to better generalization and model performance on a wide range of tasks. - Domain Adaptation:
If you have domain-specific tasks, you can fine-tune pre-trained embeddings on data from your domain, further enhancing their relevance to your application.
- Reduced Data Requirements:
- Transfer learning with word embeddings offers several advantages:
Code Example:
Transfer Learning with Pre-trained Word Embeddings in TensorFlow. In this code example, we'll use pre-trained GloVe embeddings to enhance the performance of a text classification model for sentiment analysis. We'll fine-tune the embeddings on our specific dataset.
- Step 1:
Here below, first, we import the necessary libraries, and then We tokenize and padd the text data. - Step 2:
Here, We load pre-trained GloVe embeddings (you should download the GloVe embeddings file and specify its path). We create an embedding matrix, mapping our vocabulary to the pre-trained embeddings. - Step 3:
The model architecture includes an embedding layer initialized with the pre-trained embeddings, followed by a global average pooling layer and a dense layer for binary classification.We train the model on our sentiment analysis task using the pre-trained embeddings and fine-tune them during training.Output
Evaluation and Visualization
Evaluation and visualization are critical steps in understanding the performance of machine learning models, including those for natural language processing (NLP). In this section, we'll discuss how to evaluate NLP models and visualize their results. We'll cover common evaluation metrics and techniques for visualizing model performance.
- Accuracy:
Accuracy is a common metric for classification tasks. It measures the proportion of correctly predicted labels among all predictions. However, it may not be the best metric for imbalanced datasets. - Precision:
Precision measures the proportion of true positive predictions among all positive predictions. It's valuable when false positives are costly. It's calculated as TP / (TP + FP). - Confusion Matrix Heatmap:
Visualize the confusion matrix as a heatmap to easily identify patterns of correct and incorrect predictions. - ROC Curve:
In binary classification problems, plot the Receiver Operating Characteristic (ROC) curve to visualize the trade-off between true positive rate (TPR) and false positive rate (FPR) at different decision thresholds. - Recall:
Sensitivity or true positive rate, measures the proportion of true positives among all actual positives. It's useful when false negatives are costly. It's calculated as TP / (TP + FN). - F1-Score:
The harmonic mean of precision and recall. It provides a balanced measure of model performance. It's calculated as 2 * (Precision * Recall) / (Precision + Recall). - Confusion Matrix:
A confusion matrix visualizes model performance by showing the counts of true positives, false positives, true negatives, and false negatives. It's especially helpful for understanding the types of errors the model makes.
Output
Conclusion
- Word embeddings, such as Word2Vec and GloVe, have transformed the landscape of natural language processing (NLP).
- TensorFlow Word embeddings enable machines to grasp the semantics and context of words.
- Seamless integration for working with tensorflow word embeddings, making it easier for developers to create custom embeddings, use pre-trained ones, and build NLP models with efficiency.
- Leveraging pre-trained embeddings allows NLP practitioners to enhance model performance, even with limited data.