Word2Vec with TensorFlow
Overview
Word2Vec is a popular word embedding technique that has gained significant attention in the field of natural language processing. With the rise of deep learning and the need to represent textual data in a meaningful way, Word2Vec has become a crucial tool for tasks such as text classification, sentiment analysis, and machine translation.
What is Word2Vec?
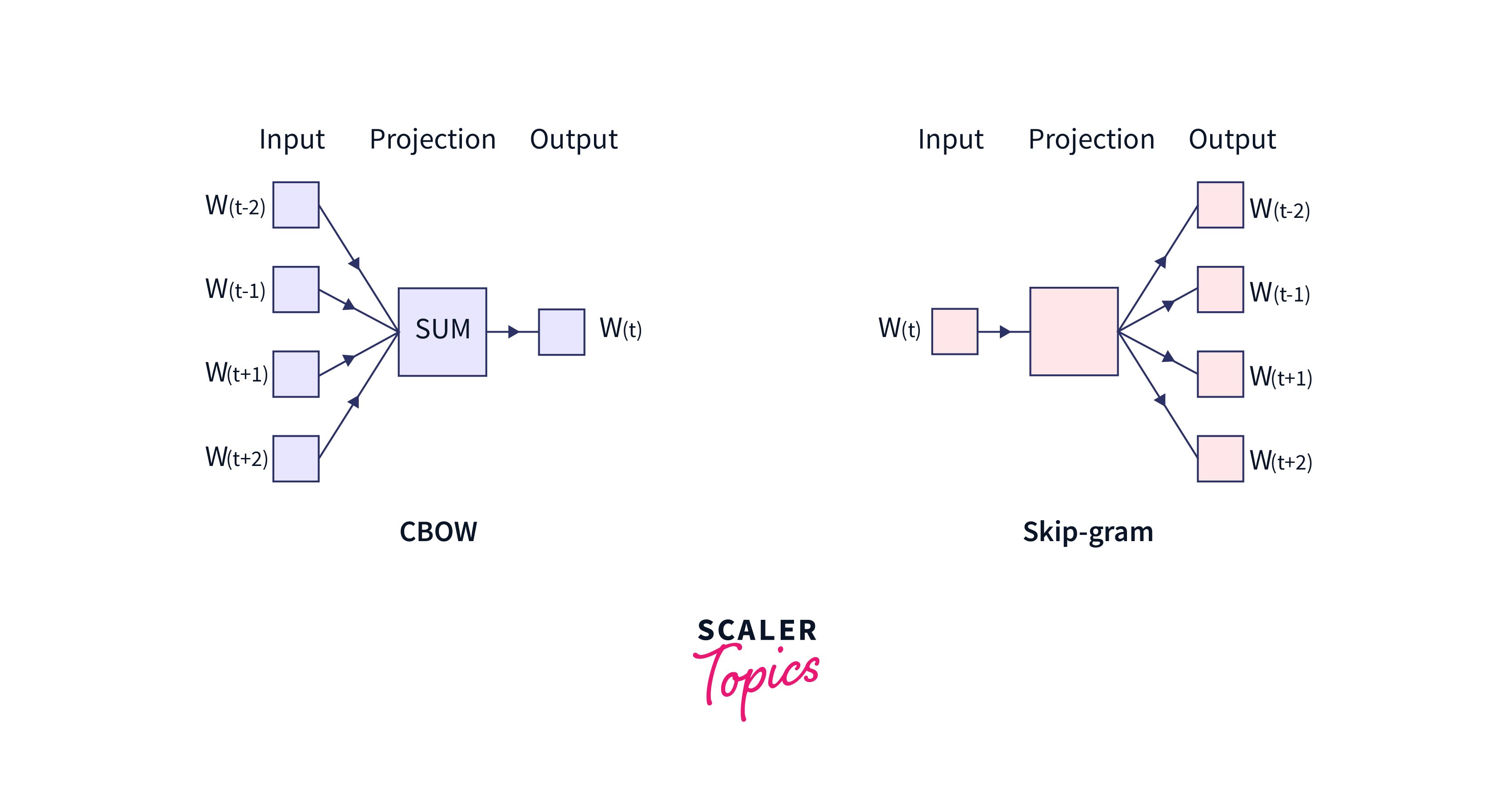
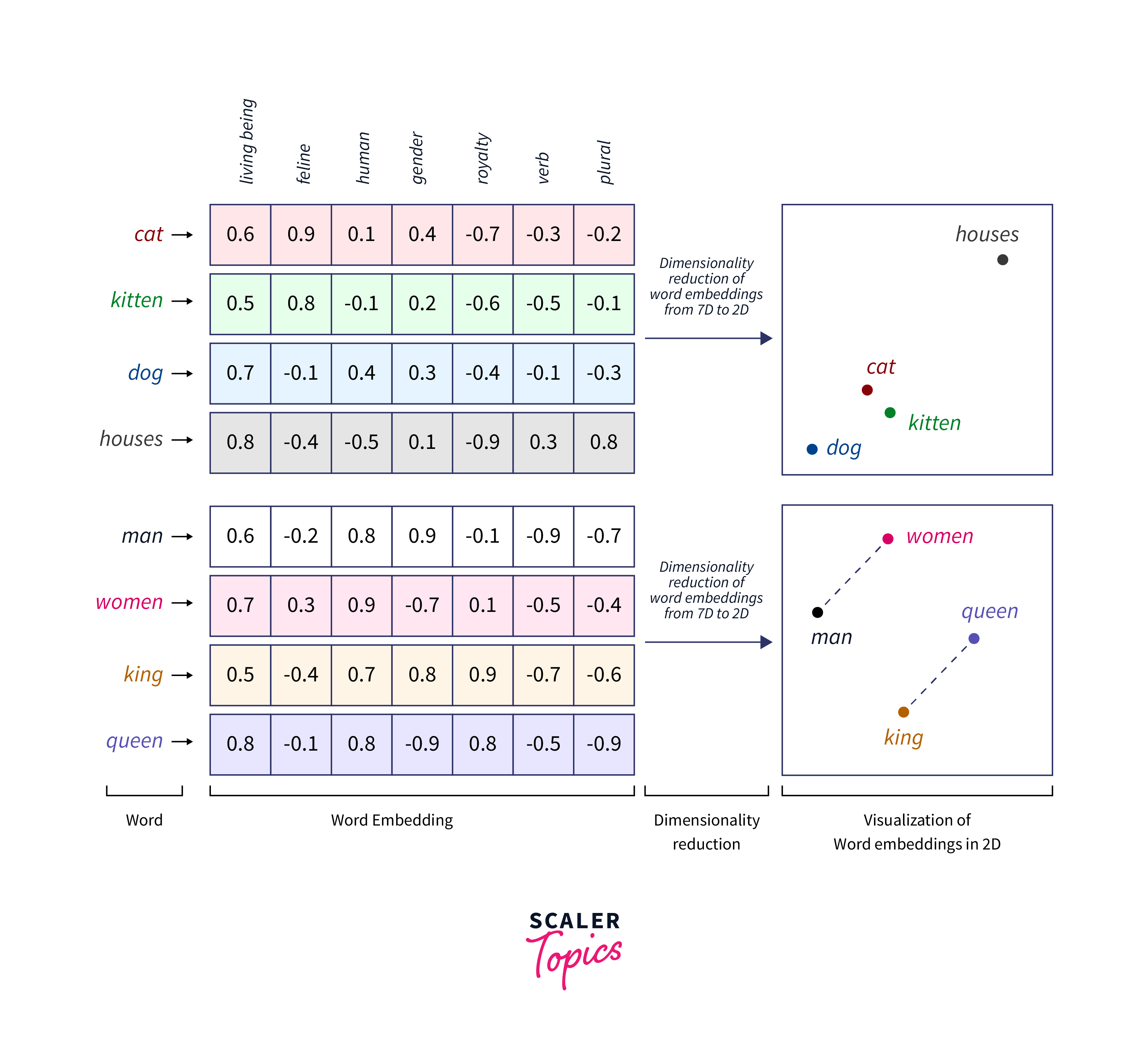
Word2Vec is a neural network model that is used to generate word embeddings, which are dense numerical representations of words that capture semantic relationships between them. The basic idea behind Word2Vec is to learn these embeddings by training a neural network on a large corpus of text data.There are two main architectures for training Word2Vec: CBOW (Continuous Bag-of-Words) and Skip-gram.
Word2Vec has several advantages over traditional bag-of-words and one-hot encoding representations.
- Firstly, it can capture semantic relationships between words, allowing for more meaningful comparisons and calculations.
- Secondly, it can handle out-of-vocabulary words by learning similar representations of words that appear in similar contexts.
- Finally, the word embeddings generated by Word2Vec can be used as input features for downstream tasks such as text classification, sentiment analysis, and machine translation.
For Example,If you want to perform a task like sentiment analysis or text classification on a large dataset of weather-related text. With Word2Vec embeddings, you can leverage the semantic similarity information to improve your model's performance. For instance, you can recognize that "cloudy" and "rain" are related in the context of weather discussions, and this knowledge can help the model make more accurate predictions. In contrast, traditional bag-of-words representations may not capture this relationship, making it harder for the model to generalize effectively.

Word2Vec Model Overview
Now that we have a basic understanding of what Word2Vec is, let's delve deeper into the model itself. As mentioned earlier, Word2Vec has two main architectures: CBOW and Skip-gram. Let's take a closer look at each one.
- CBOW (Continuous Bag-of-Words):
In CBOW, the model aims to predict the target word by considering the context words surrounding it. It takes a sequence of context words as input and tries to predict the target word. This architecture is useful when you have large text datasets and want to capture the overall meaning of a sentence.
- Skip-gram:
Unlike the CBOW architecture, Skip-gram takes a target word as input and tries to predict the context words. This architecture is beneficial when you want to capture more specific semantic relationships between words, especially in scenarios where you have less training data.
Both architectures share the same basic structure of a neural network with a single hidden layer. The hidden layer serves as the word embedding layer, where words are represented as dense numerical vectors.
Training Word2Vec Models in TensorFlow
Now that we have a solid understanding of the Word2Vec model architectures, let's dive into the implementation of Word2Vec using TensorFlow.
- Preparing the Data To train a Word2Vec model in TensorFlow, we first need a corpus of text data. This can be any large collection of text, such as novels, articles, or even social media posts. The more data we have, the more accurate our word embeddings will be.
We'll start with a sample corpus, but you can replace it with your own text data. The first step is tokenization, where we split sentences into individual words and assign each word a unique integer ID. We'll use the Tokenizer class from TensorFlow for this purpose:
- Generating Context-Target Pairs In Word2Vec, we train the model to predict context words based on a target word. To do this, we need to generate context-target pairs from our tokenized sequences. We'll define a window size that determines the range of words considered as context for each target word. Here, we use a window size of 2:
- Data Preparation for Training Next, we convert these context-target pairs into the input (X) and output (y) data that our neural network will use for training. We convert the integer word IDs to one-hot encoded vectors using TensorFlow utilities:
- Building the Word2Vec Model
Now, it's time to define the Word2Vec model architecture using TensorFlow's Keras API. We'll use an embedding layer to map words to dense vectors, a flattening layer to prepare the output for the dense layer, and a dense layer with a softmax activation function to predict the context words:
- Training the Word2Vec Model With our model defined, we can now train it on the context-target pairs we generated earlier. You can adjust the number of training epochs based on your specific dataset and computational resources:

- Extracting Word Embeddings
Once the model is trained, we can extract word embeddings for specific words. To do this, we access the weights of the embedding layer and retrieve the embedding vector for a target word:

Once the model is trained, we can access the trained word embeddings, which are dense numerical vectors that capture the semantic meaning of each word. These embeddings can be used in various natural language processing (NLP) tasks, such as sentiment analysis, text classification, or even recommendation systems.
Hyperparameter Tuning for Word2Vec Models
To get the best performance out of our Word2Vec models, it's crucial to tune the hyperparameters. These are the settings that control the behavior of the model during training. By fine-tuning these hyperparameters, we can improve the quality of our word embeddings and consequently enhance the performance of downstream NLP tasks.The most important hyperparameters to consider when training Word2Vec models are the vector dimensionality, window size, and learning rate.
- Embedding Dimension: The vector dimensionality determines the size of the word embeddings, typically ranging from 100 to 300 dimensions. A larger vector dimensionality can capture more nuanced semantic information but may require more training data.
- Window Size: The window size defines the context window around each word that the model considers during training. A larger window size allows the model to capture more context but may also introduce more noise. While a smaller window size focuses on capturing immediate context and can be useful for tasks like named entity recognition.
- Learning Rate and Optimizer: The learning rate controls the step size of the optimization algorithm during training. A higher learning rate can lead to faster convergence but too high can result in overshooting and instability. Conversely, a lower learning rate can prevent overshooting but may slow down the training process.
Other hyperparameters to consider include the number of negative samples, which affects the model's ability to discriminate between target and negative samples, and the subsampling rate, which determines the frequency of rare words that the model will discard during training.
To tune these hyperparameters, we can use techniques like grid search or random search. Grid search involves trying out different combinations of hyperparameters and selecting the one that yields the best performance. Random search, on the other hand, randomly samples a set of hyperparameters and evaluates their performance.
Evaluating Word2Vec Models
Now that we have learned about hyperparameter tuning for Word2Vec models, it's time to understand how we can evaluate the performance of these models. Evaluating our Word2Vec models is essential to ensure that they are generating high-quality word embeddings that accurately represent the semantic relationships between words.
-
One common evaluation metric for Word2Vec models is word similarity. Word similarity measures how well the word embeddings capture the semantic similarity between pairs of words. We can use pre-existing word similarity datasets, such as WordSim-353 or SimLex-999, to calculate the similarity scores between the word embeddings produced by our models and the human-labeled similarity scores in the dataset.
-
Another evaluation metric is word analogy. Word analogy tasks involve completing the analogy "A is to B as C is to __."
Example:
"man is to woman, as king is to __." The model should be able to generate the correct word to complete the analogy based on the learned word embeddings. We can evaluate the performance of our Word2Vec models on word analogy tasks using datasets like Google's Word Analogy Test Set.
Additionally, we can evaluate the performance of our Word2Vec models on downstream NLP tasks, such as sentiment analysis, text classification, or named entity recognition. By using the word embeddings as input features to these tasks, we can assess how well the word embeddings contribute to the overall task performance.
Utilizing Word2Vec Word Embeddings
Now that we have learned about evaluating Word2Vec models, let's explore how we can leverage the word embeddings generated by these models in various NLP applications. The word embeddings produced by Word2Vec capture the semantic relationships between words, making them useful for a wide range of tasks.
-
One common application of Word2Vec word embeddings is in information retrieval systems. By representing words as dense vectors, Word2Vec enables more accurate matching of search queries to relevant documents. This can significantly improve the performance of search engines by returning more relevant results.
-
Another popular use case for Word2Vec word embeddings is in natural language understanding tasks. These tasks, such as question answering or chatbot development, require a deep understanding of language semantics. By utilizing the semantic information encoded in the word embeddings, we can enhance the performance of these systems and improve their ability to provide accurate and meaningful responses.
-
Furthermore, Word2Vec word embeddings can be valuable in machine translation tasks. By mapping words from one language to another based on their semantic similarities, Word2Vec can aid in producing more accurate translations and improving the overall quality of machine translation systems.
Transfer Learning with Pretrained Word2Vec Models
Transfer learning has gained popularity in the field of deep learning for its ability to leverage preexisting models and adapt them to new tasks. Similarly, we can apply transfer learning techniques to Word2Vec word embeddings to create powerful models for specific NLP applications.
One approach to transfer learning with Word2Vec is to use pretrained models. These models are trained on large corpora and capture general semantic relationships between words. By initializing our model with these pretrained embeddings, we can benefit from the knowledge and insights captured from a vast amount of text data.
we will explore how to utilize pretrained Word2Vec models in our NLP tasks. We will discuss techniques such as model freezing, fine-tuning, and domain adaptation to improve the performance and adaptability of our models. Additionally, we will explore popular pretrained Word2Vec models available and provide step-by-step instructions on how to integrate them with TensorFlow.
Conclusion
Word2Vec is a powerful word embedding technique that captures semantic relationships between words and has numerous applications in natural language processing.
- Word2Vec Significance:
- Word2Vec is a crucial word embedding technique in natural language processing (NLP).
- It captures semantic relationships between words, enabling meaningful comparisons and calculations.
- Word2Vec Architectures:
- Word2Vec offers two main architectures CBOW and Skip-gram, each suited for different data sizes and context needs.
- Training Word2Vec in TensorFlow:
- Data preparation involves tokenization and sequence generation.
- Context-target pairs are created to train the Word2Vec model.
- Hyperparameter tuning, including embedding dimension and window size, is essential for model performance.
- Evaluation Metrics:
- Word similarity and analogy tasks assess how well Word2Vec embeddings capture semantic relationships.
- Downstream NLP tasks, like sentiment analysis, can also be used for evaluation.
Word2Vec remains a valuable tool for enhancing text representations and improving NLP applications. Word2Vec is a versatile and impactful technique in NLP, offering benefits in various applications and supporting transfer learning for domain-specific tasks. Proper