TensorFlow Data Loaders
Overview
The TensorFlow Data API, often referred to as tf.data, is a powerful tool for efficient data loading and preprocessing in TensorFlow. It provides a high-level interface for creating data loaders that can handle large datasets and seamlessly integrate with TensorFlow models. In this article, we will explore the concept of TensorFlow Dataloaders and delve into the major benefits of using the TensorFlow Data API.
Introduction
In the field of machine learning and deep learning, working with large datasets is common. However, handling and preprocessing such datasets can be a daunting task. This is where TensorFlow Dataloaders come into play. Dataloaders are essential components that enable efficient loading, preprocessing, and batching of data, making it easier to train machine learning models. The TensorFlow Data API (tf.data) provides a convenient and efficient way to create Dataloaders for TensorFlow models.
Key Concepts: TensorFlow's Data API (tf.data) is indeed a powerful tool for efficiently loading, preprocessing, and batching data for machine learning and deep learning models. It offers a simple and flexible interface to handle large datasets with ease.
-
Dataset: A Dataset in TensorFlow is a sequence of elements (data points) that can be iterated upon. These elements can be tensors, NumPy arrays, or Python generators.
-
Transformation: TensorFlow's Data API allows you to apply various transformations to the datasets, such as mapping, filtering, shuffling, and batching, among others.
-
Dataloader: A Dataloader is an iterator over a Dataset that provides batches of data during model training. It efficiently loads and processes data on-the-fly, making it easy to handle large datasets that may not fit into memory.
What are tf.data dataloaders?
Dataloaders are utilities that facilitate the loading and preprocessing of data, making it ready for consumption by machine learning models.
- In TensorFlow, Dataloaders are created using the TensorFlow Data API (tf.data). They enable the efficient reading and processing of data from various sources, such as files, databases, or even real-time streams.
- Dataloaders handle operations such as shuffling, batching, and prefetching, allowing for seamless integration with TensorFlow models.
- These loaders are typically used in conjunction with the TensorFlow library to efficiently handle and feed data to the models during the training process.
Here is a table consisting of common TensorFlow DataLoader APIs:
| Data Loader API | Description |
|---|---|
| tf.data.Dataset | A powerful API for building efficient data pipelines. It allows you to create datasets from various sources and apply transformations for data preprocessing. |
| tf.data.experimental.CsvDataset | Specifically designed for reading CSV files and enables parsing, processing, and conversion into TensorFlow tensors. |
| tf.data.experimental.TFRecordDataset | Reads data from TFRecord files, which are commonly used for storing large amounts of data efficiently. |
| tf.keras.preprocessing.image.ImageDataGenerator | Part of the Keras API in TensorFlow, used for loading and augmenting image data, including directory reading and data augmentation. |
What are the major benefits of TensorFlow Data API (tf.data)?
The TensorFlow Data API (tf.data) offers several advantages for data loading and preprocessing:
-
Efficiency: tf.data provides optimized implementations for data preprocessing operations, such as shuffling, batching, and augmentation. It leverages parallel processing and prefetching techniques, resulting in faster data loading and improved overall training performance.
-
Flexibility: The TensorFlow Data API supports a wide range of data sources and formats. It allows for easy integration with existing data pipelines and provides flexibility in handling various data types, including images, text, and numerical data.
-
Scalability: TensorFlow Dataloaders are designed to handle large datasets efficiently. They can handle data distributed across multiple files or storage systems, making it possible to train models on datasets that do not fit entirely in memory.
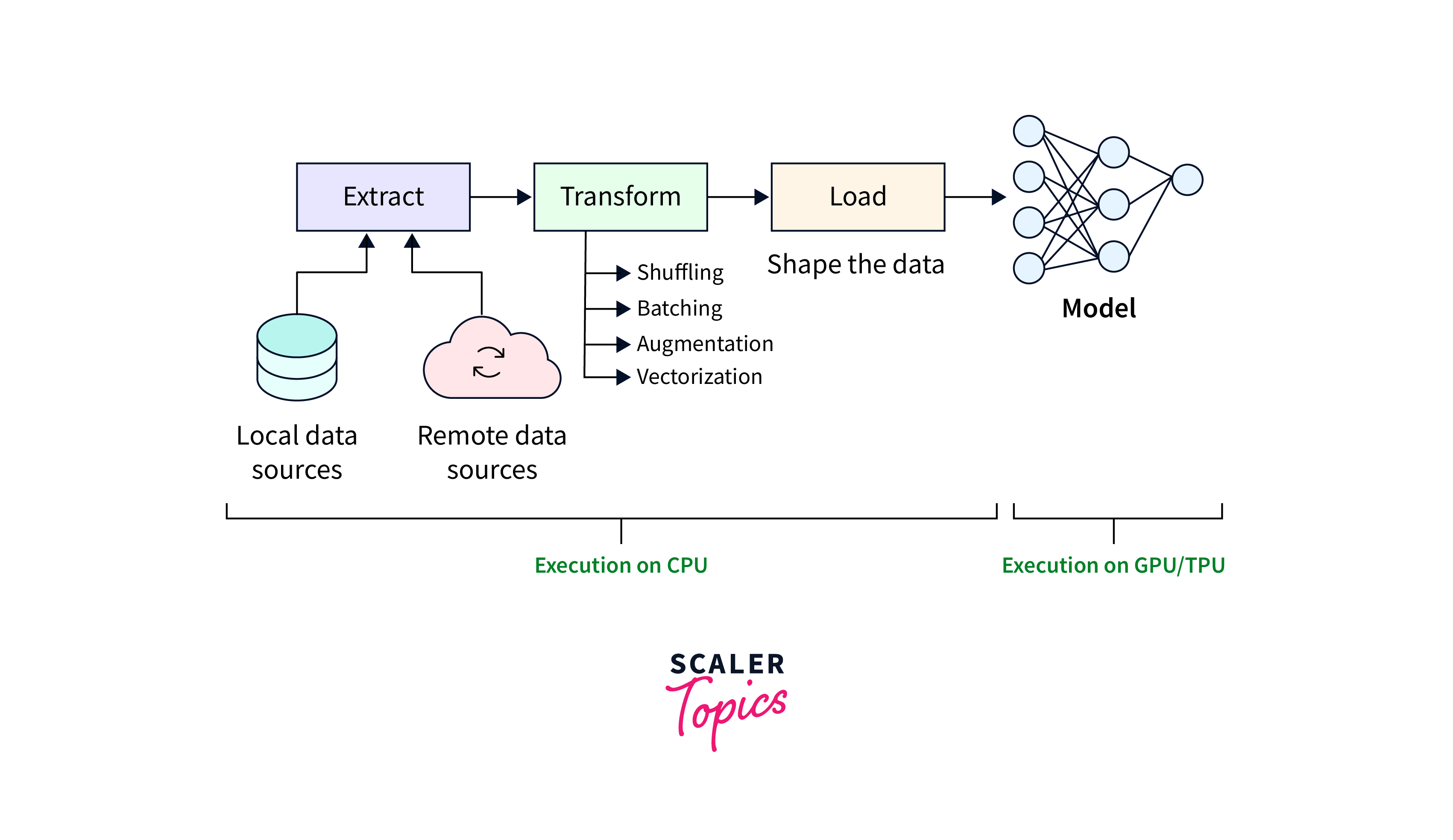
How to create a Data Loader using TensorFlow?
Data loading and preprocessing are crucial steps in training machine learning models. TensorFlow provides the powerful TensorFlow Data API (tf.data) to create efficient data loaders.
In this step-by-step guide, we will walk through the process of creating a data loader using TensorFlow, enabling seamless integration with TensorFlow models. We will cover key concepts and provide code examples to illustrate each step.
Step 1: Data Source: Identify the source of your data, which can be files, a database, or any other suitable format. In this example, we will assume that we have a directory containing image files.
Step 2: Preprocessing and Transformation: Preprocess and transform the data using TensorFlow operations. In our image data example, we will resize the images to a specific size.
Step 3: Create a Dataset: Use the TensorFlow Data API to create a Dataset object from the preprocessed data. The Dataset object represents the sequence of operations to be applied to the data.
Step 4: Configure the Data Loader: Configure the Dataset object with options such as batch size, shuffling, and prefetching. These options optimize the data loading process and improve training performance.
Step 5: Iterate and Use the Data Loader: Now that the data loader is created, you can iterate over the dataset and use it for training or inference.
Creating a data loader using TensorFlow's Data API (tf.data) is a straightforward process that involves identifying the data source, preprocessing the data, creating a Dataset object, and configuring the data loader. By leveraging the capabilities of tf.data, you can efficiently load and preprocess data for seamless integration with TensorFlow models.
How to load image data using TensorFlow?
TensorFlow's image data loaders provide a convenient and efficient way to handle image data within your machine learning workflow. By simplifying the loading and preprocessing steps, you can focus more on building and training powerful models using the rich visual information contained within images.

Here are the steps to load image data using TensorFlow:
Step 1: Import the necessary libraries: Import the TensorFlow library to access its functions and classes.
Step 2: Define the path to the directory containing the image files: Set the image_dir variable to the path of the directory where the image files are located.
Step 3: Create a function to load and preprocess images: Define the load_and_preprocess_image() function, which takes a file path as input. Inside the function, use tf.io.read_file() to read the image file, and then use tf.image.decode_jpeg() to decode the image into a tensor.
Additional preprocessing steps, such as resizing or normalization, can be added to this function.
Step 4: Create a list of image file paths: Create a list of image file paths. Replace the example file names with the actual image file names or retrieve them programmatically using libraries like glob or os.
Step 5: Create a dataset from the list of image file paths: Use tf.data.Dataset.from_tensor_slices() to create a dataset from the list of image file paths. This creates a dataset where each element corresponds to an image file path.
Step 6: Use the map() function to apply the load_and_preprocess_image function: Apply the load_and_preprocess_image function to each element in the dataset using the map() function. This maps the preprocessing function to each image file path in the dataset, resulting in a dataset of preprocessed images.
Step 7: Iterate over the dataset to load and preprocess the images: Iterate over the dataset using a loop. Each iteration will load and preprocess one image from the dataset.
You can perform any necessary operations with the loaded and preprocessed image within the loop, such as passing it to a model for inference or further processing.
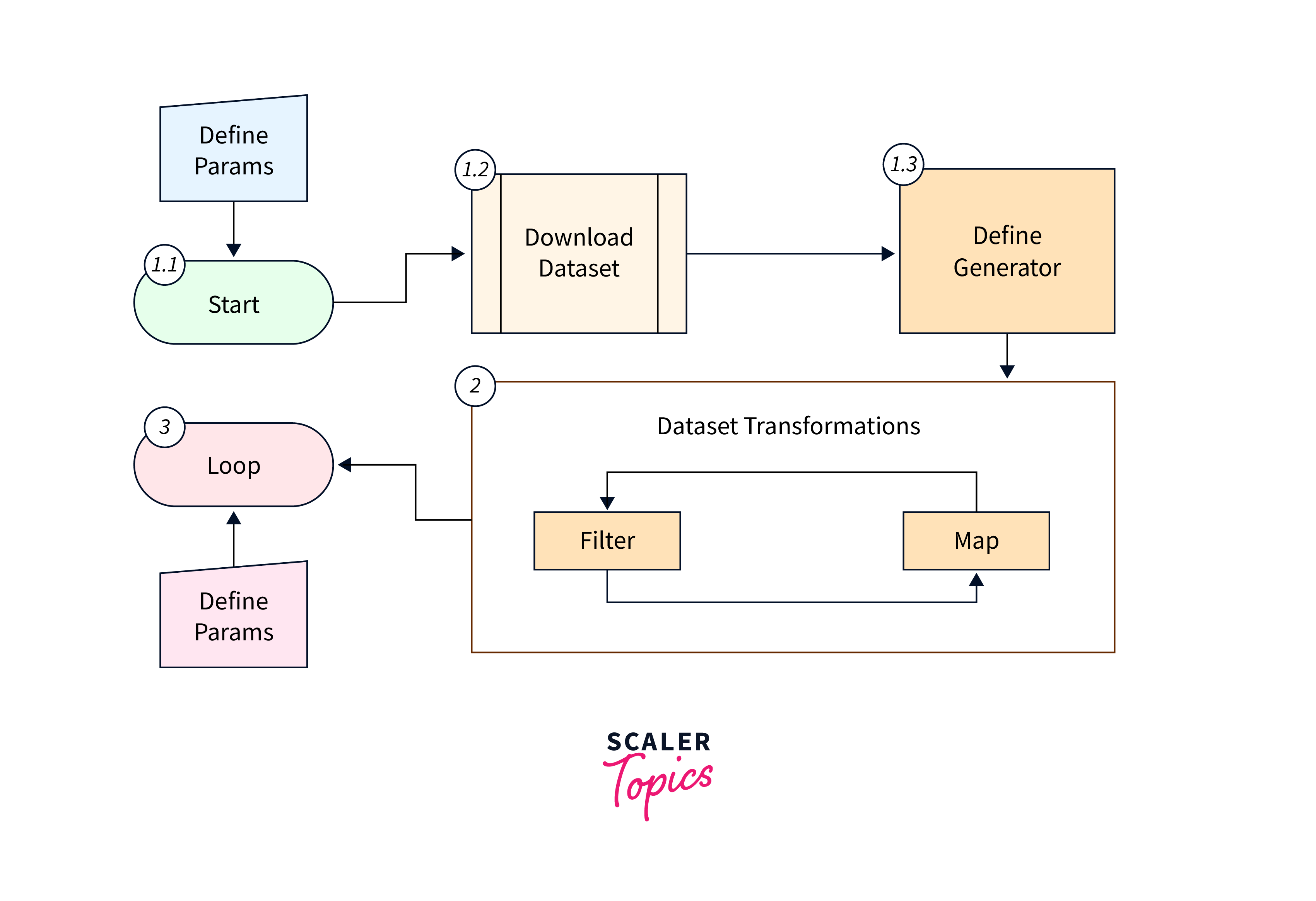
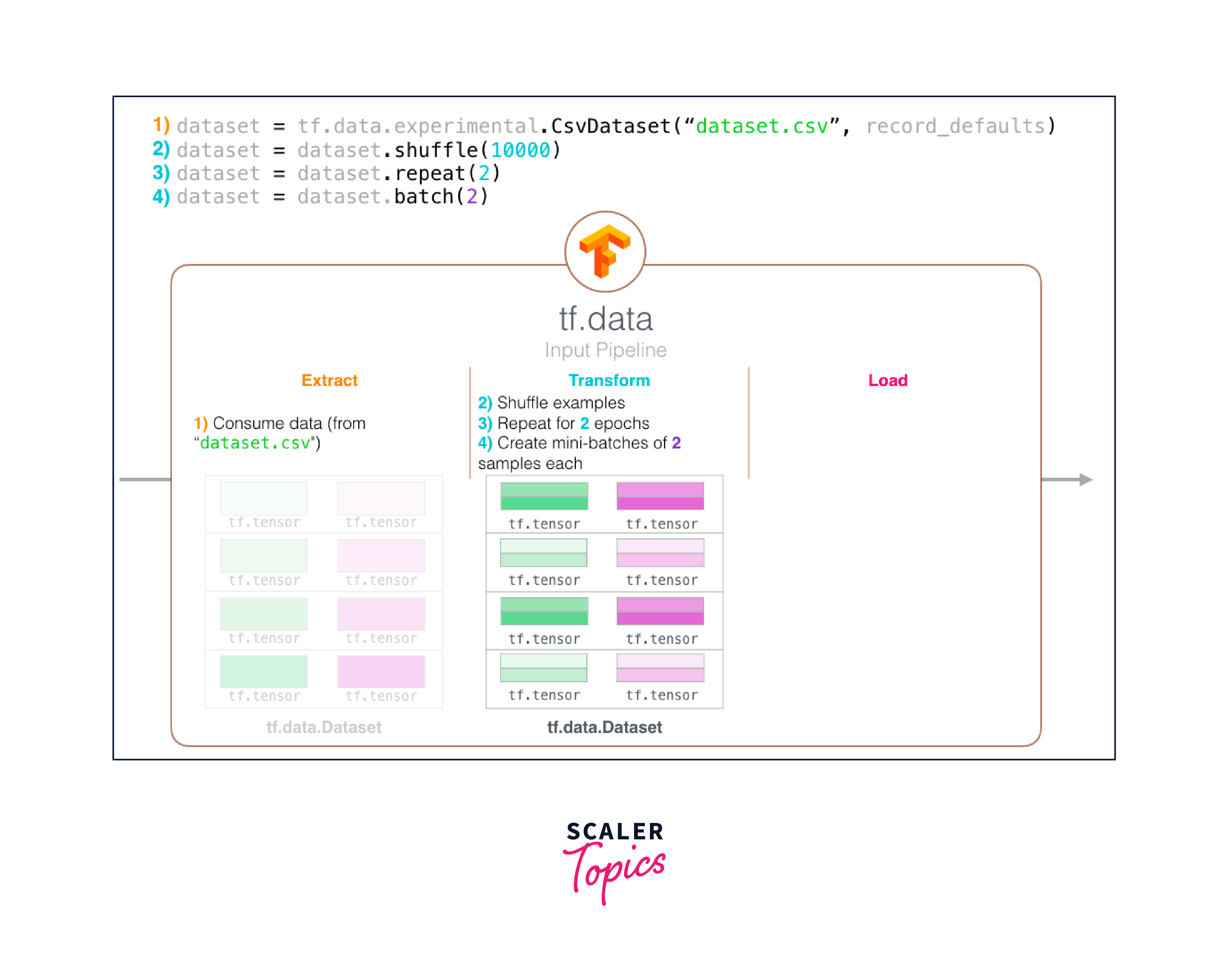
Creating datasets using tf.data
The tf.data module in TensorFlow provides a flexible and efficient way to create datasets for training and inference. It offers a variety of methods to create datasets from different data sources, including in-memory data, text files, CSV files, and more.
To create a dataset, you can use the following methods:
1. From Tensor Slices: The tf.data.Dataset.from_tensor_slices() method creates a dataset from tensor slices. It takes one or more tensors as input, and each tensor represents a separate element of the dataset.
2. From Numpy Arrays: The tf.data.Dataset.from_tensor_slices() method can also be used with NumPy arrays.
3. From Text Files: The tf.data.TextLineDataset() method creates a dataset from text files. Each line in the text file becomes an element in the dataset.
Batching and shuffling
Batching and shuffling are important operations when working with datasets in deep learning. Batching combines multiple consecutive elements of a dataset into a single batch, while shuffling randomly reorders the elements within the dataset. Both operations are often performed to improve training efficiency and prevent model overfitting.
To apply batching and shuffling to a dataset, you can use the following methods:
Batching
The tf.data.Dataset.batch() method is a convenient function in TensorFlow that allows you to group consecutive elements of a dataset into batches of a specified size. It is commonly used to create mini-batches for training neural networks.
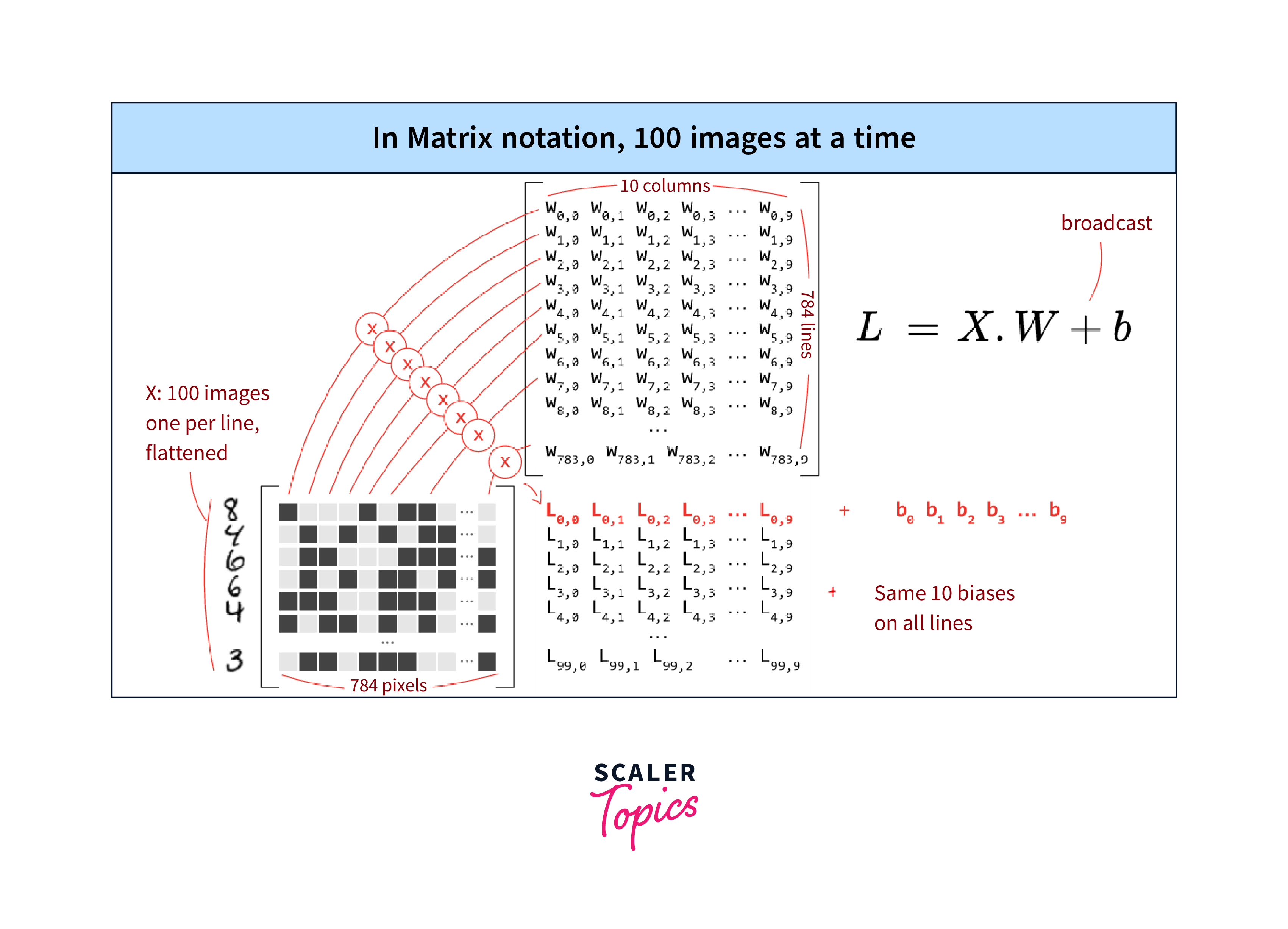
- The batch size represents the number of elements from the dataset that will be combined together to form a single batch. For example, if the batch size is set to 32, each batch will contain 32 consecutive elements from the dataset.
- Batching is essential for efficient and faster model training. By processing data in batches, TensorFlow can take advantage of parallelism and vectorization, which significantly speeds up the training process, especially on GPUs.
Here's an example of using tf.data.Dataset.batch() to create batches from a dataset:
Output:
Shuffling
The tf.data.Dataset.shuffle() method is used to shuffle the elements of a dataset, randomizing their order. The main purpose of shuffling is to introduce randomness into the data, which helps in preventing the model from memorizing the order of samples during training and promotes better generalization.
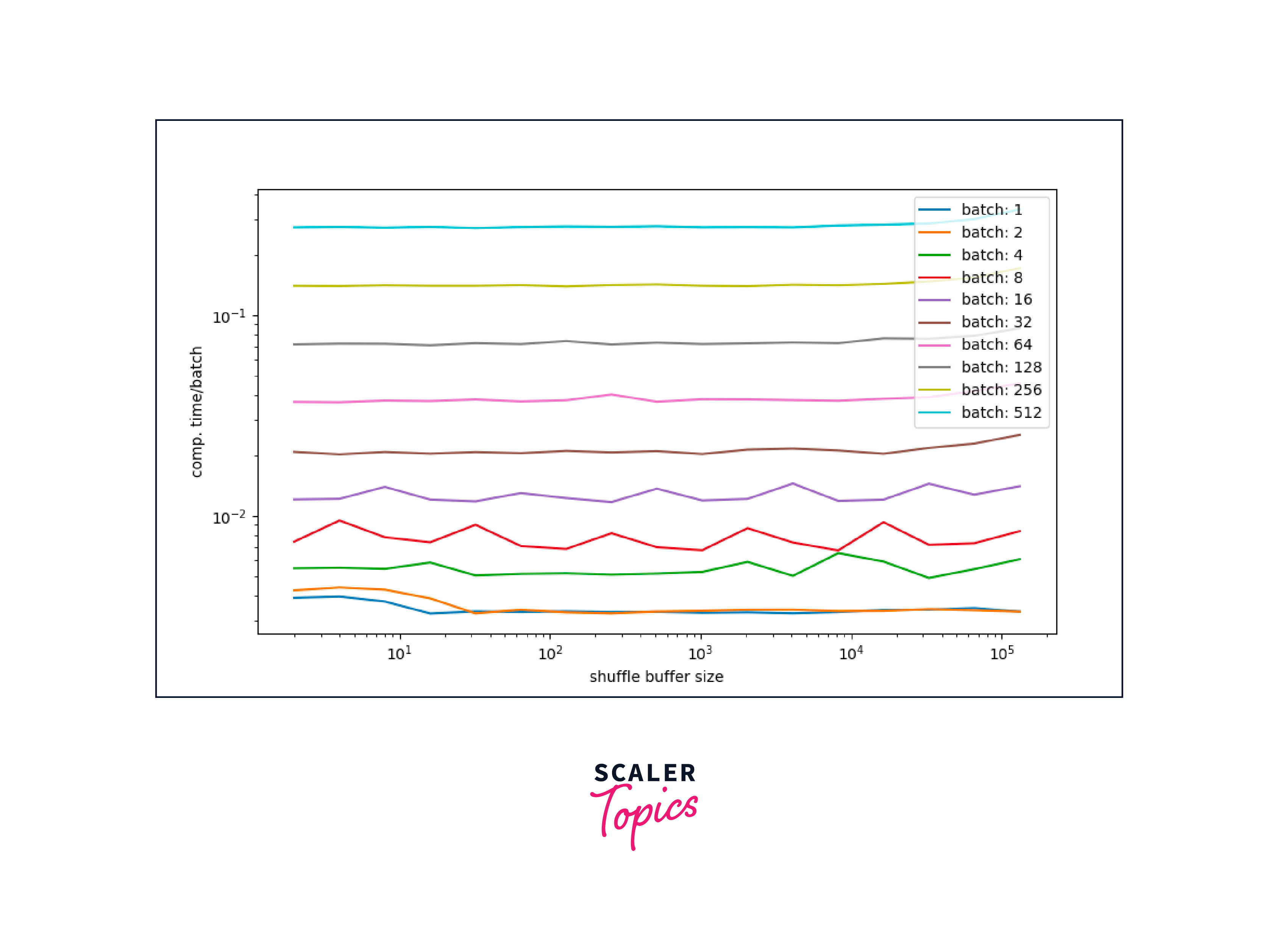
- The shuffle(buffer_size) parameter in this method determines the number of elements from the dataset that will be used to fill a buffer.
- When a new element is requested from the dataset, it is randomly sampled from this buffer.
- A larger buffer_size results in better shuffling; however, it requires more memory to store the elements.
- It is common to set the buffer_size to a value equal to or larger than the total number of elements in the dataset for effective shuffling.
Data Preprocessing
Data preprocessing is a crucial step in deep learning. The tf.data module provides various methods to preprocess the data within a dataset, such as mapping a preprocessing function to each element or applying operations like filtering or padding.
Overview of the steps: Here are the steps for data preprocessing using the tf.data module in short points:
- Creating a Dataset: Start by creating a tf.data.Dataset object, which serves as the foundation for data preprocessing in TensorFlow.
- Mapping Preprocessing Function: Use the map() method to apply a preprocessing function to each element in the dataset. This function can include operations like resizing images, normalizing numerical values, or tokenizing text.
- Shuffling the Data: To introduce randomness and reduce bias during training, shuffle the dataset using the shuffle() method. Specify a buffer size to determine the number of elements from which the next element is randomly sampled.
- Batching the Data: Group consecutive elements into batches using the batch() method. This is essential for efficient training, as it enables parallel processing and faster optimization.
- Filtering Data (Optional): If needed, you can filter the dataset based on certain conditions using the filter() method. This allows you to include or exclude specific elements based on custom criteria.
- Padding Sequences (Optional): For sequence data with varying lengths, use the padded_batch() method to ensure all sequences in a batch have the same length by padding with zeros or other specified values.
- Caching (Optional): For faster training on large datasets, consider caching the dataset using the cache() method. This stores elements in memory or on disk for quicker access during repeated iterations.
- Prefetching (Optional): Improve training efficiency by prefetching data using the prefetch() method. This allows the model to fetch data for the next batch while processing the current one, reducing data pipeline bottlenecks.
![Tensorflow data loaders]](https://www.scaler.com/topics/images/tensorflow-data-loaders8.webp)
Mapping a Preprocessing Function: The tf.data.Dataset.map() method allows you to apply a preprocessing function to each element in a dataset.
Filtering The tf.data.Dataset.filter() method filters elements from a dataset based on a given predicate function.
Apply Data Augmentation
Data augmentation is a technique used to artificially increase the size of the training dataset by applying various transformations to the existing data. TensorFlow's tf.data module provides a convenient way to apply data augmentation to a dataset using the map() method.
In the above code example, the dataset contains image file paths. The augment_data() function applies data augmentation transformations to each image and returns the augmented image file path. The map() method is then used to apply the data augmentation function to each element in the dataset.
- By utilizing the tf.data module in TensorFlow, you can create datasets, apply batching and shuffling, perform data preprocessing, and even apply data augmentation.
- These capabilities empowerdata scientists and researchers to efficiently prepare and augment their datasets for deep learning tasks.
- The flexibility and functionality provided by the tf.data module enable seamless integration with TensorFlow models, ensuring smooth and effective training and inference processes.

Handling Large Datasets
When working with large datasets, efficient handling becomes crucial to ensure effective training and utilization of computational resources. TensorFlow's tf.data module provides various techniques to handle large datasets seamlessly.
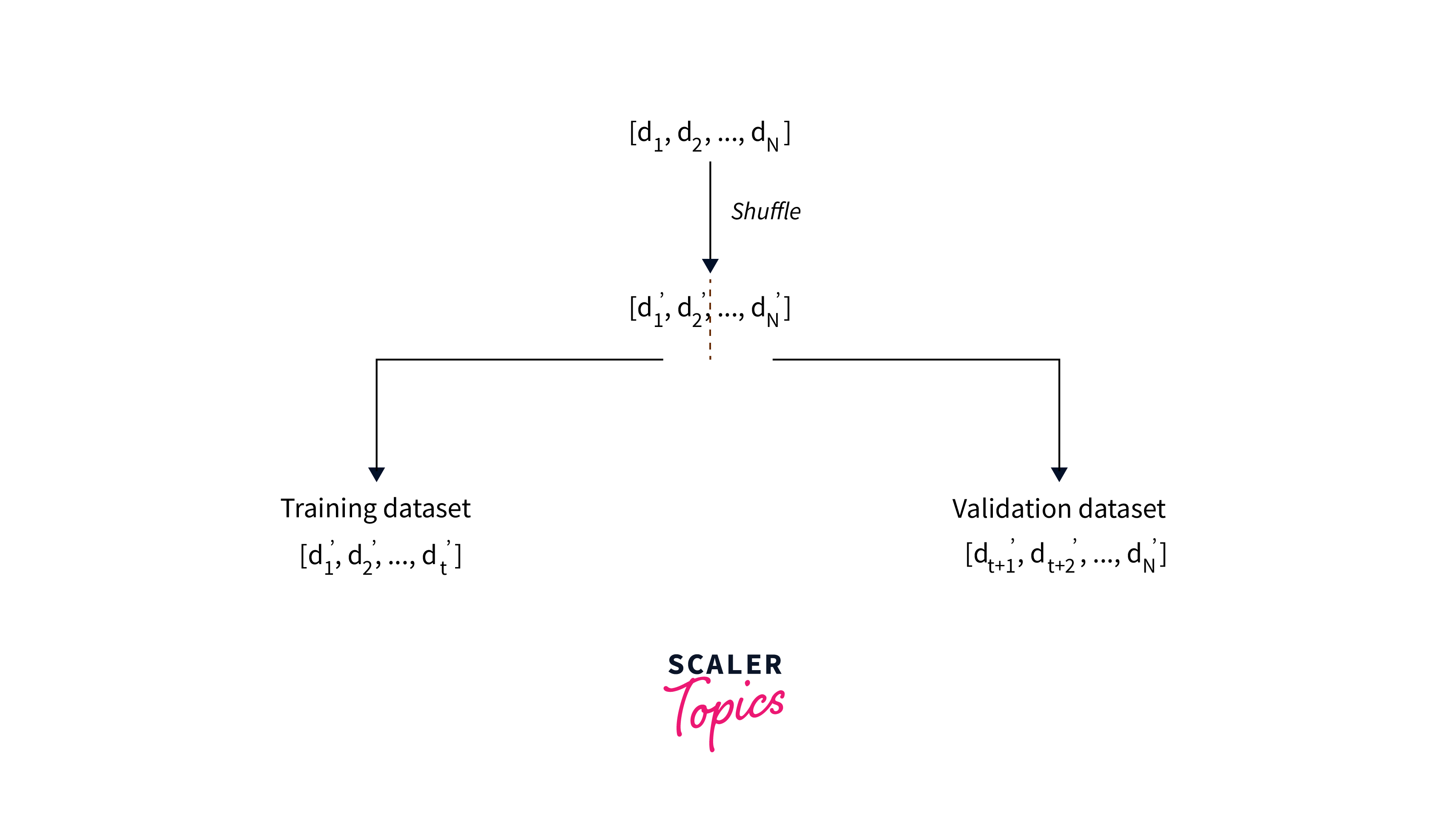
Let's explore strategies for efficiently handling large datasets using data loaders, along with techniques for shuffling, repeating, and batching data.
Techniques on Shuffling Data
Shuffling the dataset helps introduce randomness during training and prevents model overfitting. TensorFlow's tf.data module offers the shuffle() method to shuffle the elements of a dataset.
TensorFlow's tf.data module provides several techniques for shuffling data. Here are a few techniques to consider:
1. Basic Shuffling: The basic shuffling technique randomly shuffles the elements of the dataset using a fixed buffer size. It ensures that each element has an equal chance of being selected during shuffling.
Example:
In this example, the dataset is shuffled using a buffer size of 10,000. Adjust the buffer size based on the size of your dataset and the available memory.
2. Reshuffling: Reshuffling allows for repeated shuffling of the dataset after each epoch. This technique is particularly useful when the entire dataset cannot fit into memory and is loaded from disk.
Example:
In this example, the dataset is shuffled with a buffer size of 10,000 and then repeated for 10 epochs. Adjust the buffer size and the number of epochs based on your specific requirements.
3. Random Seed: To ensure reproducibility in shuffling, you can set a random seed. This allows you to obtain the same shuffled order every time the dataset is loaded.
Example:
In this example, the dataset is shuffled with a buffer size of 10,000 and a random seed of 42. Adjust the buffer size and seed as needed.
4. Time-Based Shuffling: Time-based shuffling is beneficial when dealing with time-series data, as it maintains the temporal ordering of the dataset while introducing randomness within each time window. TensorFlow's tf.data module provides the windowing technique to enable time-based shuffling.
Example:
In this example, the dataset is shuffled within time windows of size 100, with a shift of 10. Adjust the window size and shift based on your time-series data.
Repeating Data
To ensure that the entire dataset is used for training, you can repeat the dataset for multiple epochs. The repeat() method in tf.data allows you to repeat the dataset. Here's an example:
In this example, we create a dataset of integers ranging from 0 to 99. The repeat() method is applied to repeat the dataset for three epochs. Adjust the number of epochs based on your training requirements.
Batching Data Techniques
Batching data is a fundamental technique in data loading that groups consecutive elements of a dataset into batches. Batching enables parallel processing and improves training efficiency. TensorFlow's tf.data module provides several techniques for batching data. Here are a few techniques to consider:
1. Basic Batching: The basic batching technique combines consecutive elements of a dataset into fixed-sized batches. This is the simplest and most commonly used batching technique.
Example:
In this example, the dataset is batched with a fixed batch size of 32. Adjust the batch size based on your model's requirements and the available memory.
2. Dynamic Batching: Dynamic batching allows for more flexibility in batch size by automatically adapting the batch size based on the elements in the dataset. This is useful when dealing with variable-sized data or when the dataset size is not evenly divisible by the desired batch size.
Example:
In this example, the dataset is dynamically batched using padded_batch(), which ensures that each batch has elements of varying sizes padded to the maximum length within the batch. The padded_shapes argument specifies the shape of each element in the batch. Adjust the arguments according to the shape and size of your data.
3. Bucketing: Bucketing is a technique used when dealing with sequences of varying lengths. It groups sequences with similar lengths into buckets and batches them separately. This helps to minimize padding and improve training efficiency.
Example:
In this example, the dataset contains sequences of varying lengths. The sequences are grouped into buckets based on their lengths using group_by_window(), and then padded to the maximum length within each bucket using padded_batch(). Adjust the boundaries and padded shapes according to your sequence data.
4. Time-Based Batching: Time-based batching is beneficial when dealing with time-series data. It groups consecutive time steps into batches while maintaining the temporal order of the data.
Example:
In this example, the dataset is batched based on time windows. The window() method creates windows of size 100 with a shift of 10, and then the flat_map() method is used to flatten the windows and create batches of size 100. Adjust the window size and shift based on your time-series data.
These techniques can be combined and customized based on your specific needs and dataset characteristics. Experiment with different batching techniques to optimize training efficiency and memory usage while ensuring compatibility with your model's input requirements.
Example:
Let's combine shuffling, repeating, and batching techniques in an interactive example:
In this example, we shuffle the dataset with a buffer size of 1000, repeat it for three epochs, and create batches of size 10. We then iterate over the dataset and print each batch. Modify the buffer size, number of epochs, and batch size as per your dataset and training requirements.
By utilizing these techniques provided by the tf.data module, you can efficiently handle large datasets with data loaders. Shuffling, repeating, and batching your data ensure effective training by introducing randomness, using the entire dataset, and processing multiple samples in parallel.
Methods for Parallelizing data loading in TensorFlow
Efficiently parallelizing data loading and preprocessing is crucial for optimizing the performance of your deep learning models. TensorFlow provides several methods to achieve parallelism during data loading and preprocessing. Let's explore some of these methods:
1. Multi-threading: Multi-threading is a technique that utilizes multiple threads to load and preprocess data in parallel. TensorFlow's tf.data module supports multi-threading through the num_parallel_calls argument in methods like map, interleave, and prefetch. By setting num_parallel_calls to a value greater than 1, TensorFlow automatically parallelizes the data loading and preprocessing operations, leveraging the available CPU cores.
Example:
In this example, the map() method is used to apply the preprocess_function to each element in the dataset, and num_parallel_calls is set to tf.data.experimental.AUTOTUNE to enable automatic parallelism.
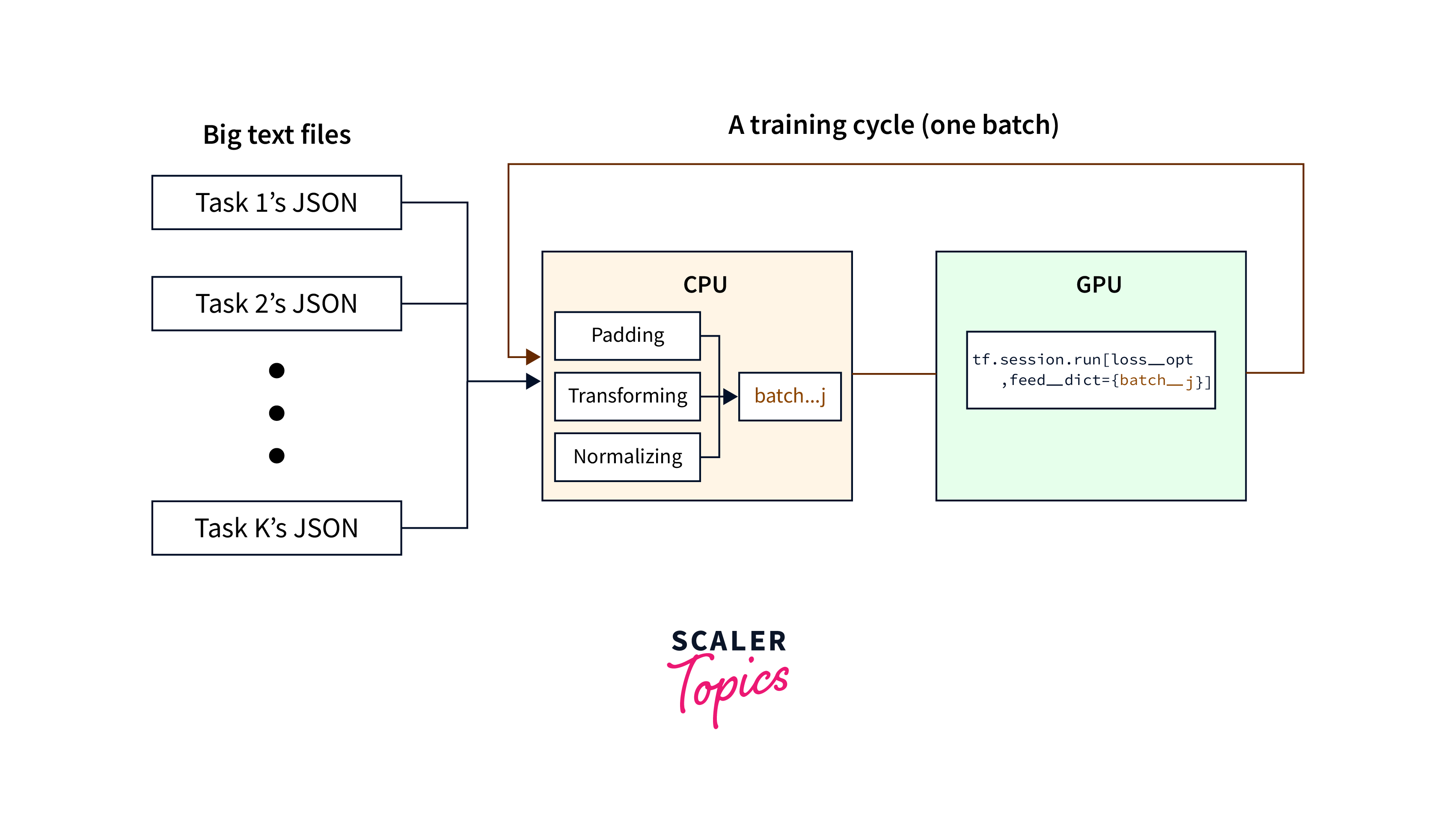
2. Interleaving: Interleaving is a technique that loads and preprocesses data from multiple input sources in parallel. TensorFlow's tf.data module provides the interleave() method, which interleaves elements from multiple datasets, enabling parallel loading and preprocessing.
Example:
In this example, multiple datasets (dataset1, dataset2, ...) are created, and the interleave() method is used to interleave elements from these datasets. The cycle_length parameter determines the number of datasets to load and preprocess in parallel.
3. Vectorization: Vectorization is a technique that leverages SIMD (Single Instruction, Multiple Data) instructions to perform computations on multiple elements simultaneously. TensorFlow's tf.data module provides vectorized operations, such as batch() and map(), that automatically exploit SIMD instructions for parallelism.
Example:
In this example, the batch() method is used to group elements into batches, and drop_remainder=True ensures that all batches have the same size. The map() method is then applied to each batch, and tf.data.experimental.AUTOTUNE enables automatic parallelism.
Advanced-Data Loading Techniques
Efficient data loading is critical for training deep learning models on large-scale datasets. As datasets continue to grow in size and complexity, advanced data loading techniques have emerged to optimize performance and overcome common challenges. Here, we discuss some advanced data loading techniques and their benefits in deep learning applications.
1. Parallelized I/O: Parallelized I/O involves distributing the data loading process across multiple threads or processes, enabling simultaneous reading of data from storage devices.
- This technique minimizes the I/O bottleneck and maximizes the utilization of I/O resources, leading to faster data loading.
- TensorFlow's tf.data module supports parallelized I/O through multi-threading, enabling efficient data loading from various data sources, such as local storage or network storage.
2. Caching: Caching involves storing preprocessed data in memory or on disk for quick retrieval during subsequent iterations.
- Caching is particularly useful when data preprocessing is computationally expensive.
- By caching the preprocessed data, subsequent epochs or iterations can directly access the cached data, saving preprocessing time and improving overall training efficiency.
- TensorFlow's tf.data module provides the cache() method to cache dataset elements in memory or on disk.
3. Pipelining: Pipelining is a technique that overlaps the data loading and preprocessing stages with model training or inference.
- By concurrently loading and preprocessing data while the model is training or inferring on the previous batch, pipelining minimizes the idle time of the computational resources, improving overall training throughput.
- TensorFlow's tf.data module offers methods like prefetch() and interleave() to facilitate pipelining by overlapping the stages of data loading, preprocessing, and model execution.
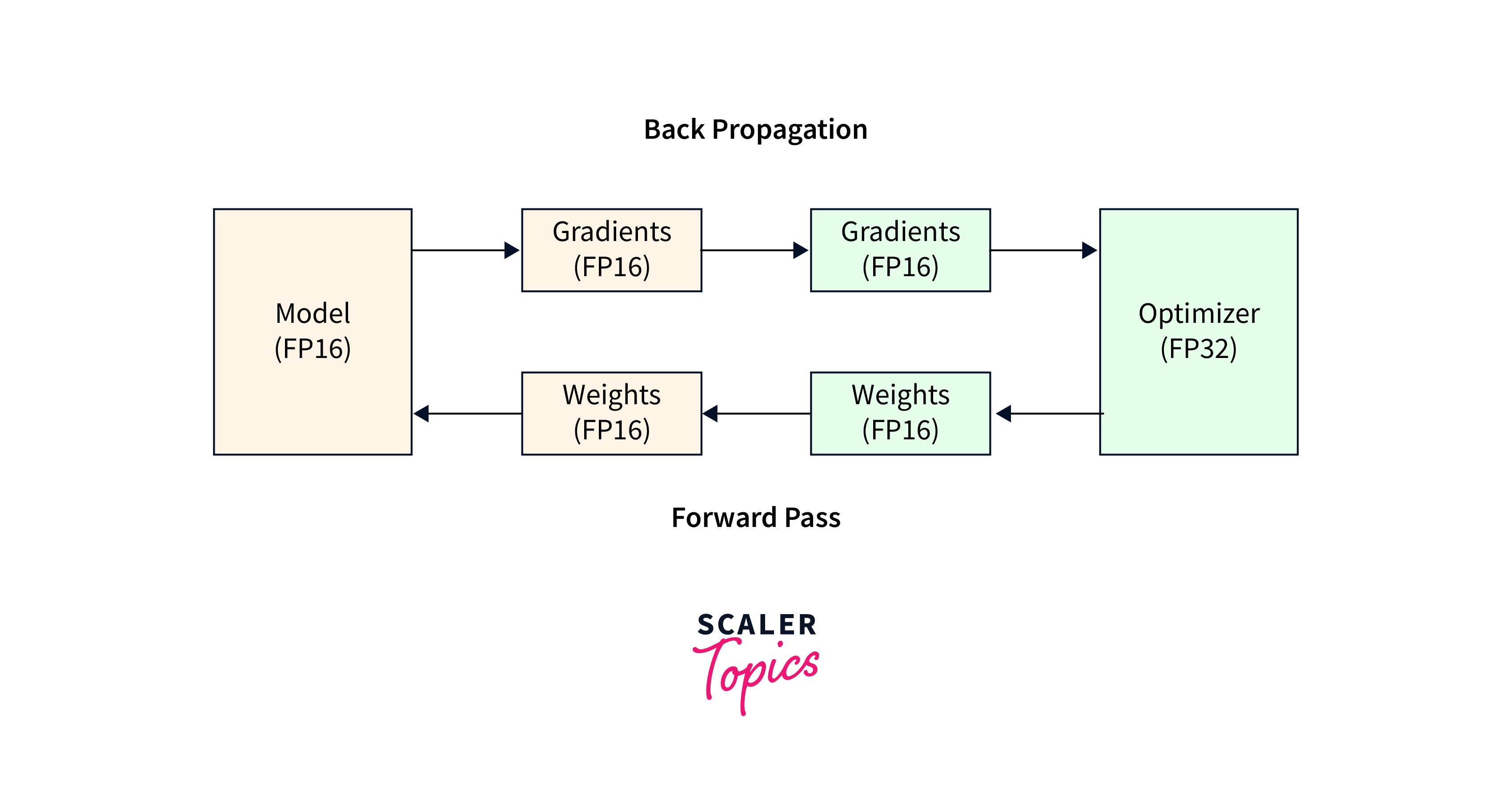
4. Mixed Precision Training: Mixed precision training is a technique that utilizes lower precision (e.g., half-precision floating-point) for certain parts of the training process while preserving accuracy.
- It can significantly accelerate training by leveraging hardware-specific capabilities of GPUs.
- In the context of data loading, mixed precision training can be applied during data loading and preprocessing, reducing the memory footprint and accelerating the overall training process.
- TensorFlow's tf.data module supports mixed precision training through data type conversion and the use of lower precision numerical representations.
5. Data Compression: Data compression techniques can be employed to reduce the storage space required for large datasets, making data loading more efficient.
- Compression techniques like gzip, zip, or other lossless compression algorithms can be applied to compress the dataset files.
- When using compressed data, it is essential to consider the trade-off between compression ratio and the additional computational overhead required for decompression during data loading.
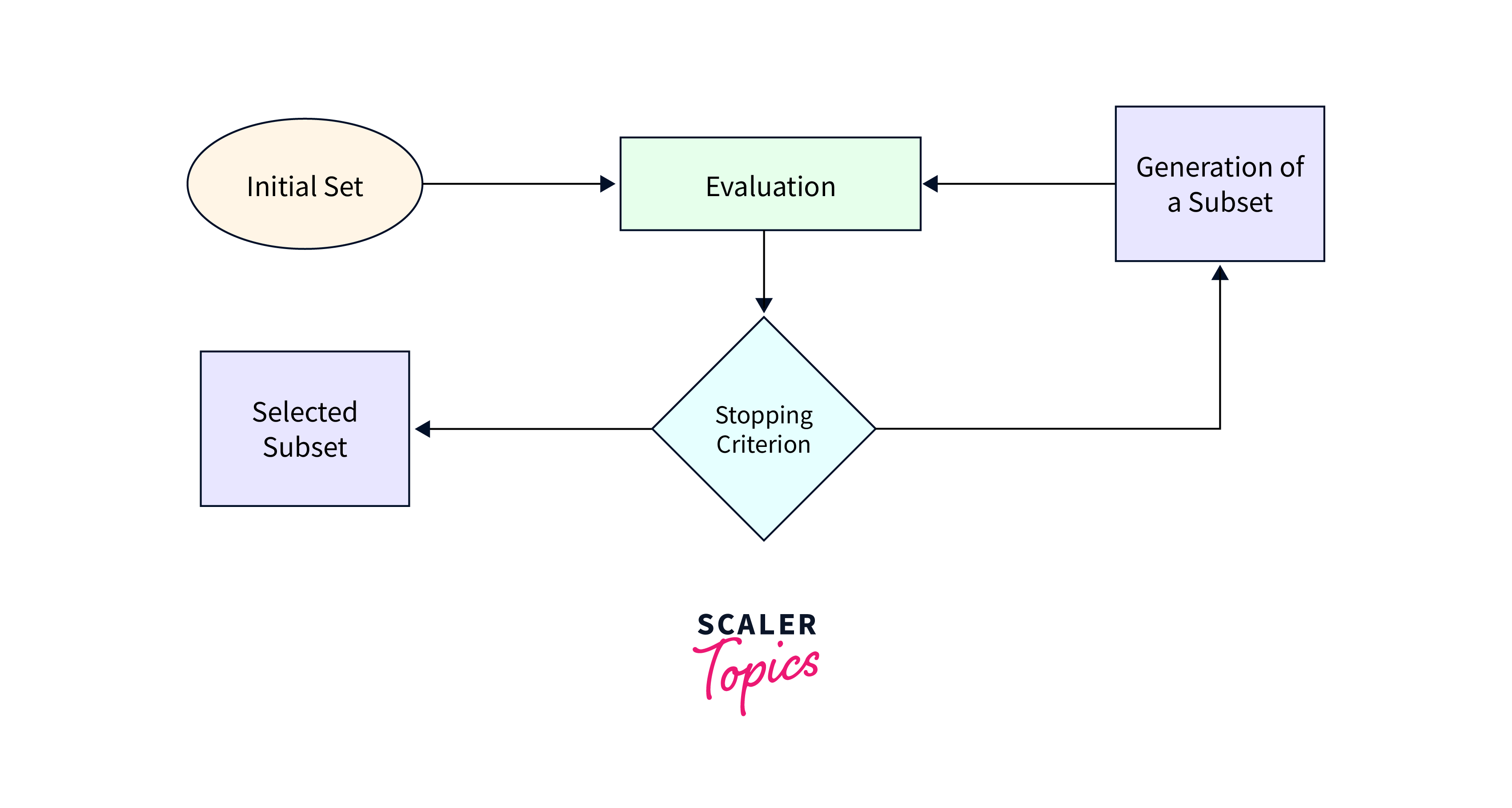
6. Data Subset Selection: When working with massive datasets, it may be impractical to load and process the entire dataset at once.
- Data subset selection involves selecting a representative subset of the data that captures the essential characteristics of the complete dataset.
- This technique allows for faster experimentation and model development. Random sampling, stratified sampling, or other sampling methods can be employed to create data subsets.
- TensorFlow's tf.data module provides methods like take() or filter() to select specific elements or apply filtering operations to create data subsets efficiently.
Conclusion
- In conclusion, TensorFlow's data loading capabilities play a crucial role in optimizing deep learning workflows.
- The tf.data module provides a versatile and efficient framework for handling various aspects of data loading, including creating datasets, preprocessing data, shuffling, batching, and parallelizing operations.
- By leveraging the power of TensorFlow's tf.data, researchers and practitioners can achieve enhanced efficiency.