Training and Evaluation of Recommendation Models in TensorFlow
Overview
Training and evaluation of recommendation models in TensorFlow is crucial for optimizing personalized content recommendations. Recommendation systems play a crucial role in modern online platforms by helping users discover relevant content, products, or services. TensorFlow, a popular machine learning framework, provides powerful tools and libraries to build recommendation models effectively. In this guide, we will explore the training and evaluation of recommendation models using TensorFlow.
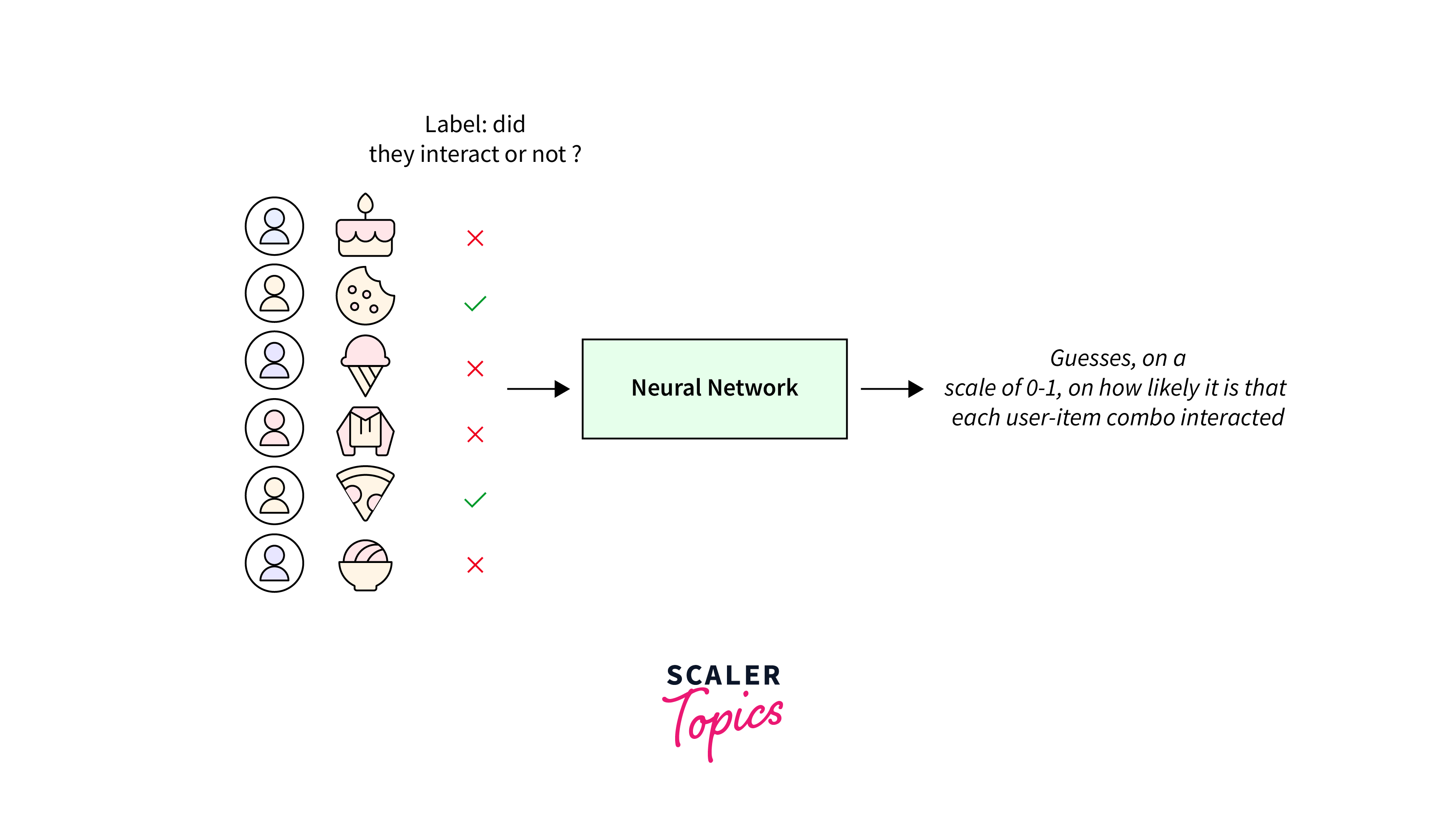
Understanding Recommendation Systems
A recommendation system, also known as a recommender system or engine, is a software application or algorithm designed to provide personalized suggestions or recommendations to users. These systems are widely used in various industries and platforms to help users discover relevant content, products, or services. Developers often face challenges when it comes to the training and evaluation of recommendation models in TensorFlow due to the complexity of data and algorithms involved.
Purpose of Recommendation Systems:
- The primary goal of recommendation systems is to assist users in making choices from a vast set of available options.
- They help users discover items they may be interested in, leading to improved user engagement, satisfaction, and potentially increased revenue for businesses.
- Understanding user behavior and preferences is key to effective training and evaluation of recommendation models in TensorFlow.
Data Sources:
- Recommendation systems rely on data sources such as user interactions (e.g., clicks, purchases, ratings), user profiles (demographics, past behavior), and item descriptions (attributes, tags) to make recommendations.
Algorithms and Techniques:
Various algorithms and techniques are used, including similarity measures, matrix factorization, neural networks, and natural language processing, depending on the type of recommendation system.
-
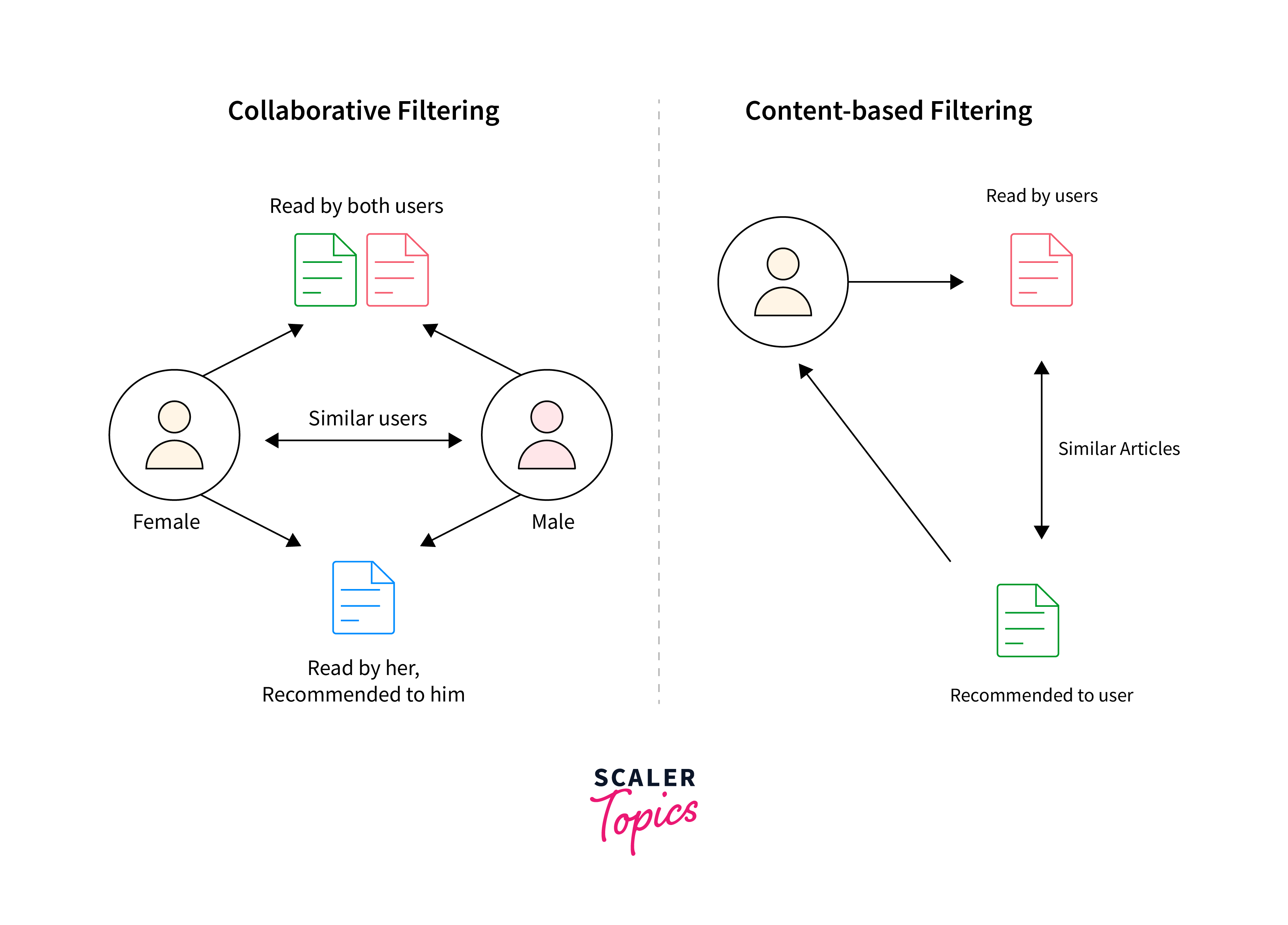
Collaborative Filtering:
Collaborative filtering is one of the fundamental recommendation techniques. It relies on user-item interactions to make predictions. TensorFlow provides tools to implement collaborative filtering models efficiently.
-
Content-Based Filtering:
Content-based filtering recommends items based on the characteristics or content of the items and the user's past preferences. TensorFlow allows you to create content-based recommendation models using neural networks.
-
Matrix Factorization:
Matrix factorization techniques like Singular Value Decomposition (SVD) and Alternating Least Squares (ALS) are commonly used for recommendation tasks. TensorFlow can be used to implement matrix factorization models.
-
Deep Learning-Based Models:
Deep learning models, such as neural collaborative filtering (NCF) and deep matrix factorization, have shown excellent performance in recommendation tasks. TensorFlow offers the flexibility to design and train complex deep learning models.
Evaluation Metrics:
- To assess the performance of recommendation systems, metrics like precision, recall, mean squared error (MSE), root mean squared error (RMSE), and click-through rate (CTR) are commonly used.
Overview of TensorFlow for Recommendation Models
TensorFlow provides a range of tools and libraries to build recommendation models efficiently. TensorFlow plays a significant role in recommendation systems by providing a flexible and powerful framework for developing, training, and deploying recommendation models. Understanding the intricacies of training and evaluation of recommendation models in TensorFlow can enhance the user experience on various platforms.
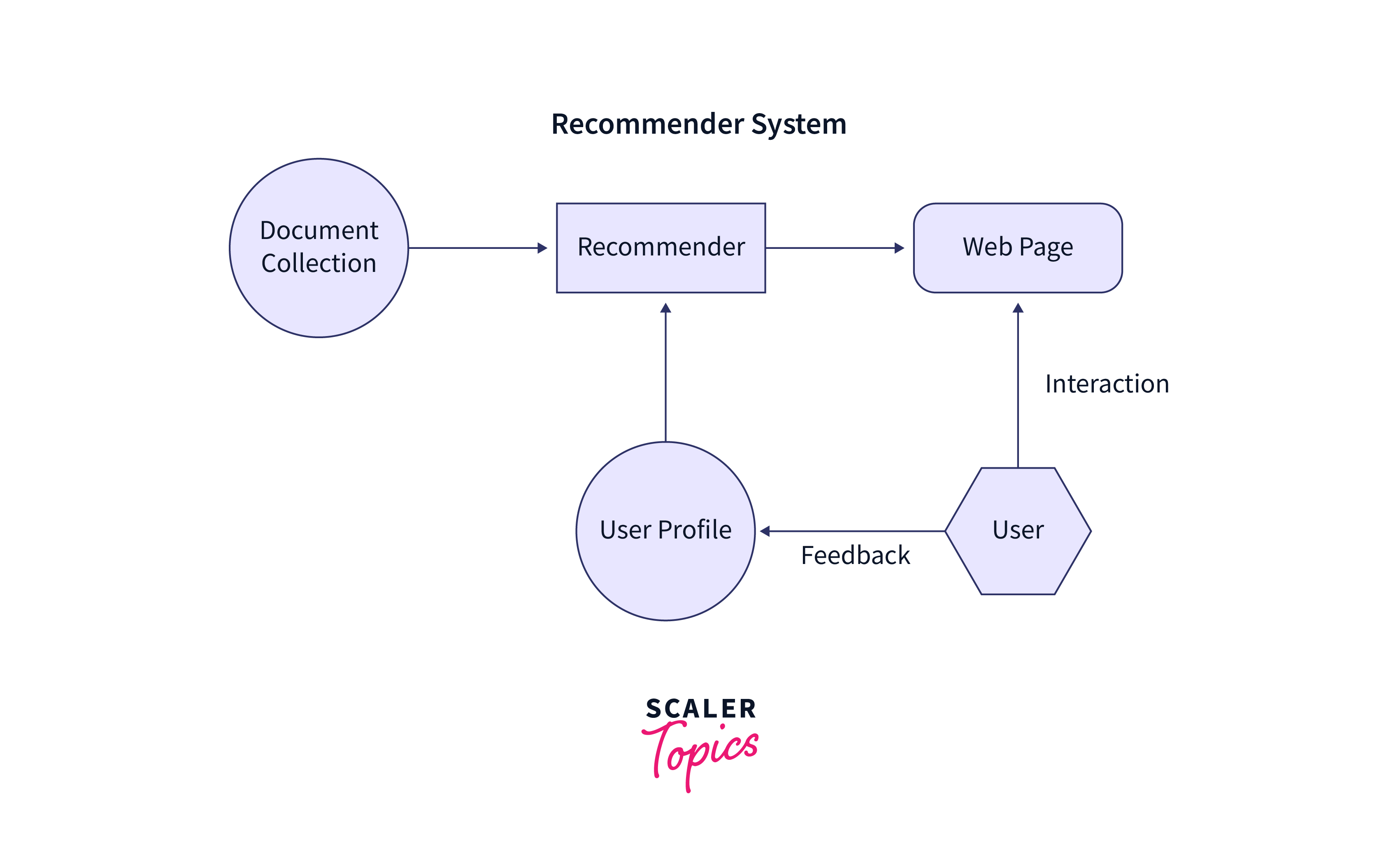
Here's how TensorFlow contributes to recommendation systems:
-
Model Development:
TensorFlow offers a comprehensive ecosystem, including the Keras API, for building recommendation models. This enables developers to create a wide range of recommendation algorithms, from traditional collaborative filtering to advanced deep learning-based models.
-
Scalability:
Recommendation systems often deal with large datasets and high user traffic. TensorFlow's distributed computing capabilities and support for GPU acceleration make it suitable for building scalable recommendation systems that can handle massive data volumes and user demands.
-
Flexibility:
TensorFlow allows developers to customize and fine-tune recommendation models to fit specific use cases and business requirements. You can design complex architectures, experiment with various loss functions, and incorporate domain-specific features easily.
Data Preparation for Recommendation Models
Data preparation is a crucial step for training and evaluation of Recommendation Models in TensorFlow. It involves preparing your dataset, which typically includes user-item interactions, user features, and item features, in a format suitable for training recommendation models. Here's an example of data preparation for recommendation models using Python and TensorFlow:
In this example:
- We start with a sample dataset containing user-item interactions and ratings.
- We split the data into training and testing sets.
- We create dictionaries to map user and item IDs to unique integer IDs.
- We use these mappings to convert user and item IDs in the data to their corresponding integer IDs.
- We convert the data to TensorFlow Datasets for efficient training.
- Optionally, we create user and item embeddings using TensorFlow's Embedding layers, which can be used in your recommendation model.
This code provides a basic template for data preparation. You would replace the sample dataset with your actual data and adapt the code to your specific dataset and recommendation model requirements.
Building Recommendation Models in Tensor Flow
Building recommendation models in TensorFlow involves designing and training models tailored to your specific use case. Training and Evaluation of Recommendation Models in TensorFlow allows organizations to deliver personalized experiences to their users, whether in e-commerce, content streaming, or other domains. TensorFlow's flexibility and scalability make it a valuable tool for developing effective recommendation systems tailored to specific business needs.
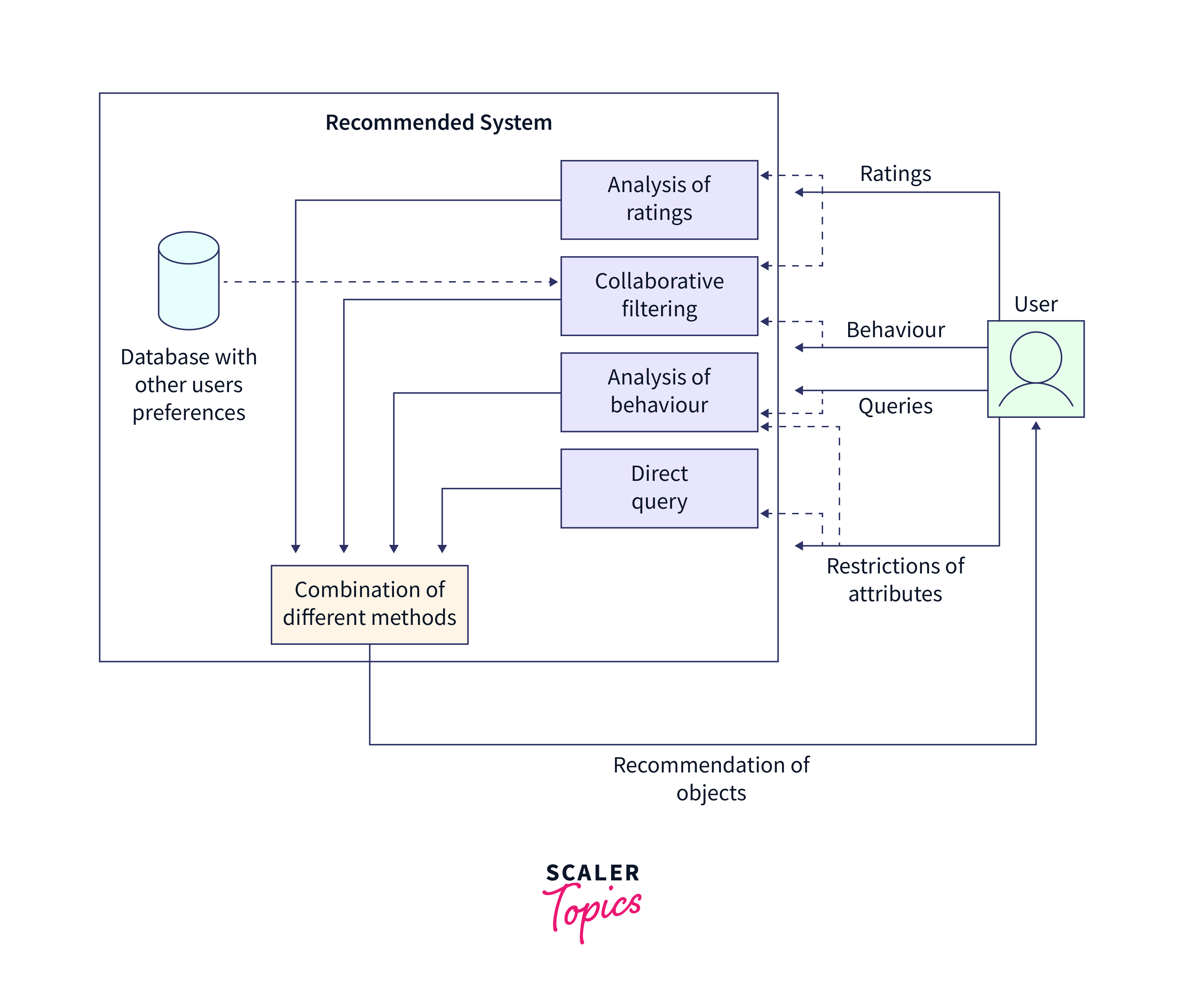
Here's an outline of the key components involved in training and evaluating recommendation models in TensorFlow:
-
Data Preparation:
Prepare your recommendation dataset, including user-item interactions, user features, and item features. TensorFlow's data preprocessing utilities, such as tf.data and tf.feature_column, can help with data preparation.
-
Model Architecture:
Design the architecture of your recommendation model. Depending on the approach (collaborative filtering, content-based, or deep learning-based), you'll build different model architectures using TensorFlow's Keras API.
-
Loss Functions:
Define appropriate loss functions for your recommendation task. Common loss functions include mean squared error (MSE) for regression tasks and binary cross-entropy for binary classification tasks.
-
Training:
Use TensorFlow's powerful training features to train your recommendation model. You can take advantage of distributed training, custom training loops, and various optimizers to fine-tune your models.
-
Evaluation Metrics:
Choose relevant evaluation metrics for your recommendation system, such as accuracy, precision, recall, or mean squared error. TensorFlow's metrics module provides pre-defined metrics and tools to compute custom metrics.
-
Hyperparameter Tuning:
Experiment with hyperparameter tuning techniques, like grid search or random search, to optimize your recommendation model's performance.
-
Deployment:
After training and evaluation, deploy your recommendation model to your production environment using TensorFlow Serving or other deployment solutions.
-
Monitoring and Maintenance:
Continuously monitor the performance of your recommendation system in production and perform regular maintenance and model updates.
Training Recommendation Models
Efficient Training and Evaluation of Recommendation Models in TensorFlow can lead to significant improvements in recommendation accuracy. Training recommendation models is a dynamic process that requires a deep understanding of data, algorithms, and user behavior to provide users with personalized and engaging recommendations. During training, the model learns to minimize the difference between predicted and actual user interactions. Hyperparameters, optimization techniques, and regularization are adjusted to improve model performance.
In the training code example:
- We define a simple matrix factorization model.
- The model is compiled with mean squared error as the loss function.
- We train the model using training data for a specified number of epochs.
Evaluation of Recommendation Models
TensorFlow's flexibility allows for experimentation and innovation when it comes to training and evaluation in recommendation systems. Various metrics, including mean squared error (MSE), root mean squared error (RMSE), and ranking-based metrics like precision and recall, are used to evaluate the model's accuracy and relevance.Models are validated using techniques like cross-validation to ensure they generalize well to unseen data and users. Continuous monitoring and fine-tuning are essential for maintaining the effectiveness of Training and Evaluation of Recommendation Models in TensorFlow
The code uses MSE as an evaluation metric because it's a widely adopted metric for regression tasks. MSE quantifies the average squared difference between the model's predicted ratings and the actual ratings in the test dataset. MSE is appropriate when the goal is to measure the accuracy of a regression model in predicting continuous numerical values (in this case, ratings). It is particularly suitable for scenarios where you want to penalize larger prediction errors more heavily, as it squares the differences. Sample Output:
In the evaluation code example:
- We use the trained model to make predictions on the test data.
- We calculate the mean squared error (MSE) between the predicted ratings and the actual ratings in the test data.
- The output displays the MSE value, indicating the model's performance in terms of prediction accuracy. Lower MSE values are better.
Implementing Popular Recommendation Algorithms in TensorFlow
TensorFlow offers a robust framework for Training and Evaluation of Recommendation Models in TensorFlow, making it a popular choice among developers.
Below are some of the foundational recommendation algorithms used in building recommendation systems. Depending on your specific use case and data, you may choose one of these algorithms or a combination of them to build an effective recommendation system using TensorFlow or other machine learning frameworks.
Here are popular recommendation algorithms summarized in points:
-
Matrix Factorization:
- Decomposes user-item interaction data into user and item latent factors.
- Predicts user-item interactions by taking the dot product of user and item embeddings.
- Typically uses techniques like Singular Value Decomposition (SVD) or matrix factorization with deep learning.
-
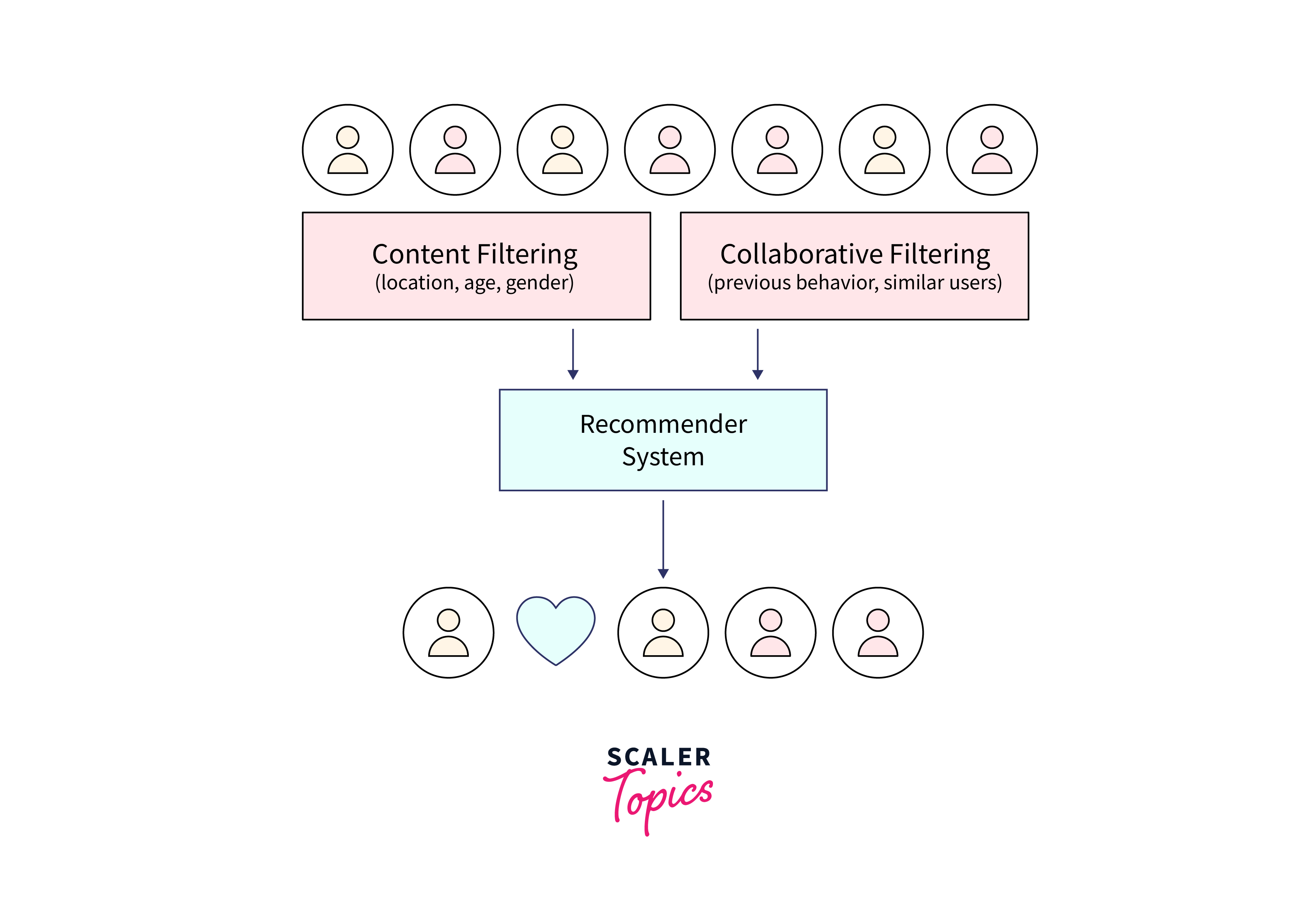
Collaborative Filtering:
- Recommends items to users based on the preferences and behaviors of similar users or items.
- Can be user-based, item-based, or model-based collaborative filtering.
- User-based CF finds similar users to make recommendations, while item-based CF finds similar items.
- Model-based CF employs machine learning models to capture patterns in the data.
-
Neural Collaborative Filtering (NCF):
- Combines collaborative filtering with neural networks.
- Uses embeddings of users and items as inputs to a neural network.
- Learns complex, non-linear patterns in user-item interactions.
- Typically involves multi-layer perceptrons (MLPs) to model interactions.
Collaborative Filtering with Matrix Factorization
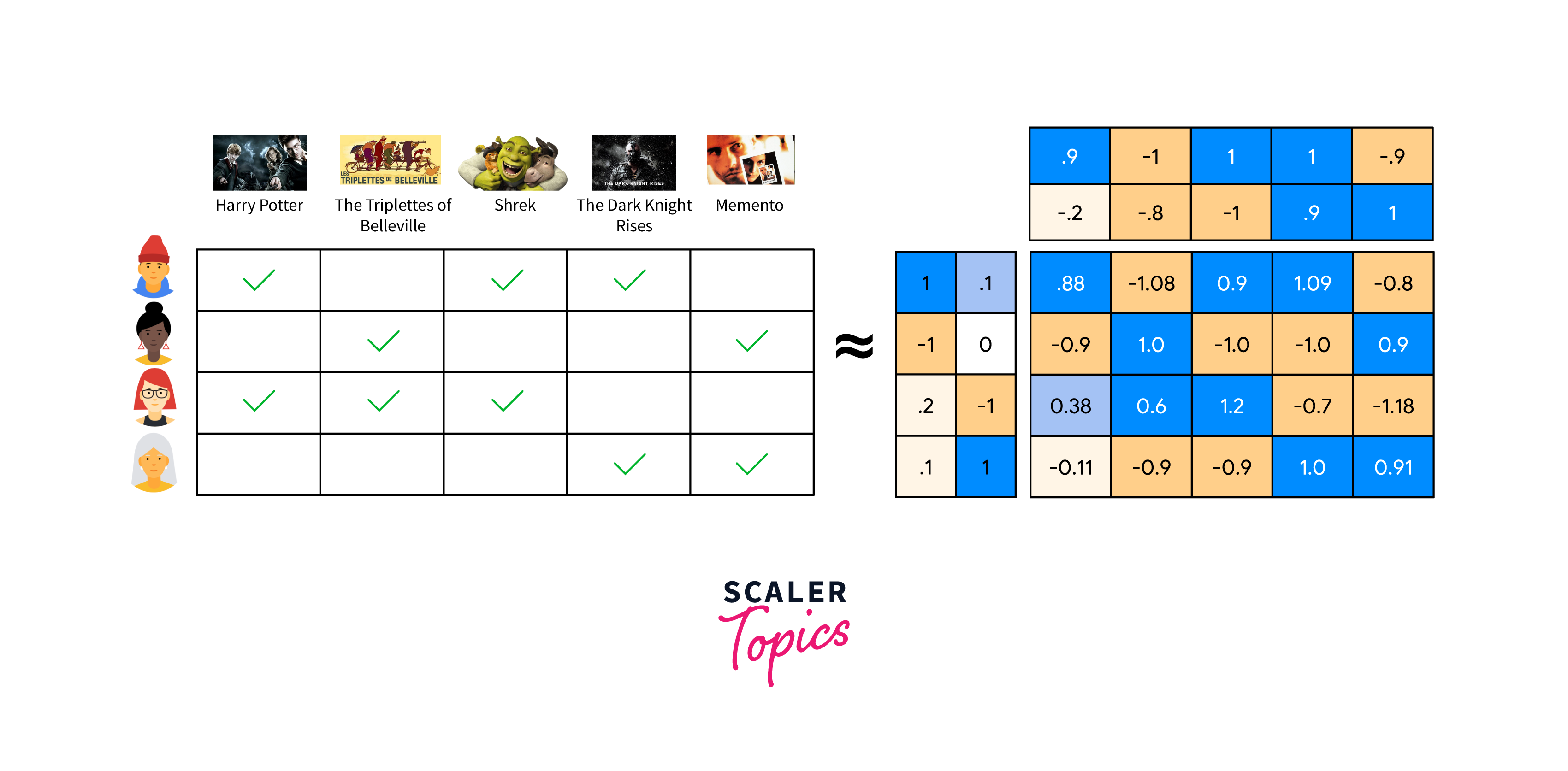
Matrix factorization is a classic approach for collaborative filtering-based recommendation. Here's an example using TensorFlow:
In this example:
- We use a simple matrix factorization model with user and item embeddings.
- The model computes the dot product of these embeddings to predict ratings.
- We compile and train the model using mean squared error as the loss function.
Output:
Deep Learning-Based Recommendation Model
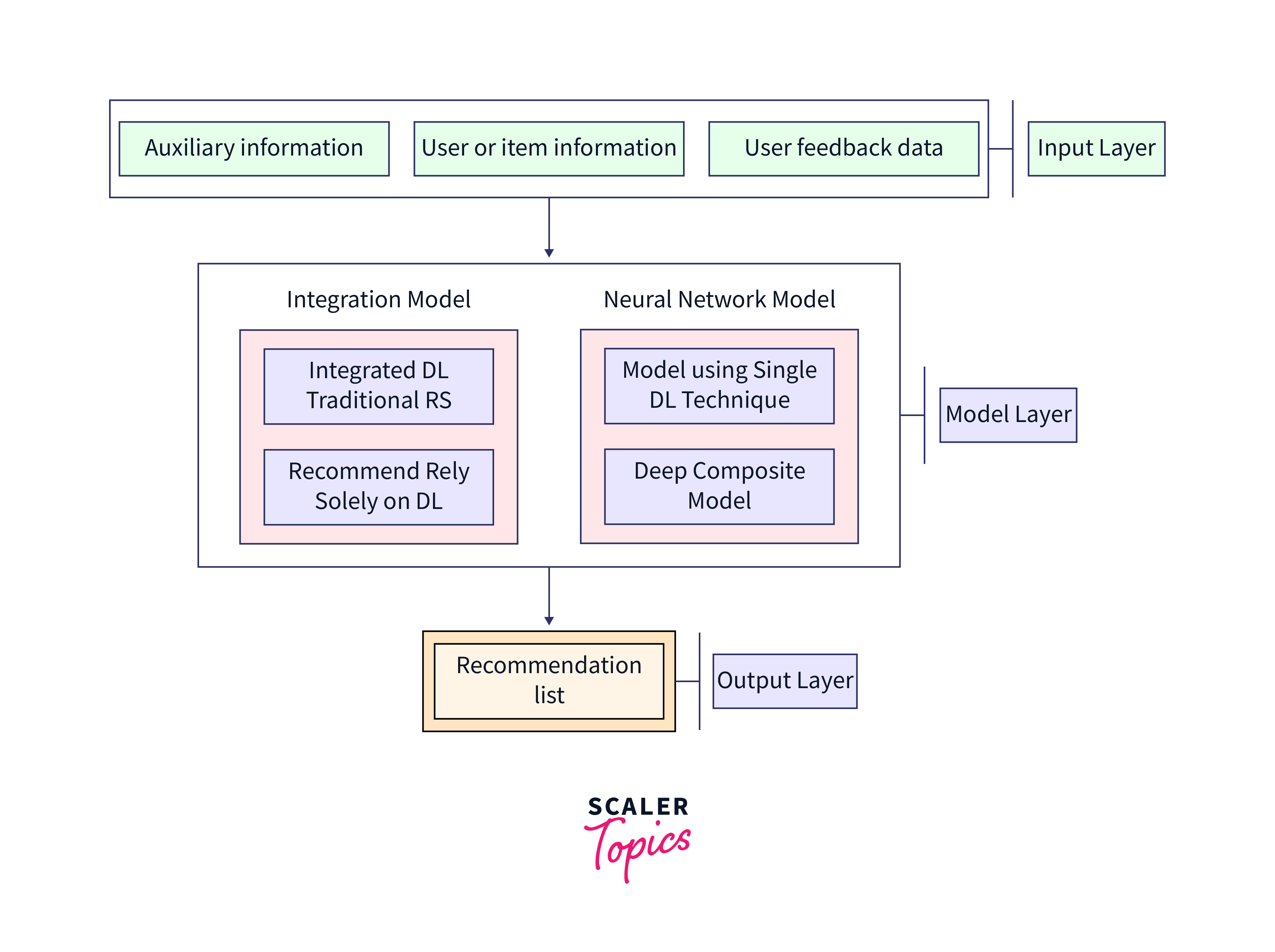
Deep learning-based recommendation models, such as neural collaborative filtering (NCF), leverage neural networks for enhanced recommendation accuracy. TensorFlow's deep learning capabilities play a significant role in improving the accuracy of Training and Evaluation of Recommendation Models in TensorFlow. Here's an example using TensorFlow and Keras:
In this example:
- We create a deep learning-based recommendation model with user and item embeddings and a neural network.
- The model uses the user and item embeddings as input and passes them through a neural network for rating prediction.
- We compile and train the model using mean squared error as the loss function.
These are simplified examples, and you should adapt them to your specific dataset and requirements. Additionally, you can explore more complex architectures and regularization techniques to improve recommendation accuracy.
Output:
Scalability and Deployment
Scalability and deployment are crucial aspects of recommendation systems.The success of many online platforms relies on the continuous refinement of Training and Evaluation of Recommendation Models in TensorFlow. Let's discuss these topics briefly:
Scalability in Recommendation Systems:
- Recommendation systems often deal with large datasets and high user traffic.
- Scalability ensures that the system can handle growing data volumes and user demands.
- Distributed computing frameworks like Apache Spark and TensorFlow's distributed training support scalability.
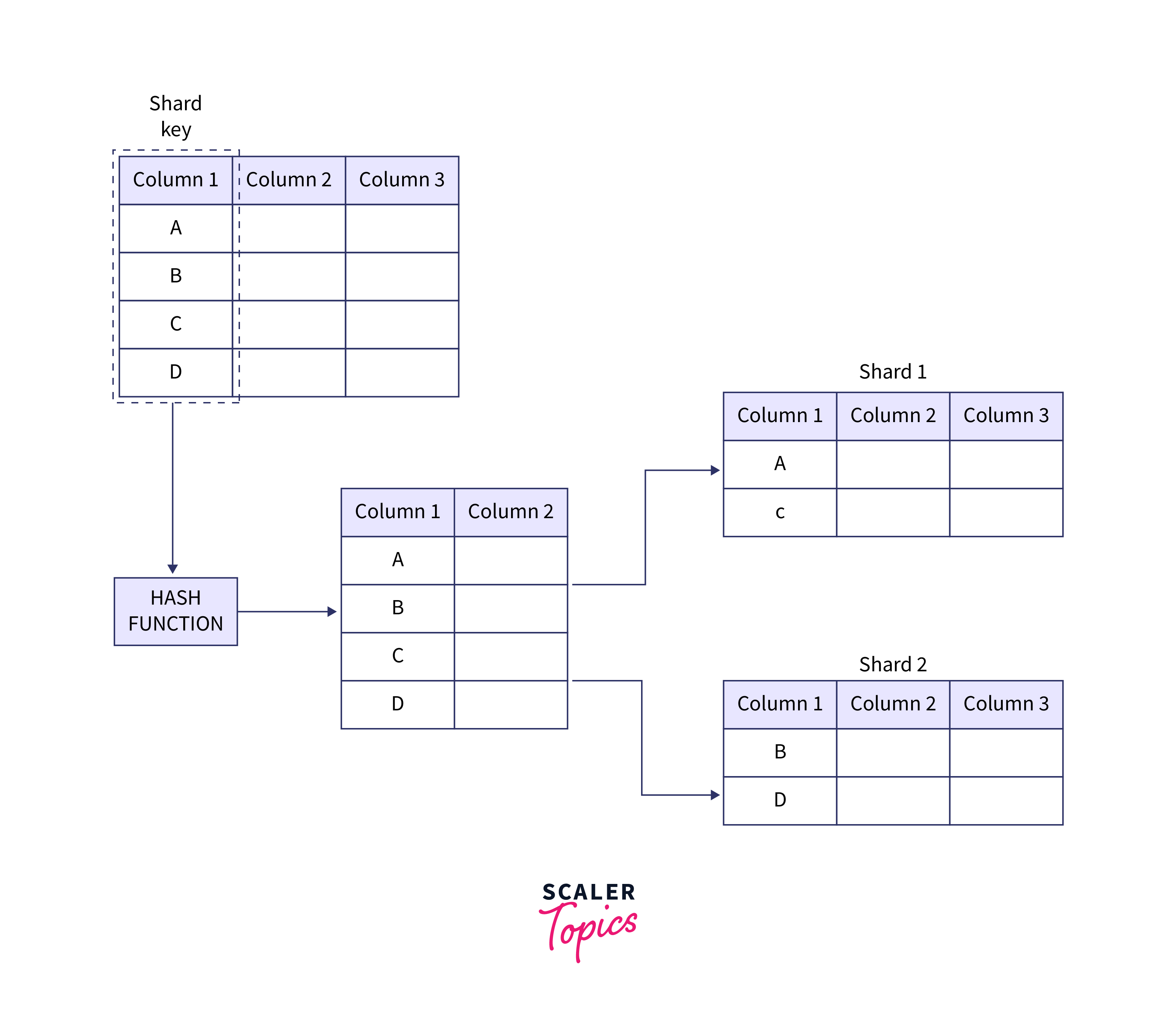
Data Sharding:
- Data can be sharded or partitioned to distribute processing across multiple servers or clusters.
- Sharding helps balance the load and ensures efficient data retrieval for recommendations.
Caching:
- Caching frequently accessed recommendations can reduce the computational load.
- Techniques like in-memory databases or caching layers like Redis can be used for this purpose.
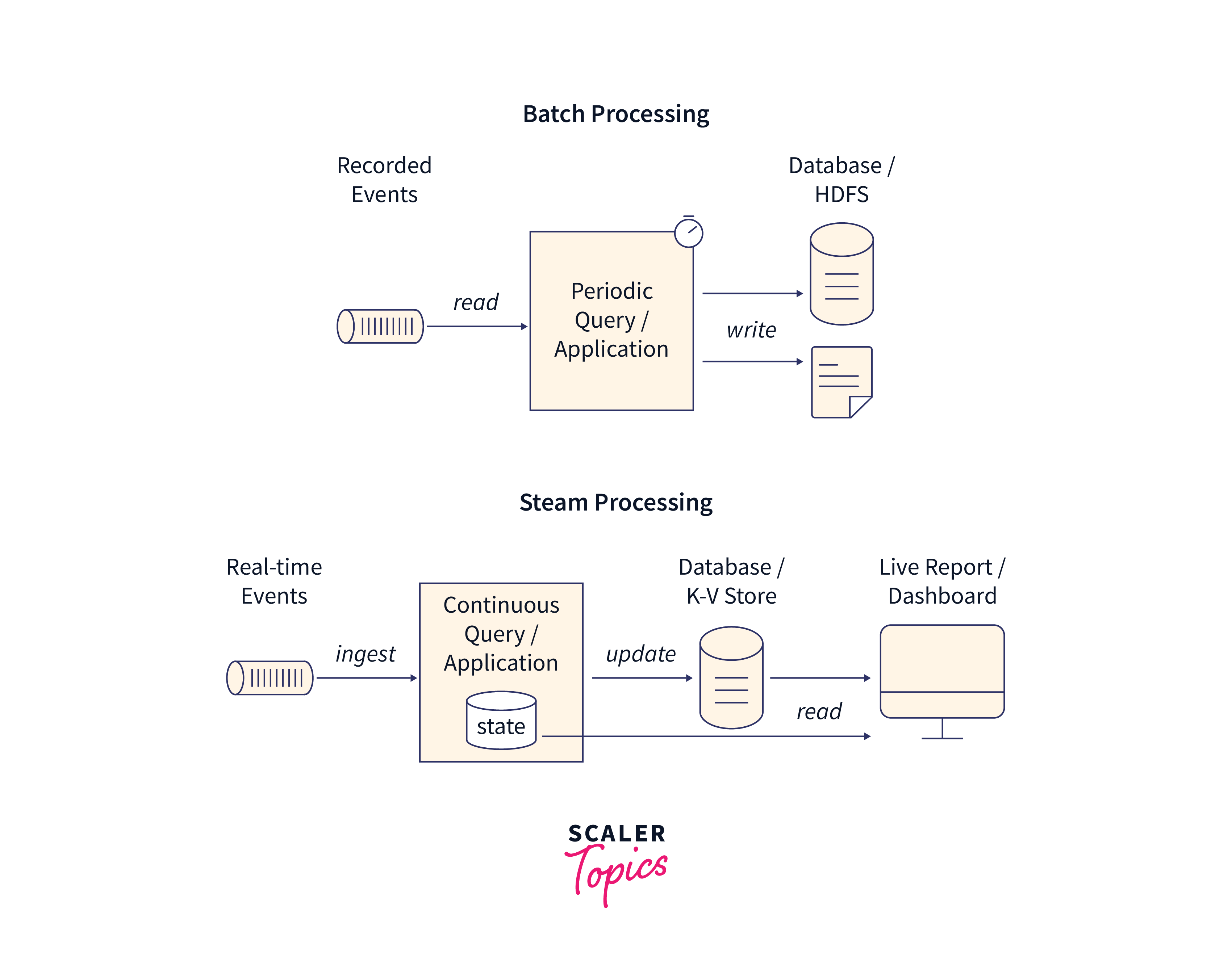
Batch and Real-time Recommendations:
- Scalable systems can provide both batch and real-time recommendations.
- Batch processing allows offline recommendation generation, while real-time processing serves recommendations on-the-fly.
Deployment of Recommendation Models:
- Deploying recommendation models involves making them accessible to users in production environments.
- TensorFlow Serving, Docker containers, or cloud-based solutions like AWS Lambda can be used for deployment.
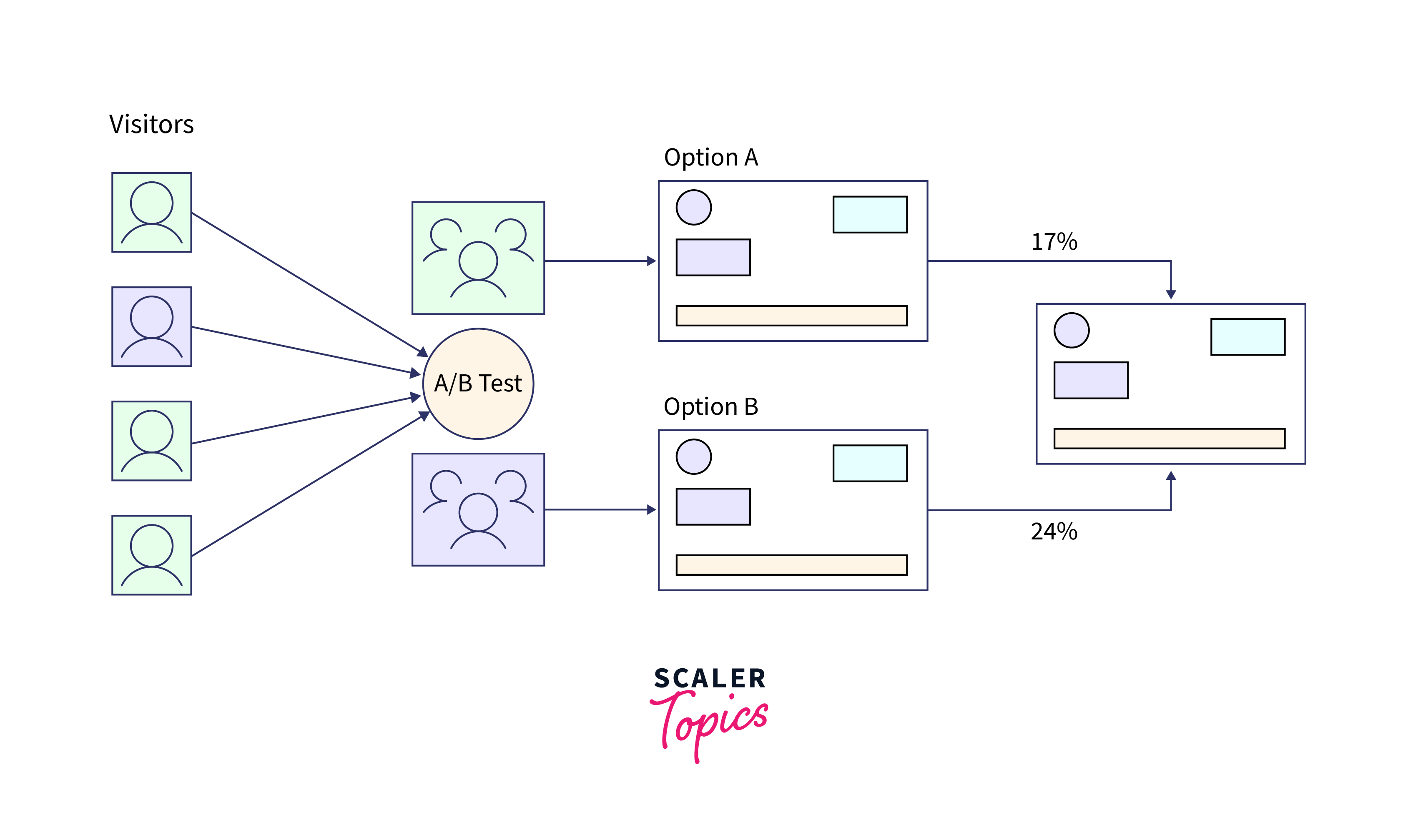
A/B Testing:
- Deployed models often undergo A/B testing to evaluate their effectiveness.
- Users are divided into groups, and different recommendation algorithms are tested to measure user engagement and conversion rates.
Monitoring and Maintenance:
- Continuous monitoring of recommendation systems is vital to ensure they perform optimally.
- Maintenance involves updating models, retraining, and addressing issues like model drift.
Security and Privacy:
- Deployed systems must address security and privacy concerns, especially when dealing with user data.
- Techniques like anonymization, encryption, and access controls help protect user information.
Conclusion
- We explored the fundamental concepts of recommendation systems, their importance in various domains, and the role of TensorFlow in building these systems.
- We delved into the deployment of recommendation models, A/B testing, monitoring, and maintenance.
- As AI and machine learning continue to advance, Training and Evaluation of Recommendation Models in TensorFlow will remain at the forefront of personalized content delivery.
- Recommendation systems have a direct impact on businesses' bottom lines. They can boost sales, increase user engagement, and drive advertising revenue. As a result, organizations are investing heavily in recommendation technology.