How to Use DTensors with Keras?
Overview
A Tensor in TensorFlow is a multi-dimensional array, similar to NumPy arrays. Tensors are the fundamental data structure used to represent data in TensorFlow and are at the core of all computations performed using the TensorFlow library. They can have different ranks, which correspond to the number of dimensions they hold.
This guide will explore how to use a distributed Tensor in TensorFlow with Keras, the popular deep-learning library based on TensorFlow.
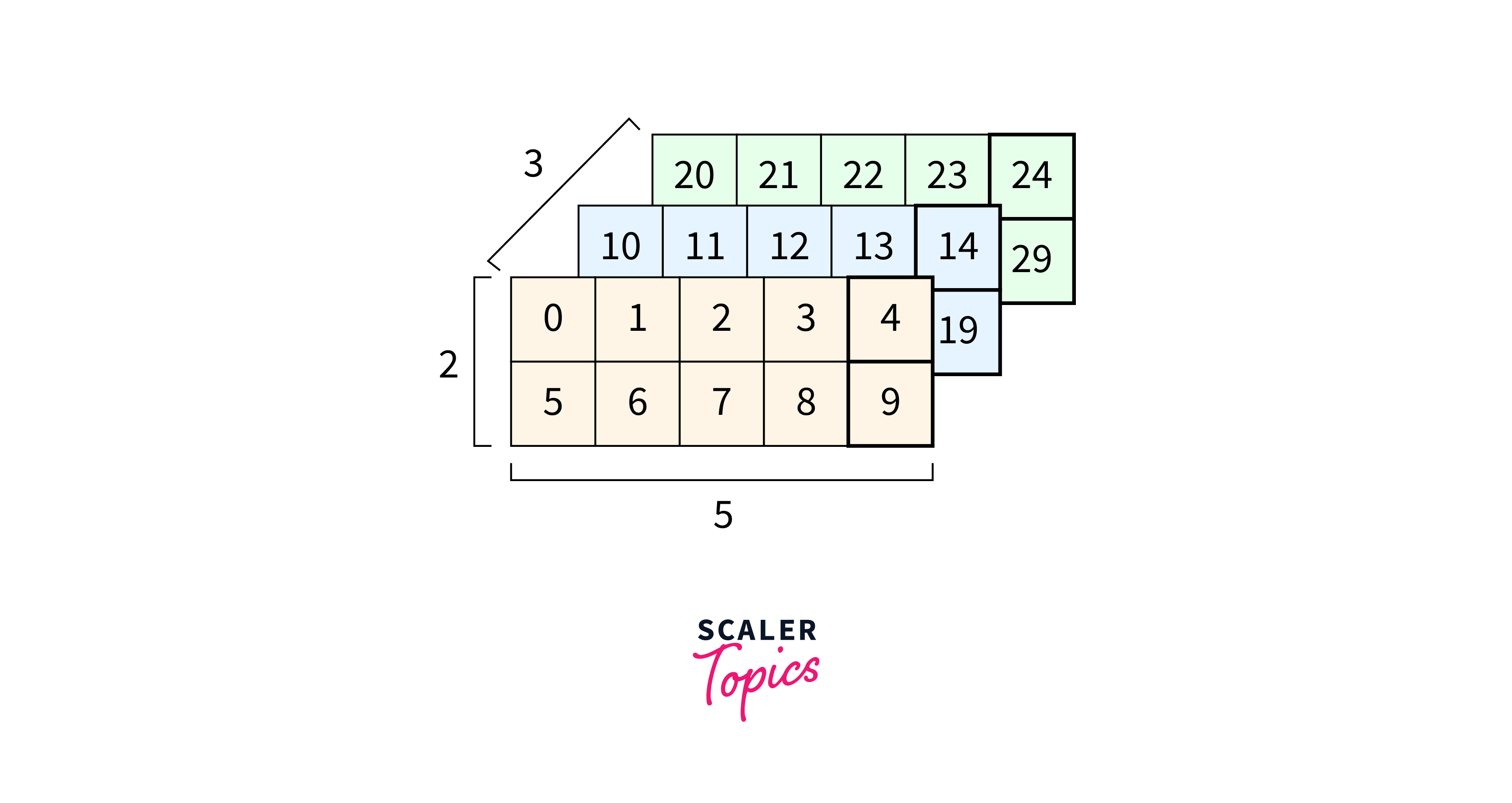
What is a DTensor in TensorFlow?
A DTensor is similar to a regular tensor in TensorFlow but has additional features that make it suitable for distributed computing. They possess the following properties:
-
Distributed Representation:
DTensors are divided into smaller chunks that can be stored and processed across multiple devices or machines.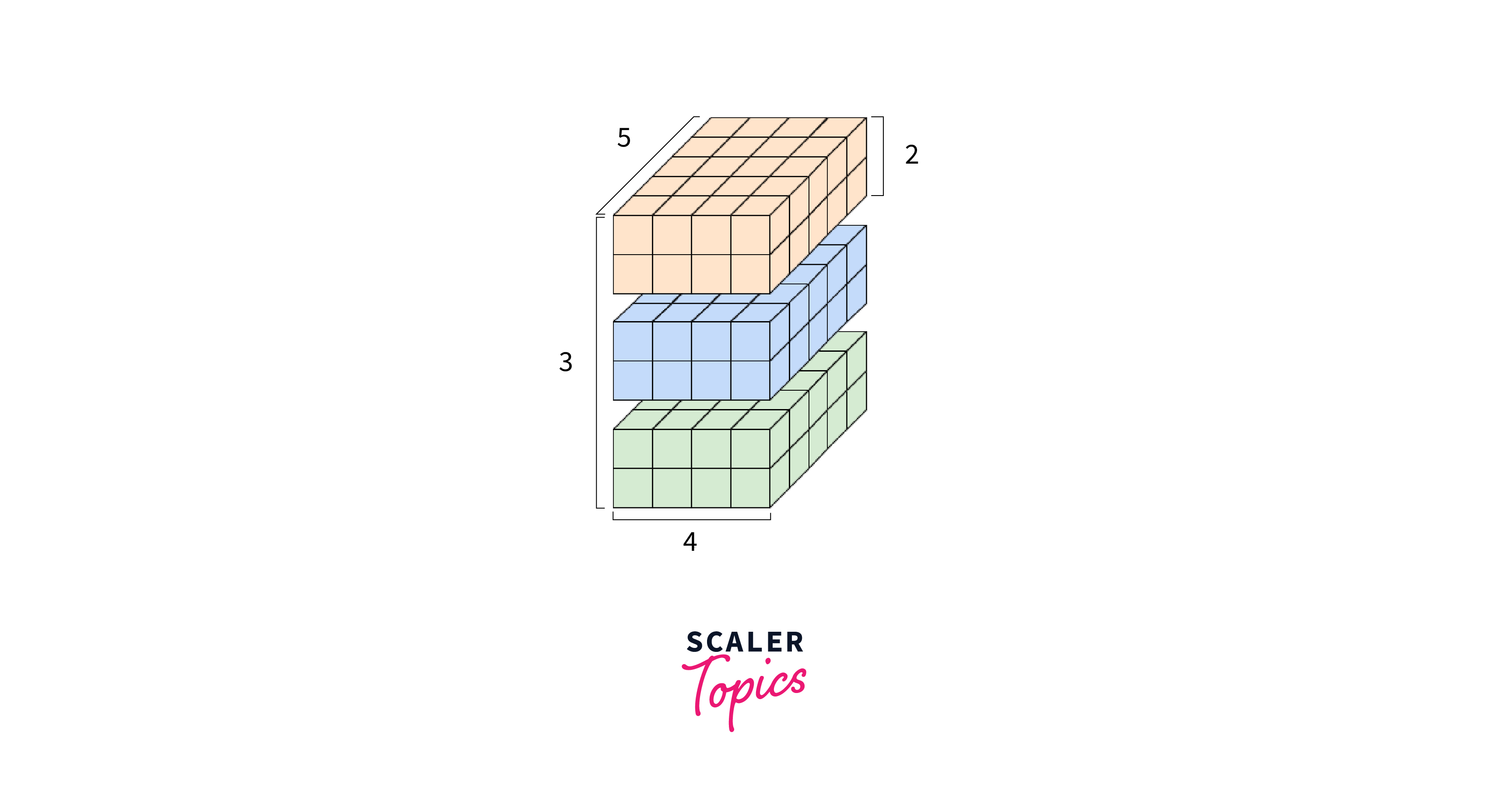
-
Parallel Computation:
Computations involving DTensors can be parallelized, taking advantage of distributed computing resources, leading to faster training and inference times. -
Scalability:
A distributed tensor in TensorFlow enables efficient handling of large datasets that might not fit into the memory of a single device. -
Fault Tolerance:
DTensors support fault tolerance, meaning they can recover from certain failures during distributed computations.
Creating DTensor Datasets
We first need to create a distributed dataset to work with a distributed tensor in TensorFlow. TensorFlow provides the tf.data.Dataset API that allows you to create and manipulate datasets efficiently.
Let's see how we can create a DTensor dataset using TensorFlow's tf.data.Dataset API:
Distributed Tensor in Tensorflow for Distributed Computations
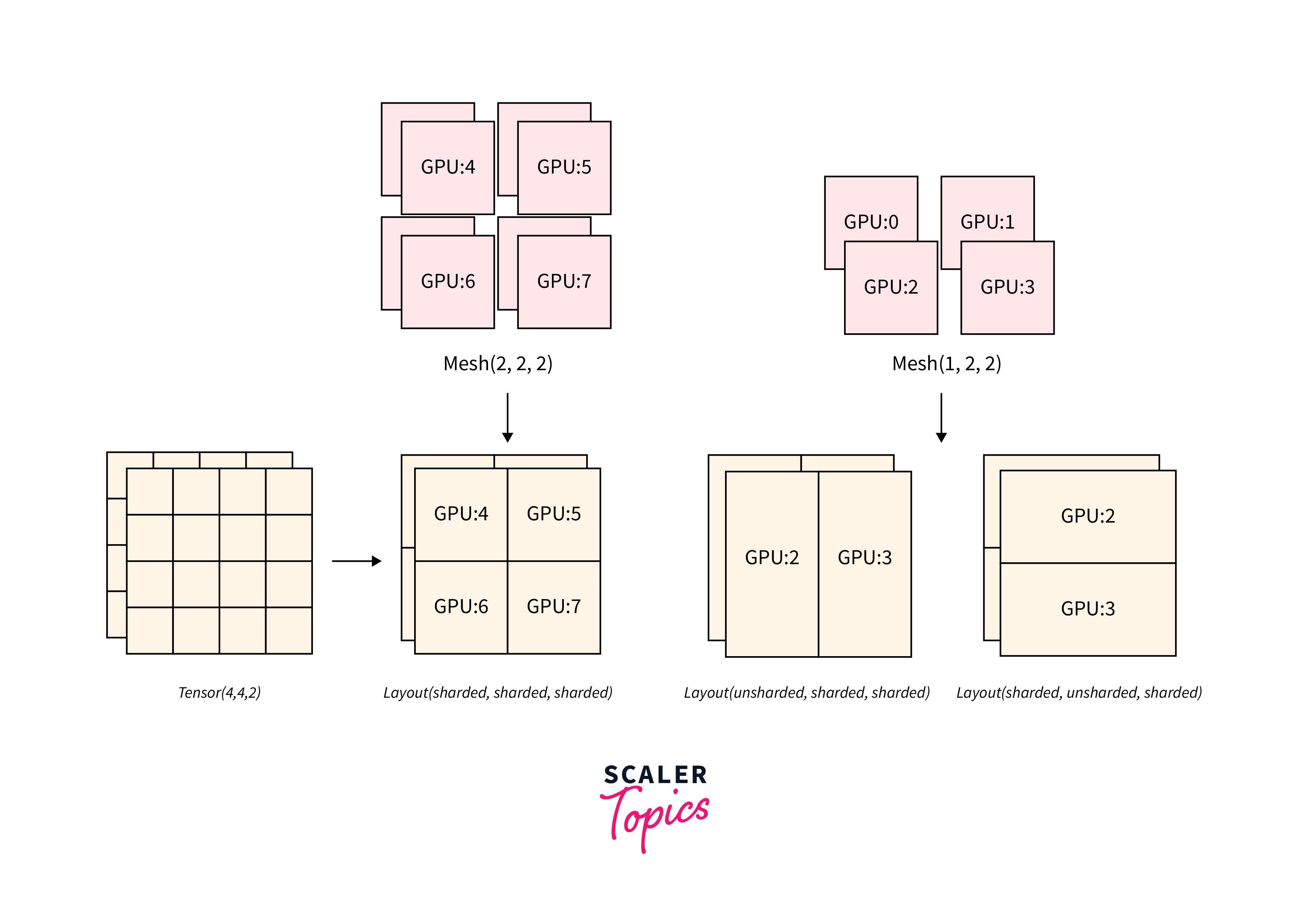
DTensors, short for "distributed tensors", are a specialized data structure in TensorFlow designed for efficient distributed computations. They are an extension of regular tensors that allow for parallel processing across multiple devices, GPUs, or machines. DTensors are crucial for scaling deep learning models and handling large datasets that may not fit into the memory of a single device.
When dealing with DTensors for distributed computations, TensorFlow provides various strategies to distribute the computation across different devices or machines. Some common strategies include:
-
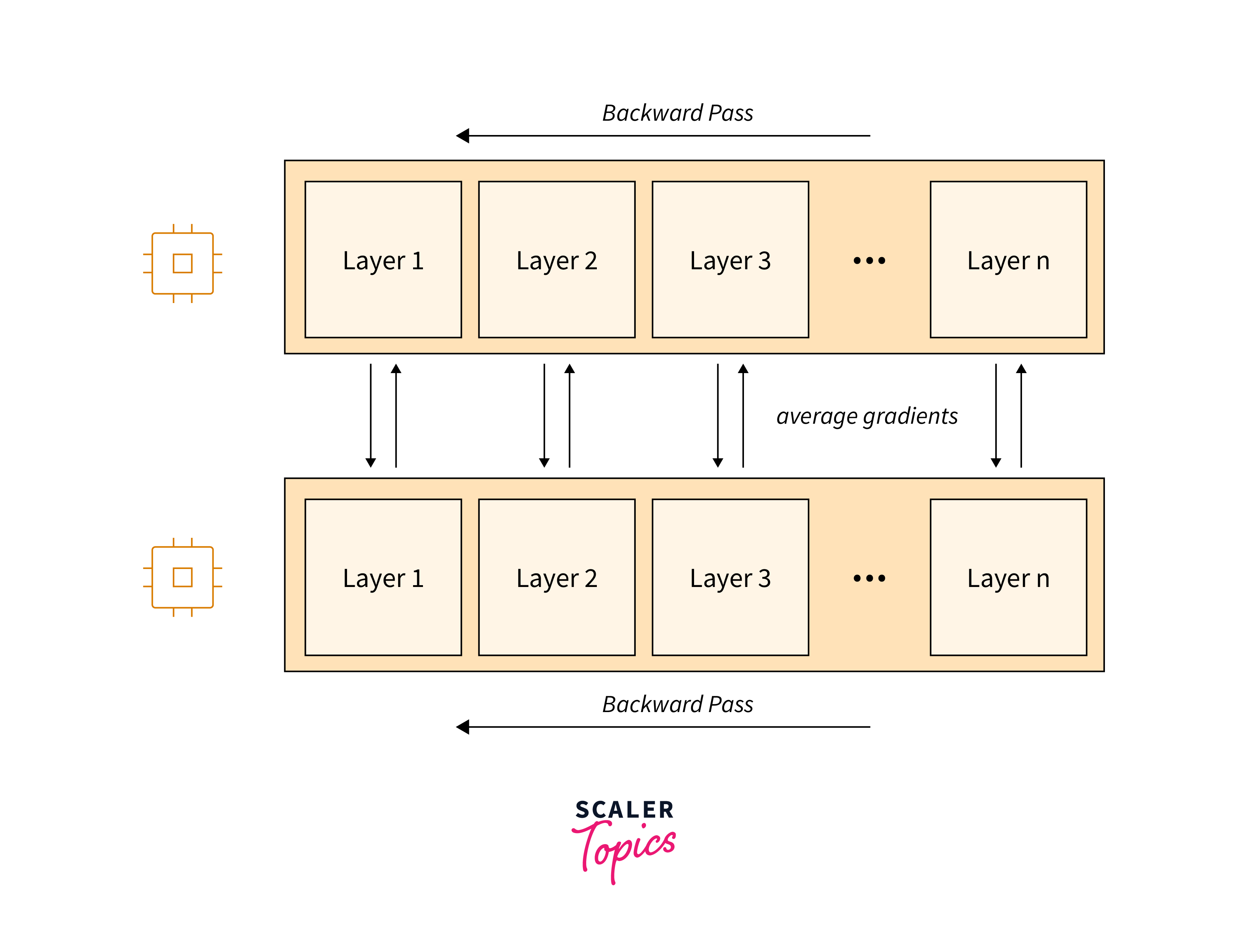
Mirrored Strategy:
This strategy replicates the model on multiple GPUs or devices within a single machine. Each replica processes a portion of the input data, and gradients are averaged across replicas during backpropagation.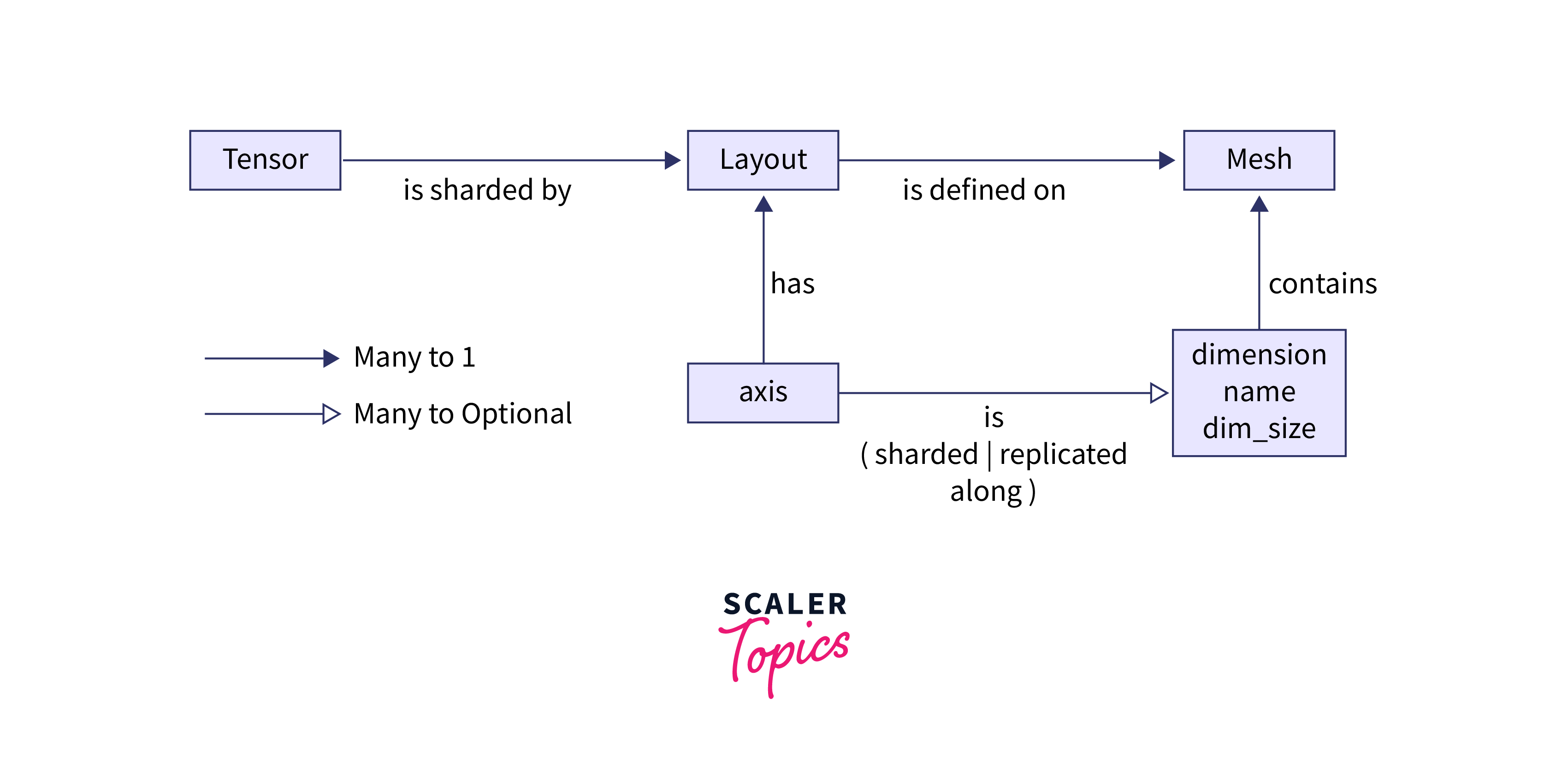
-
Multi-Worker Mirrored Strategy:
Similar to the mirrored strategy, it distributes replicas across multiple machines, allowing for even larger-scale distributed training. -
Central Storage Strategy:
In this approach, all variables are stored on a central device or machine, and the computation is distributed across multiple devices.
-
Parameter Server Strategy:
This strategy involves parameter servers storing the model's variables. The computation is divided across devices, and each device communicates with the parameter servers to update the model's variables during training.
The choice of strategy depends on factors such as the available hardware, network bandwidth, and the size of the model and dataset.
Integrating a Distributed Tensor in Tensorflow with Keras Models
Integrating a tensor in TensorFlow with Keras models is relatively straightforward, as Keras is built on top of TensorFlow and naturally supports distributed computations using DTensors. To use DTensors with Keras, you can follow these steps:
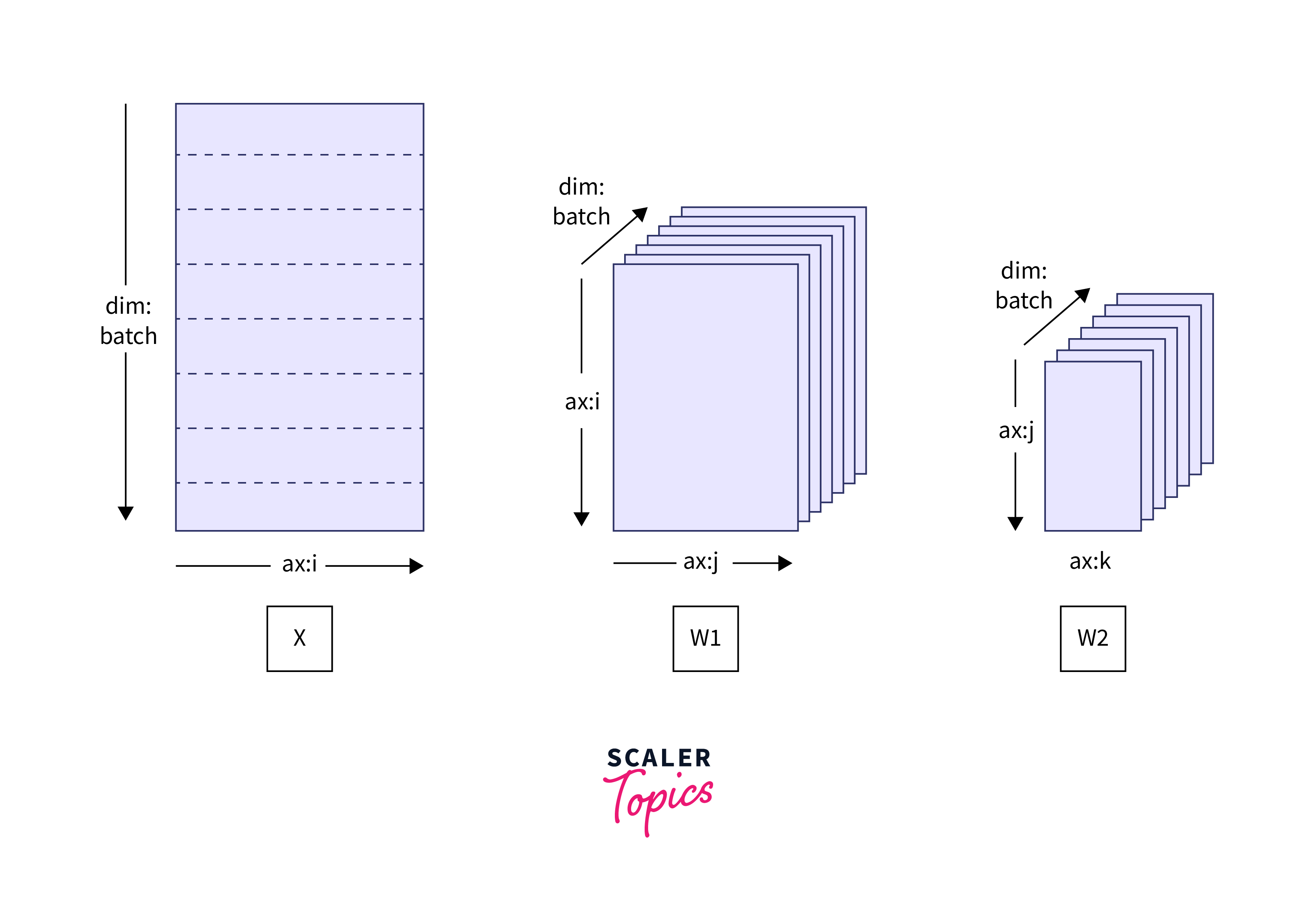
Step 1: Create a Distributed Dataset
In this step, we create a distributed dataset using TensorFlow's from_tensor_slices method. We then choose a distribution strategy (in this case, MirroredStrategy) that distributes the dataset across multiple devices or machines.
We apply the strategy to the dataset and optionally shuffle it for better training.
Step 2: Choose a Distribution Strategy
In this step, we choose the distribution strategy with a tensor in TensorFlow. Here, we are using tf.distribute.MirroredStrategy, which replicates the model on multiple GPUs within a single machine.
You can also specify the devices to use, or use MultiWorkerMirroredStrategy for distributed training across multiple machines.
Step 3: Create and Compile Your Keras Model
In this step, we define our Keras model as usual using the Keras API. We also choose a distribution-aware optimizer compatible with tf.distribute.Strategy for distributed training. In this example, we're using the Adam optimizer.
Training Models with DTensors
In the final step after compilation, we train the Keras model using the distributed dataset we created earlier. To train the model with DTensors and leverage distributed computing, we use the distribution strategy's run() method, which coordinates the training across multiple devices or machines.
Let's delve into the final step, which is the training of the model using distributed tensors in tensorflow:
Instead of the traditional model.fit() function, we use the distribution strategy's run() method to distribute the training process across devices or machines.
-
dist_dataset:
This is the distributed dataset we prepared using tf.data.Dataset.from_tensor_slices(). The training data (features and labels) is distributed across multiple devices or machines based on the chosen distribution strategy. -
epochs:
The epochs parameter specifies the number of times the entire dataset will be processed during training. Each epoch represents one full pass through the dataset. -
steps_per_epoch:
The steps_per_epoch parameter defines the number of batches to process in one epoch. It helps control the granularity of training updates.
Output:
During the training process, you will see progress indicators for each epoch, which may look something like this:
Overview of the Training Process with Tensor in Tensorflow
During training, the distribution strategy ensures that the computation is efficiently parallelized across the distributed dataset.
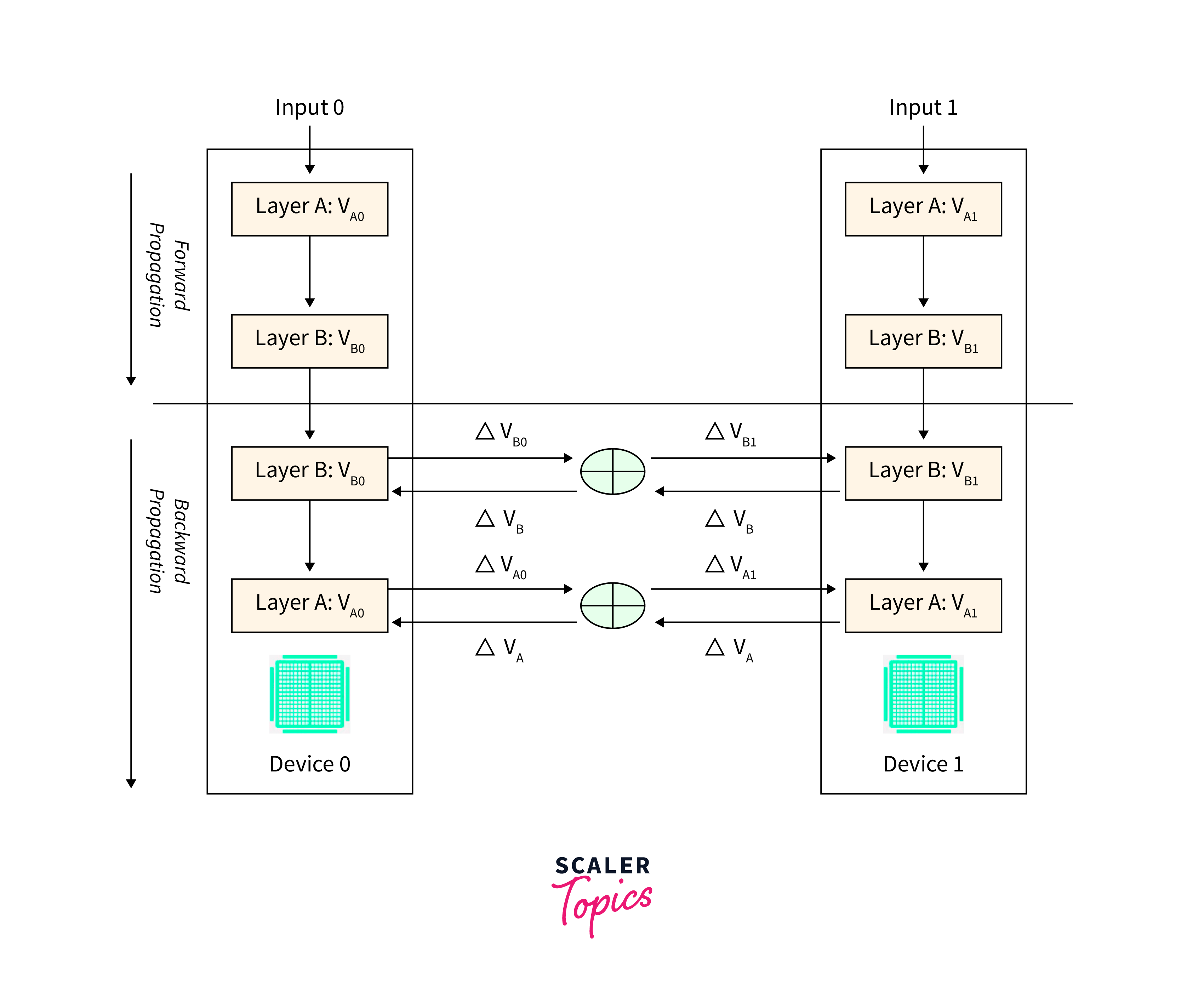
- Each device or machine processes a portion of the dataset and computes the gradients for the model parameters.
- These gradients are then synchronized across the distributed devices, and the model's parameters are updated accordingly.
- This parallelization and synchronization process allows the model to take advantage of all available computational resources and accelerates the training process.
- After the training, the model will have learned the optimal parameters for the task, making it ready for evaluation or deployment.
- Keep in mind that the performance gains from using DTensors and distributed computing may vary depending on the dataset's size, the model's complexity, and the available hardware resources.
- It is essential to experiment with different distribution strategies and hardware configurations to find the optimal setup for your specific use case.
In summary, the final step of training the model with distributed tensor in TensorFlow involves using the model.fit() function with the distributed dataset and the chosen distribution strategy. The strategy's run() method handles the parallelization and synchronization of computations across distributed devices, leading to faster and more efficient training of deep learning models.
Evaluating and Deploying Models with DTensor in Tensorflow
After training the model using DTensors, the evaluation process remains similar to traditional Keras models. You can use the model.evaluate() function to evaluate the model's performance on a dataset.
For deploying the model, once again, the process is similar to deploying non-distributed Keras models. You save the trained model using model.save(), and during inference, you load it and use it to make predictions on new data.
It's important to emphasize that the dataset used in model.evaluate() should be preprocessed and batched consistently with the training dataset. This alignment ensures accurate performance measurement and proper comparison between training and evaluation results, thereby enhancing the overall reliability of the model assessment process.
Below is a sample code for evaluating the trained model using a distributed tensor in Tensorflow and then saving it for deployment:
- In this code, we first evaluate the trained model on a test dataset using the model.evaluate() function.
- The evaluation process remains similar to traditional Keras models, and the evaluate() method will handle the distributed computations efficiently thanks to the underlying DTensors and the distribution strategy.
Next, we save the trained model using the model.save() function, standard for saving Keras models. The model will be saved in the Hierarchical Data Format (HDF5) format with the extension .h5.
Output:
For deploying the model, you can load it back using the tf.keras.models.load_model() function:
Deploying distributed models may require additional considerations, such as serving the model on a distributed inference system to handle high-throughput requests.
Benefits and Limitations of Using Distributed Tensor in TensorFlow
Let's explore the benefits and limitations of using DTensor in TensorFlow for distributed computations.
Benefits:
- Enables efficient handling of large datasets that may not fit into the memory of a single device.
- Allows parallel processing across multiple devices or machines, leading to faster training times.
- Scales deep learning models to handle complex architectures and massive datasets.
- Fault tolerance: DTensors support recovery from certain failures during distributed computations.
Limitations:
- Increased complexity:
Setting up distributed computing environments and choosing the right strategy can be more complex than single-device training. - Hardware requirements:
DTensors and distributed computing typically require access to multiple GPUs or machines. - Communication overhead:
Synchronizing gradients across distributed devices can introduce communication overhead, affecting training speed. The choice of distribution strategy should indeed be considered thoughtfully based on the model architecture, data distribution, available hardware, and training requirements. It's essential to balance factors like communication overhead, training speed, and resource utilization to optimize the distributed training process effectively. - Diminished returns:
The performance gains of distributed training may not be significant for smaller models or datasets.
Performance Considerations with a DTensor in TensorFlow
Several performance considerations must be considered when working with distributed tensors in Tensorflow.
Optimization:
- Choose an appropriate distribution strategy based on hardware resources and network bandwidth.
- Utilize batch processing to reduce communication overhead and improve training speed.
- Profile your model and data distribution to identify potential bottlenecks and areas for optimization.
Hardware and Environment:
- Ensure sufficient GPU memory and processing power for handling the distributed computation.
- Use high-bandwidth interconnects between devices or machines for faster communication.
- Set up a distributed file system or cloud storage to efficiently manage large datasets.
Parallelization:
- Exploit model parallelism when working with models that do not fit into the memory of a single device.
- Leverage data parallelism for training on multiple devices with smaller subsets of the dataset.
Real-World Applications of a DTensor in TensorFlow
Distributed tensor in TensorFlow is vital in enabling scalable and high-performance deep learning solutions in the era of big data and advanced AI technologies.
The below real-world applications demonstrate the versatility and significance of DTensors in various industries, where efficient distributed computing is essential to tackle complex problems and handle extensive datasets.
-
Healthcare and Medical Imaging:
DTensors are valuable in medical imaging applications, where large volumes of data, such as CT scans or MRI images, must be processed. Distributed deep-learning models can aid in diagnosing diseases, detecting anomalies, and predicting patient outcomes.
-
Autonomous Vehicles:
The development of autonomous vehicles relies heavily on deep learning models to process vast amounts of sensor data, such as images, lidar, and radar inputs. DTensors enable parallel processing of this data, facilitating real-time decision-making for safe navigation.
-
Financial Services:
DTensors can be utilized for various applications, including fraud detection, credit risk assessment, and algorithmic trading in the financial sector. The parallel computation capabilities of DTensors accelerate the processing of large-scale financial datasets. -
Natural Language Processing (NLP):
NLP tasks, such as language translation, sentiment analysis, and chatbots, often involve complex deep learning models. A DTensor in Tensorflow aids in training these models on extensive text corpora, enabling efficient language understanding and generation. Distributed tensors play a pivotal role in empowering large language models to comprehend and generate human language at an unprecedented scale, revolutionizing the field of NLP and fostering breakthroughs in language-related applications.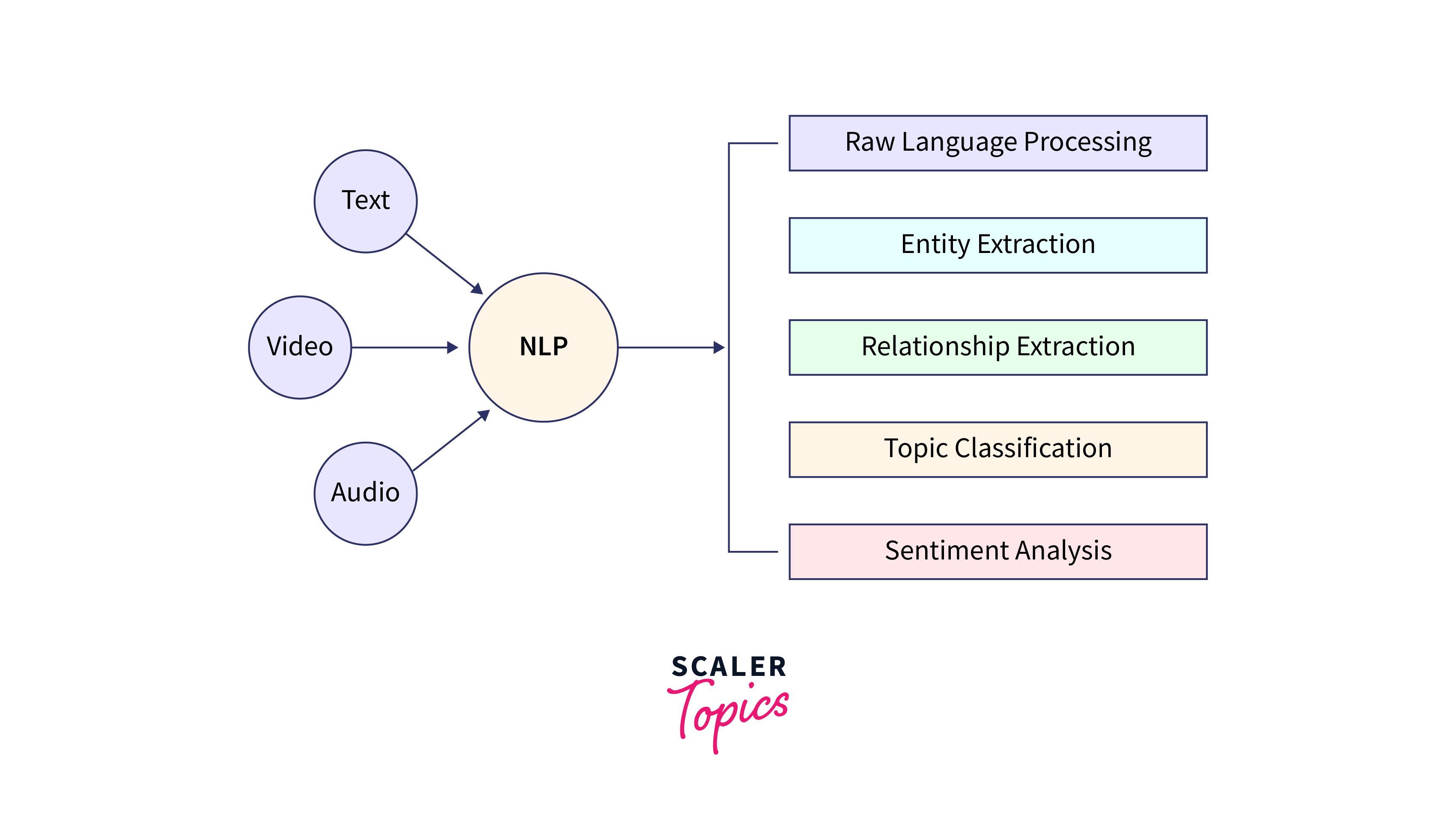
-
Weather Forecasting and Climate Modeling:
Weather forecasting and climate modeling require large amounts of meteorological data processing. DTensors can be employed to parallelize the training of complex deep-learning models, improving the accuracy and speed of weather predictions.
Conclusion
- In conclusion, distributed tensor in TensorFlow is a powerful tool in the deep learning toolkit, offering scalability, efficiency, and the potential for groundbreaking AI and machine learning achievements.
- As the technology evolves, we can anticipate even more transformative applications and advancements fueled by the distributed capabilities of DTensors in TensorFlow.