Thresholding In Image Processing
Overview
Thresholding in image processing is a commonly used technique that involves converting an image into a binary image by separating the pixels into two classes based on their intensity values. The process involves selecting a threshold value, which acts as a boundary between the two classes. Pixels with intensity values above the threshold are assigned one value, usually white, while those below the threshold are assigned another value, usually black. Thresholding is useful for a range of applications, including image segmentation, object detection, and image binarization. It is a simple yet powerful technique that can help to simplify complex images and make them easier to analyze and process.
Introduction
Image processing is a complex field that involves the analysis, manipulation, and interpretation of digital images. One of the most fundamental techniques in image processing is image thresholding, which involves the conversion of a grayscale or colour image into a binary image. This process is achieved by separating an image into two parts,foregroundand background, based on the intensity of the pixels.
In a grayscale image, each pixel is represented by an intensity value that ranges from 0 (black) to 255 (white). Thresholding in image processing involves selecting a threshold value, which acts as a boundary between the two classes. Pixels with intensity values above the threshold are assigned one value, usually white, while those below the threshold are assigned another value, usually black. This results in a binary image that contains only two values: 0 and 1.

What is Image Thresholding?
Thresholding in image processing is the task of selecting a threshold value to separate the pixels of an image into two classes: foreground and background. In simple terms, thresholding involves assigning a value of 0 or 1 to each pixel in the image, based on whether its intensity is above or below the selected threshold value.
![]()
Need of Image Thresholding
Image thresholding is necessary to separate the object or the area of interest from the background of an image. This technique helps in enhancing the features of a thresholding image and makes it easier to detect or recognize objects in an image.
- It is also useful in thresholding image segmentation, which is the process of dividing an image into multiple segments or regions with similar properties.
- For example, in medical imaging, thresholding is used to identify tumours or abnormal tissues in a scan. In industrial inspection, it is used to detect defects in products or to check the quality of goods.
- In machine vision, thresholding is used to identify objects or obstacles in an image and to guide the movement of robots or autonomous vehicles.
- Overall, thresholding in image processing is a crucial technique in image processing that has a wide range of applications in various fields.

Understanding Different Thresholding Techniques
Simple Thresholding
Simple Thresholding is the most basic type of thresholding, which involves selecting a single threshold value to convert a grayscale image into a binary image. Pixels with intensity values above the threshold are set to white, and those below the threshold are set to black. The threshold value can be selected manually or automatically using methods such as Otsu's method.
The input characteristics of simple thresholding include an input image, which can be grayscale or colour, and a threshold value. The output characteristics include a binary image with two values (0 and 255), where 0 represents the background and 255 represents the foreground.
Overall, simple thresholding is a widely used technique in image processing that can be used for a variety of applications. It is a straightforward technique that can be easily implemented using various programming languages and software tools.
Here is a table that shows the different types of Simple Thresholding:
| Type | Description |
|---|---|
| THRESH_BINARY | Pixel values above the threshold are set to 255, otherwise 0 |
| THRESH_BINARY_INV | Pixel values above the threshold are set to 0, otherwise 255 |
| THRESH_TRUNC | Pixel values above the threshold are set to the threshold value, otherwise unchanged |
| THRESH_TOZERO | Pixel values above the threshold are unchanged, otherwise set to 0 |
| THRESH_TOZERO_INV | Pixel values above the threshold are set to 0, otherwise unchanged |
Each type has a specific use case, depending on the nature of the image and the application.

Implementation of Simple Thresholding using OpenCV
The methodology of simple thresholding involves the following steps:
Input: The first step is to select the image that needs to be thresholded. This image can be a grayscale or colour image.
Conversion: If the input image is a colour image, it needs to be converted to a grayscale image. This can be done by taking the average of the red, green, and blue colour channels.
Threshold selection: The next step is to select a threshold value. This value will be used to separate the image into two classes: foreground and background. This threshold can be selected manually or automatically using an algorithm.
Thresholding: The thresholding process involves comparing each pixel in the input image with the selected threshold. If the pixel value is greater than or equal to the threshold, it is assigned a value of 255 (white). If the pixel value is less than the threshold, it is assigned a value of 0 (black).
Output: The output of simple thresholding is a binary image, which contains only two values: 0 and 255.
Here is an example of how to implement Simple Thresholding in image processing using the OpenCV library in Python:
In the above example, we first read an image in grayscale using the cv2.imread() function. Then we apply Simple Thresholding using the cv2.threshold() function, which takes the following parameters:
| Parameter Name | Parameter Value | Description |
|---|---|---|
| img | Input Image | The input image to be thresholded |
| 127 | Threshold Value | The threshold value that is used to separate the foreground and background pixels |
| 255 | Maximum Value | The maximum value assigned to pixels above the threshold |
| cv2.THRESH_BINARY | Thresholding Type | The type of thresholding applied to the image is binary |
The table above summarizes the parameters used in the example of simple thresholding in image processing, including the input image, the threshold value, the maximum value assigned to pixels above the threshold, and the thresholding type, which is set to binary. These parameters are used in the OpenCV library function cv2.threshold() to perform the image thresholding operation.
The function returns two values: ret and threshold. The threshold value is the resulting binary image.
Finally, we display the result using the cv2.imshow() function and wait for the user to press a key before closing the window using cv2.waitKey() and cv2.destroyAllWindows() functions.
Output:

Otsu’s Thresholding
Otsu’s Thresholding is a widely used automatic thresholding technique that selects the threshold value based on the distribution of pixel intensities in the image. This technique minimizes the intra-class variance, which is the variance within the classes of pixels defined by the threshold. It works best for images with bimodal intensity distributions, where the pixel intensities are divided into two distinct groups.
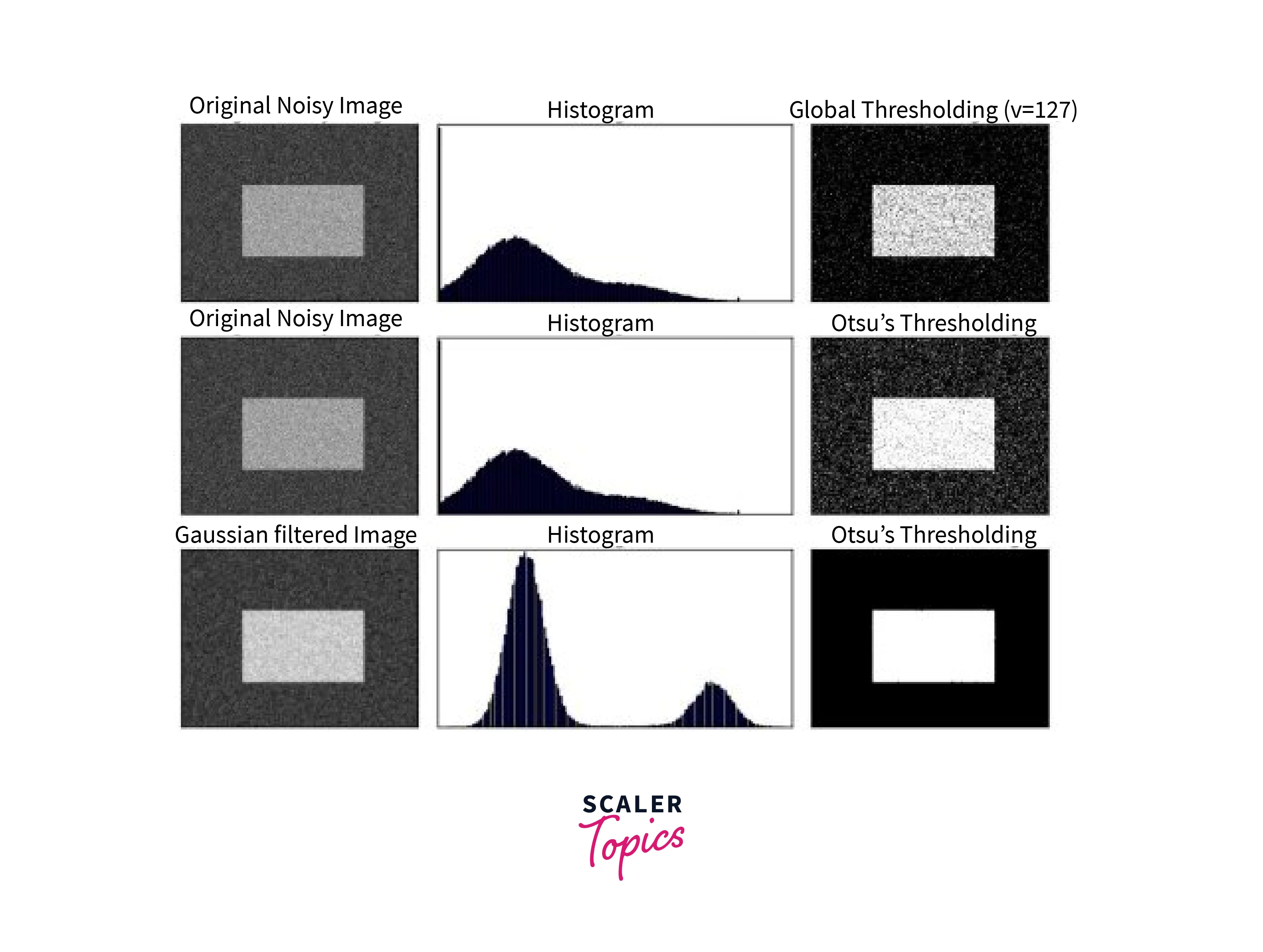
How does Otsu’s thresholding work?
Otsu’s thresholding in image processing works by calculating the optimal threshold value that separates the pixel intensities into two classes such that the intra-class variance is minimized. The intra-class variance is calculated as the sum of the variances of the two classes weighted by their probabilities. The threshold value that results in the minimum intra-class variance is selected as the optimal threshold.
In Otsu's method, the threshold value is not specified as an input parameter. Instead, the algorithm calculates the optimal threshold value based on the histogram of the input image. The cv2.THRESH_BINARY+cv2.THRESH_OTSU parameter is used to specify the thresholding type as Otsu's method. This method calculates the threshold value automatically based on the image histogram, which makes it a good choice for images with variable lighting conditions. The 255 parameter specifies the maximum value assigned to pixels above the threshold, which in this case is set to white.
Implementation of Otsu’s Thresholding Here is an example of how to implement Otsu’s Thresholding in image processing using the OpenCV library in Python:
Note: The input image for Otsu's thresholding should be a grayscale image with pixel values ranging from 0 to 255.
In the above example, we first read an image in grayscale using the cv2.imread() function. Then we apply Otsu’s Thresholding using the cv2.threshold() function, which takes the following parameters:
| Parameter Name | Parameter Value | Description |
|---|---|---|
| img | Input Image | The input image to be thresholded |
| 0 | Threshold Value | This parameter is not used in Otsu's method. |
| 255 | Maximum Value | The maximum value assigned to pixels above the threshold |
| cv2.THRESH_BINARY+cv2.THRESH_OTSU | Thresholding Type | The type of thresholding applied to the image, which is set to Otsu's method. |
The function returns two values: ret and threshold. The ret value is the threshold value used by the function, which is automatically selected by Otsu's method. The threshold value is the resulting binary image.
Finally, we display the result using the cv2.imshow() function and wait for the user to press a key before closing the window using cv2.waitKey() and cv2.destroyAllWindows() functions.
Input Image:

Output:

Otsu’s thresholding is a powerful technique for automatic thresholding, especially for images with bimodal intensity distributions. It eliminates the need for manual selection of the threshold value and can improve the accuracy and robustness of image processing algorithms.
Adaptive Thresholding
Adaptive Thresholding is a thresholding technique that calculates the threshold for each pixel based on the local neighbourhood of the pixel. It is useful when the lighting conditions are uneven or the image has varying background intensities.
The input image for adaptive thresholding should be a grayscale image with values ranging from 0 to 255. It can be a 2D array or a multi-channel image with the same intensity values across all channels. The size and quality of the input image can also affect the performance of the adaptive thresholding algorithm. Ideally, the image should have sufficient contrast and minimal noise to produce accurate thresholding results. The size of the image can also impact the speed of computation and memory requirements.
Implementation of Adaptive thresholding using OpenCV
Here is an example of how to implement Adaptive Thresholding in image processing using the OpenCV library in Python:
In the above example, we first read an image in grayscale using the cv2.imread() function. Then we apply Adaptive Thresholding using the cv2.adaptiveThreshold() function, which takes the following parameters:
| Parameter Name | Parameter Value | Description |
|---|---|---|
| img | Input Image | The input image to be thresholded |
| 255 | Maximum Value | The maximum value assigned to pixels above the threshold |
| cv2.ADAPTIVE_THRESH_MEAN_C | Adaptive Thresholding Type | The type of adaptive thresholding applied to the image, which is set to mean thresholding. |
| cv2.THRESH_BINARY | Thresholding Method | The method used to convert the pixels below the threshold to 0 (black) and above the threshold to 255 (white). |
| 11 | Neighborhood Size | The size of the local neighbourhood used for threshold calculation |
| 2 | Constant Subtraction | A constant subtracted from the mean or weighted mean of the local neighbourhood. |
The function returns a binary image where the pixel values are set to 255 if the pixel intensity is above the adaptive threshold and 0 if the pixel intensity is below the threshold.
Finally, we display the result using the cv2.imshow() function and wait for the user to press a key before closing the window using cv2.waitKey() and cv2.destroyAllWindows() functions.
Input Image:

Output:

Adaptive thresholding is useful when the lighting conditions are uneven or the image has varying background intensities. It calculates the threshold for each pixel based on the local neighbourhood of the pixel, which can improve the accuracy and robustness of image processing algorithms.
Segmentation using Thresholding
Segmentation is the process of dividing an image into multiple segments or regions, each representing a different object or background in the image. Thresholding in image processing is a widely used technique for segmentation, where the image is converted to a binary image by assigning pixel values above or below a threshold to different classes.

Thresholding in image processing can be used for a variety of segmentation tasks, such as object detection, feature extraction, and image enhancement. Here are some common segmentation tasks and the corresponding thresholding techniques used:
-
Object detection: Simple thresholding, Otsu’s thresholding, or adaptive thresholding can be used depending on the image characteristics.
-
Feature extraction: Adaptive thresholding or multiple thresholding can be used to segment the image into multiple regions representing different features.
-
Image enhancement: Thresholding can be used to enhance the contrast or remove noise from the image by setting a suitable threshold.
The input image specification for segmentation depends on the specific segmentation task and the method used for segmentation. In general, the input image should be in a format compatible with the chosen segmentation method, such as grayscale or colour images, with appropriate dimensions and pixel values. It may also be necessary to preprocess the image, such as by resizing, normalizing, or smoothing the image.
Additionally, the input image may require labelling or annotation to provide ground truth data for supervised segmentation methods. Ultimately, the goal is to prepare the input image in a way that maximizes the accuracy and effectiveness of the segmentation process.
Segmentation is a broad field in image processing that involves dividing an image into different regions or segments. There are many techniques for image segmentation, but one common method is thresholding. Here is an example code in Python using the OpenCV library for thresholding and segmenting an image:
In this code, we first load an image using the cv2.imread() function and convert it to grayscale using the cv2.IMREAD_GRAYSCALE flag. Then, we apply thresholding using the cv2.threshold() function with a threshold value of 127, maximum value of 255, and threshold type set to binary. This converts the grayscale image into a binary image with only two possible pixel values: 0 (black) and 255 (white).
Next, we apply segmentation using the cv2.findContours() function, which identifies the contours or boundaries of objects in the binary image. The cv2.RETR_TREE and cv2.CHAIN_APPROX_SIMPLE parameters specify the retrieval mode and contour approximation method, respectively.
Finally, we draw the contours on the original image using the cv2.drawContours() function and display the result using the cv2.imshow() function.
Output

Introduction to UNet: Deep Learning Model for Image Segmentation
UNet is a deep learning architecture that was developed for image segmentation tasks. It was first introduced by Olaf Ronneberger, Philipp Fischer, and Thomas Brox in 2015.
The architecture of UNet is based on the fully convolutional neural network (FCN) and it has to skip connections between the encoder and decoder layers to preserve spatial information.
The skip connections allow the model to combine low-level and high-level features, which is particularly useful for image segmentation tasks.
UNet has become a popular choice for various image segmentation tasks such as medical image segmentation, satellite image segmentation, and natural image segmentation due to its high accuracy and efficiency.
U-Net Architecture
- The architecture of UNet consists of two main parts: the contracting path (encoder) and the expansive path (decoder).
- The encoder consists of several convolutional layers followed by a max pooling layer, which reduces the spatial dimensions of the input.
- The decoder consists of several upsampling layers followed by convolutional layers, which increase the spatial dimensions of the input.
- The skip connections between the encoder and decoder layers allow the model to combine low-level and high-level features, which is particularly useful for image segmentation tasks.
Here is the architecture of the UNet model:

Implementation of UNet using Keras
Now, let us define several functions for building a UNet model in Keras. The code for the implementation of UNet using Keras is divided into four main parts/functions:
1. ConvBlock 2. EncoderBlock 3. DecoderBlock 4. UNet Function
Let's dive deep into how each of the functions is implemented.
1. The 'ConvBlock' The ConvBlock function creates a block of two convolutional layers with batch normalization and ReLU activation functions. The ConvBlock function is used in the U-Net model's encoder part to extract features from the input tensor. It creates two convolutional layers with batch normalization and ReLU activation functions.
The function takes an input tensor, number of filters, and kernel size, and returns the output tensor of the second convolutional layer.
2. The EncoderBlock The EncoderBlock function defines the encoder block of the UNet, which takes an input tensor, applies a ConvBlock, and then applies max pooling. The EncoderBlock function uses the ConvBlock function to create two convolutional layers with batch normalization and ReLU activation functions, followed by a max pooling layer to downsample the features.
The function takes an input tensor, number of filters, and kernel size, and returns both the output tensor of the max pooling layer and the output tensor of the second convolutional layer.
3. The DecoderBlock The DecoderBlock function defines the decoder block of the UNet, which takes an input tensor, applies transposed convolutional layer, concatenates with the corresponding encoder block output, and then applies a ConvBlock.
The DecoderBlock function uses a transposed convolutional layer to upsample the input tensor, concatenates it with a tensor from the corresponding encoder block, and passes it through a ConvBlock function that performs two convolutional layers with batch normalization and ReLU activation.
The function takes input and concatenation tensors, number of filters, and kernel size, and returns the output tensor.
4. The UNet function The UNet function defines the full UNet architecture by chaining together several encoder and decoder blocks. The function takes as input the input shape and number of classes and returns a Keras model.
This code defines the UNet model using the Keras library. The model consists of a series of encoder and decoder blocks, with each block including a convolutional layer, batch normalization, and ReLU activation. The encoder blocks downsample the input image, while the decoder blocks upsample it.
The final output is produced by a softmax activation function applied to a 1x1 convolutional layer. The model takes as input an image with the specified shape and outputs an image segmented into the specified number of classes.
Conclusion
- Thresholding in image processing is a fundamental technique in image processing used for image segmentation. It is the process of separating objects from the background based on a predefined threshold value.
- Simple thresholding image is the most basic form of thresholding that segments the image based on a fixed threshold value. Otsu’s thresholding is a more advanced method that calculates the optimal threshold value using a histogram-based approach.
- Adaptive thresholding image is another technique used to segment images, which adapts the threshold value based on the local image characteristics.
- Thresholding is widely used in various fields such as medical imaging, computer vision, and pattern recognition to extract meaningful information from images.