Understanding Transformer-XL
Transformer-XL is an advanced language model that extends the Transformer architecture to address the fixed-length context limitation. Introduced by Dai et al. in "Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context" it excels in capturing long-range dependencies and maintaining context in longer sequences. This model is crucial for tasks like language generation, document understanding, and machine translation where extended context matters. It enhances the original Transformer with innovative components, making it a powerful tool for natural language processing.
Need for Advanced Language Models
-
Long-range Dependencies: Many NLP tasks, such as understanding complex sentences or documents, require considering relationships between words or phrases that are far apart from each other in the text. Fixed-length context models may struggle to capture such long-range dependencies effectively.
-
Context Limitation: Traditional Transformers have a fixed context window, which means they can only consider a limited number of preceding tokens. As a result, they might lose crucial information from distant tokens that could impact the current prediction.
-
Difficulty in Capturing Continuity: In some cases, understanding the continuity of ideas or maintaining consistency across long passages is essential for coherent language modeling. Fixed-length models might face challenges in maintaining such continuity.
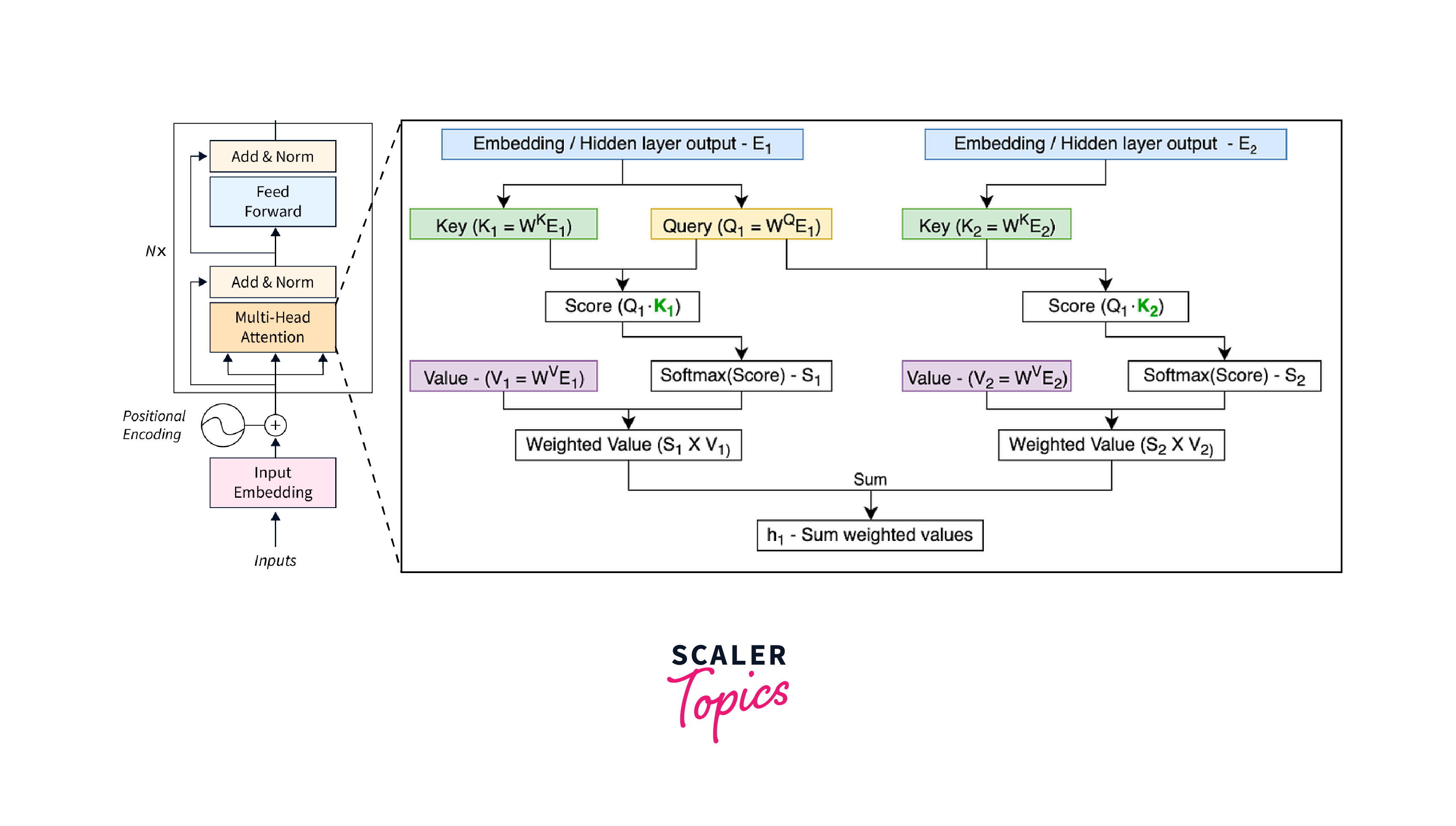
Challenges in Language Modeling
Language modeling poses several challenges that need to be addressed to build effective models:
-
Vanishing Gradient: In deep neural networks, including Transformers, vanishing gradients can be a problem. During training, as gradients are propagated back through the network, they can become extremely small in earlier layers, leading to difficulty in updating the weights effectively.
-
Computational Complexity: Transformers, especially with large context windows, can be computationally expensive, both in terms of memory usage and processing time.
-
Memory Constraints: For traditional Transformers, the context window size is limited by the available memory. Long texts may need to be truncated, leading to information loss and potentially affecting model performance.
Transformer-XL attempts to overcome these challenges by introducing a novel approach to handle long-range dependencies and enabling the model to learn from a much larger context without encountering the issues related to fixed-length contexts.
Introduction to Transformer-XL
Transformer-XL,incorporates several novel mechanisms to address the challenges faced in handling long-range dependencies in language modeling tasks.The key innovation of Transformer-XL is the introduction of the relative positional encoding mechanism and a novel recurrence mechanism. These additions enable the model to consider past information from segments of varying lengths, effectively extending the context window and capturing long-term dependencies in a more efficient manner.Transformer-XL provides state-of-the-art performance on various language modeling benchmarks and demonstrates its effectiveness in handling very long sequences, making it a powerful tool for NLP applications.
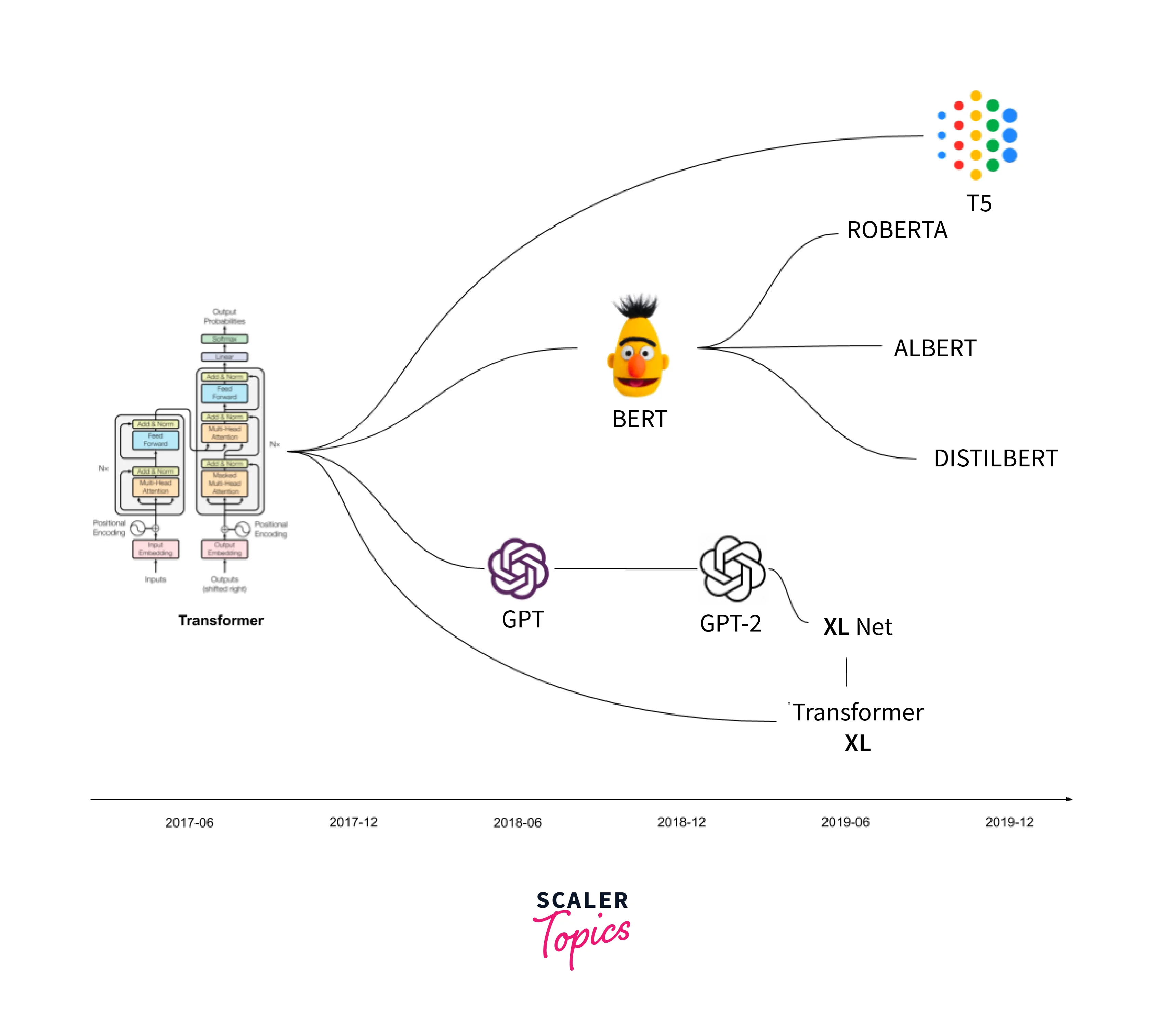
1. Evolution of Transformer Models
-
As said before ,The original Transformer model was introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017. It marked a significant departure from previous NLP architectures by introducing the self-attention mechanism.
-
Following the success of the original Transformer, researchers began exploring ways to overcome its limitations, particularly the fixed context window. The next evolution came with models like GPT-2 and BERT, which introduced techniques such as transformer-based decoder-only and masked language modeling, respectively.
-
However, Transformer-XL takes a step further by introducing a memory mechanism that allows the model to learn from an arbitrary length of context, significantly improving its ability to handle long-range dependencies in language modeling tasks.
2. Key Components of Transformer-XL
Transformer-XL extends the original Transformer architecture with novel components to address the challenges of long-range dependencies.
The key components of Transformer-XL include:
-
Segment-Level Recurrence: Transformer-XL introduces a segment-level recurrence mechanism that allows the model to maintain information across segments of text. This helps the model to remember important context from distant tokens, thereby addressing the limitations of fixed context windows.
-
Relative Positional Encoding: Transformer-XL uses relative positional encodings to capture the relative distances between tokens. These encodings are more efficient and effective in modeling long-range dependencies compared to the absolute positional encodings used in traditional Transformers.
-
Adaptive Computation Time: To handle longer sequences efficiently, Transformer-XL employs adaptive computation time, which dynamically adjusts the number of operations performed on each token, allocating more computational resources to tokens that require deeper processing.
Advantages of Transformer-XL
Transformer-XL offers several advantages over traditional language models. Some of the key advantages include:
-
Handling Long-Range Dependencies: Transformer-XL's segment-level recurrence and relative positional encoding mechanisms enable the model to effectively capture long-range dependencies in the text, making it better suited for tasks that require a deeper understanding of context.
-
Coherent Language Modeling: The ability to learn from a larger context helps Transformer-XL maintain continuity and coherence in language modeling, resulting in more coherent and contextually accurate generated text.
-
Improved Performance on Long Sequences: By introducing adaptive computation time and addressing the limitations of fixed context windows, Transformer-XL is better equipped to handle longer sequences efficiently, overcoming memory and computational constraints.
Overall, Transformer-XL represents a significant advancement in language modeling, providing a more powerful and flexible architecture for various NLP tasks.
Positional Encoding in Transformer-XL
-
Positional encoding is a crucial component in the Transformer model architecture. It provides information about the order and position of words in a sequence, allowing the model to understand the context and avoid treating words with the same embeddings as identical.
-
In the original Transformer model, positional encoding is computed using sine and cosine functions with different frequencies. However, this fixed positional encoding poses limitations when dealing with very long sequences. Transformer-XL introduces relative positional encoding to overcome these limitations and improve the model's ability to handle long-range dependencies.
-
Positional encoding provides a positional signal that is added to the token embeddings. This positional signal is combined with the semantic information captured by the embeddings, giving the model the ability to differentiate between tokens based on their positions.
Relative Positional Encoding in Transformer-XL
In the original Transformer, positional encoding is fixed and does not adapt to the content of the input sequence. Transformer-XL addresses this limitation by introducing relative positional encoding.
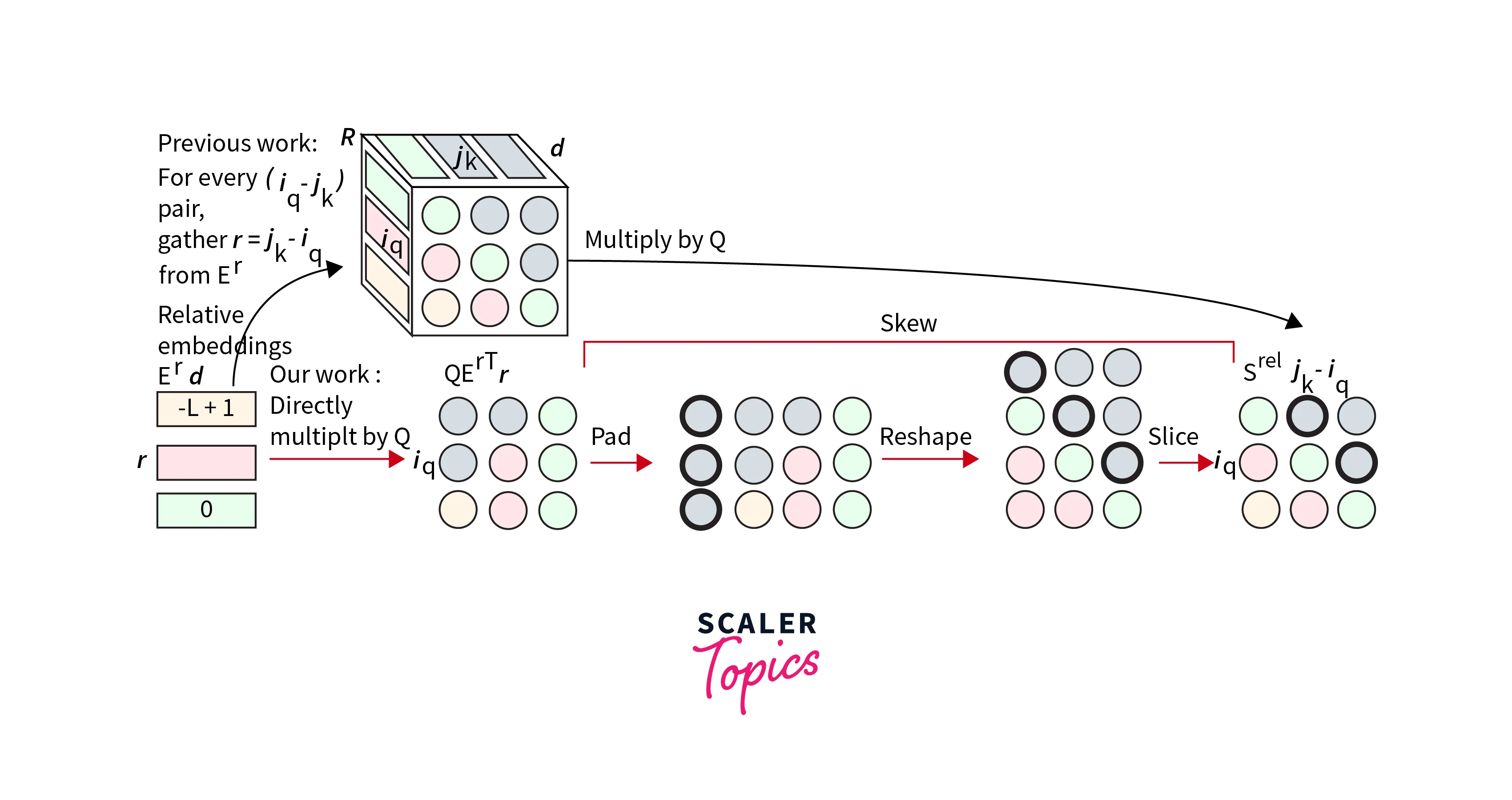
In relative positional encoding, the model computes the relative distances between tokens and uses this information to adjust the attention scores during the self-attention step. This enables the model to attend to tokens with respect to their relative positions, making it more effective in handling long-range dependencies.
The relative positional encoding is implemented by parameterizing the attention scores based on the relative distance between tokens. This allows the model to consider the importance of tokens with respect to their positions in the context window.
Handling Long-Term Dependencies
-
One of the key challenges in language modeling is capturing long-term dependencies between words that are far apart in the sequence. Traditional sequential models like RNNs struggle to maintain such dependencies over long distances, leading to suboptimal performance.
-
Transformer-XL's relative positional encoding addresses this challenge by providing a dynamic and context-aware way to compute attention scores between tokens. By considering relative distances, the model can capture long-term dependencies more effectively and make better predictions for tasks involving lengthy text.
-
The ability to handle long-term dependencies is crucial for many NLP applications, such as machine translation, text generation, and document understanding. Transformer-XL's relative positional encoding makes it a powerful tool for these tasks, enabling the model to consider a broader context and generate more coherent and contextually relevant output.
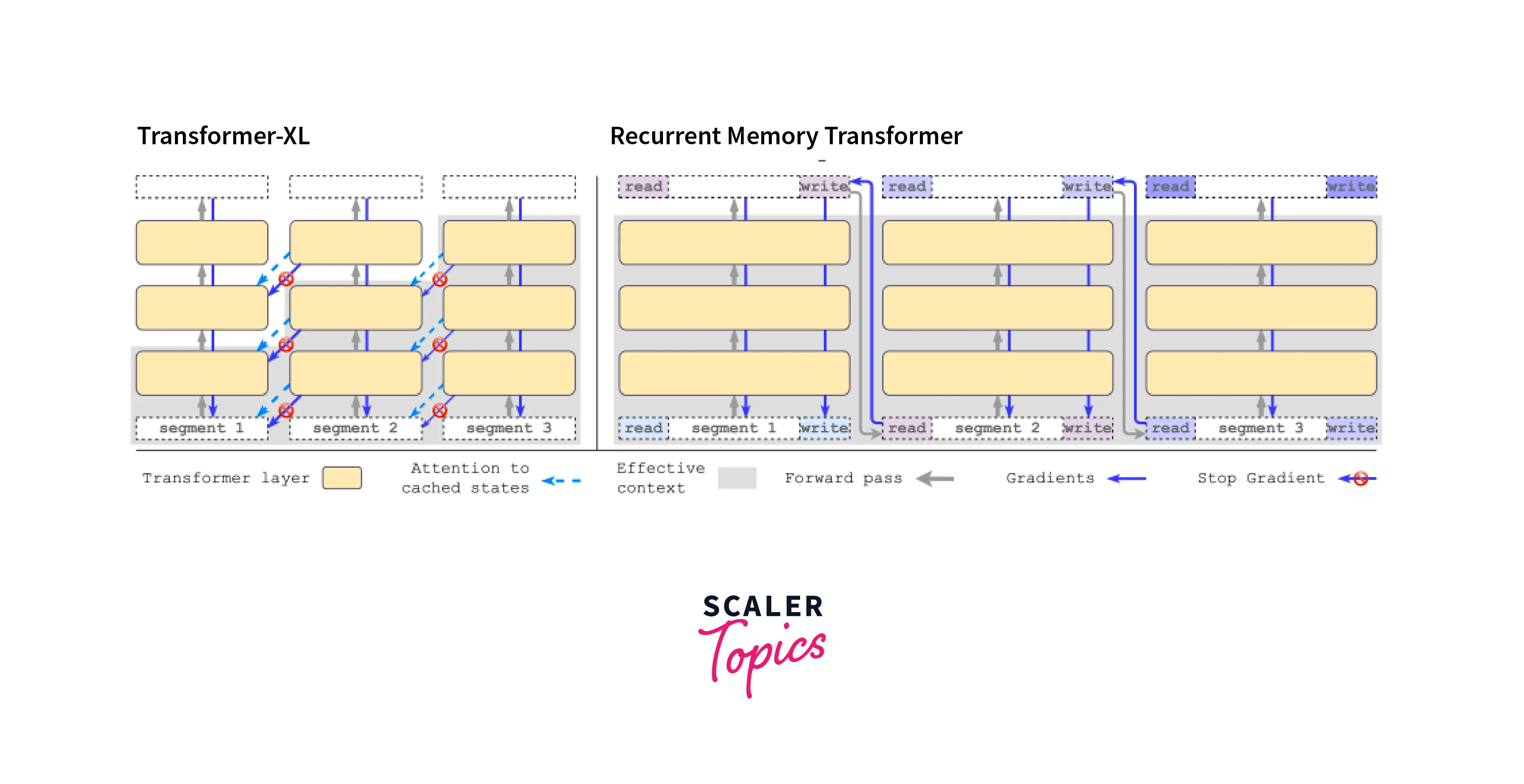
Memory Computation in Transformer-XL
Memory computation is a critical aspect of Transformer-XL that enables the model to efficiently handle very long sequences. In traditional Transformer models, the context window is fixed, which limits their ability to maintain long-range dependencies. Transformer-XL overcomes this limitation by dynamically computing memory for each segment, providing a more scalable solution for processing lengthy texts.
-
Recurrence Mechanism
Transformer-XL introduces a recurrence mechanism that enables the model to maintain a memory state and utilize past information from previous segments. This extension significantly improves the model's ability to capture long-range dependencies and enhances its context window.
The recurrence mechanism allows the model to consider information from previous segments when processing the current segment. By retaining the memory state across segments, the model can effectively capture dependencies between tokens that are far apart in the sequence.
-
Memory States and Segments
In Transformer-XL, the memory state is associated with different segments of the input sequence. A segment is a contiguous portion of the text, and the model maintains hidden states for each segment. These hidden states capture the contextual information of the segment and are updated as new tokens are processed.
The memory states are updated during the recurrence mechanism, allowing the model to utilize information from past segments when processing the current segment. This adaptive segmentation enables the model to handle long-range dependencies without overwhelming memory requirements.
-
Utilizing Context from Previous Segments
The recurrence mechanism in Transformer-XL plays a vital role in capturing context from previous segments. During training and inference, the model maintains hidden states for each segment, allowing it to utilize context information from past segments.
This ability to consider context from previous segments is crucial for understanding long sequences. For example, in a language modeling task, a word in the current segment may be influenced by a word that appeared several segments ago. The recurrence mechanism enables the model to retain this contextual information and make more informed predictions.
-
Adaptive Segmentation in Transformer-XL
One of the significant advantages of Transformer-XL is its adaptive segmentation approach. Traditional Transformer models use fixed context windows, which limits their ability to handle long sequences. Transformer-XL overcomes this limitation by adapting the length of segments based on the number of tokens in each segment.
By dynamically adjusting the segmentation length, Transformer-XL ensures that each segment captures sufficient context without overwhelming the memory. This adaptive segmentation mechanism allows the model to process longer sequences efficiently, making it suitable for tasks involving very long text.
-
Segment-Level Recurrence
The model maintains hidden states for each segment, allowing it to perform segment-level recurrence. This means that the model can adjust the length of segments and maintain hidden states across segments. This flexibility enhances the model's ability to capture long-range dependencies across segments.
-
Adaptive Lengths of Segments
Transformer-XL's adaptive segmentation enables it to handle sequences of varying lengths effectively. The model can process texts with different numbers of tokens without the need for manual segmentation or truncation. This is particularly beneficial for applications that involve processing documents, articles, or other texts of different lengths.
-
Managing Segment-Level States
The model's ability to maintain hidden states at the segment level is a crucial feature that allows it to capture long-range dependencies. By managing segment-level states, Transformer-XL can make more informed predictions and generate coherent output, even for very long sequences.
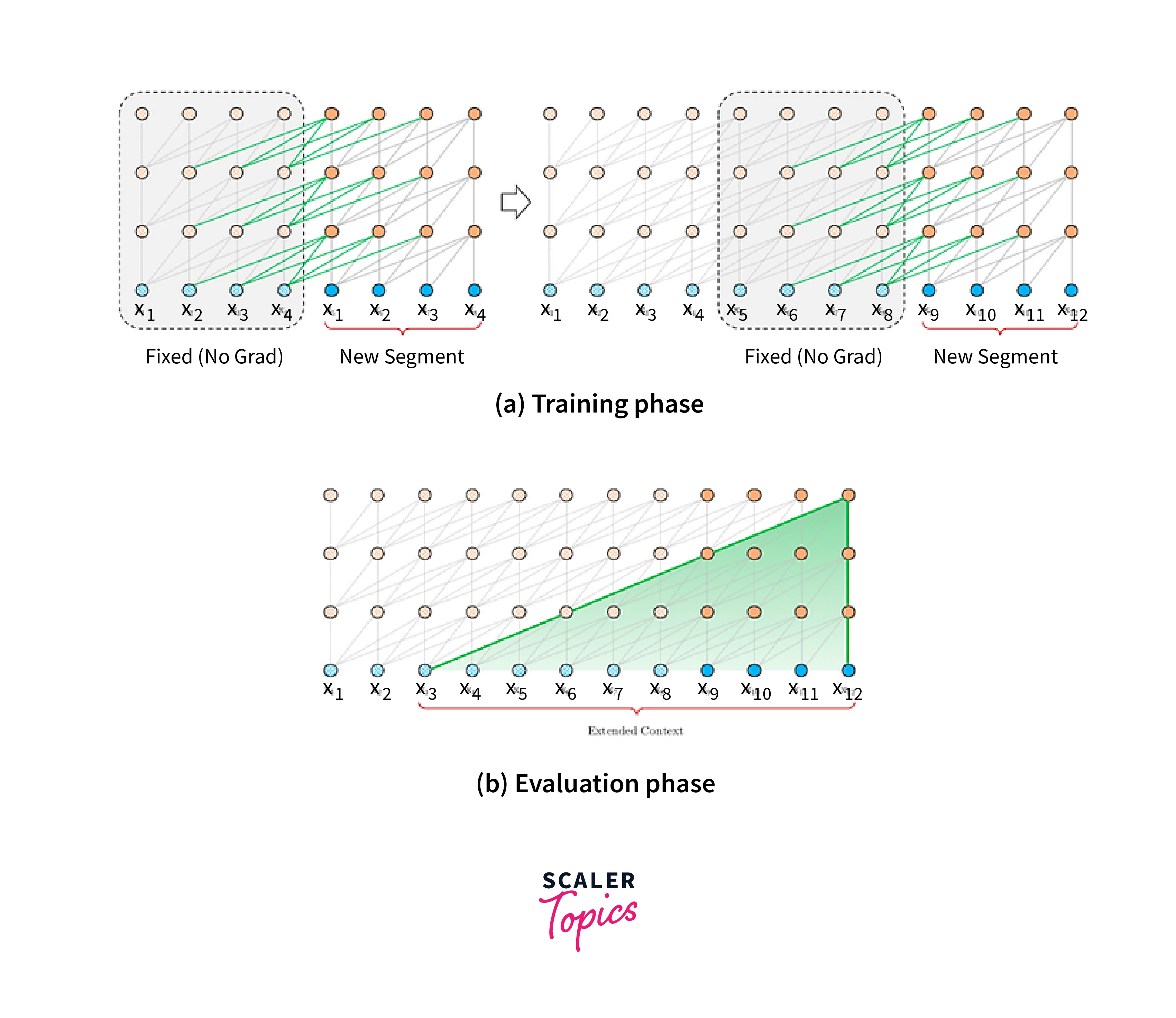
Training and Inference in Transformer-XL
Training Transformer-XL involves pre-training the model on a large corpus of text and then fine-tuning it for specific downstream NLP tasks. The pre-training process involves language modeling objectives to enable the model to learn the statistical properties of the language and capture meaningful patterns in the data.
Pre-training and Fine-tuning
The pre-training phase involves training the model on a vast amount of text data using unsupervised learning. During pre-training, the model learns to predict the next word or token in a sequence given the context of previous words. This is typically achieved through masked language modeling, where a percentage of tokens in the input sequence are randomly masked, and the model predicts them based on the remaining tokens.
Fine-tuning allows the model to adapt its pre-learned knowledge to the specific nuances of the target task, resulting in improved performance on the task at hand.
The provided code demonstrates how to fine-tune a pretrained TransfoXL model for sequence classification using the IMDb reviews dataset.
1. Importing Required Libraries and Loading Data
The code then initializes the TransfoXL tokenizer and model using the pretrained weights from the 'transfo-xl-wt103' checkpoint.
Next, the IMDb reviews dataset is loaded using tensorflow_datasets, and the training, validation, and test splits are extracted.
2. Preprocessing Data The code then performs some data preprocessing on the training and validation sets. It batches the data, converts text inputs from bytes to strings, and separates inputs and targets.
3. Fine-Tuning the Model The code now moves into the process of fine-tuning the pretrained TransfoXL model on the IMDb reviews dataset. It uses a loop to iterate through a subset of the data (100 instances) for both training and validation.
Inside the loop, for each input-text and target pair, the model is used to calculate the loss. The loss is calculated using the model with the provided inputs, targets, and the tokenizer's encoding.
After calculating losses for each sample, the average loss is computed using np.mean(losses).
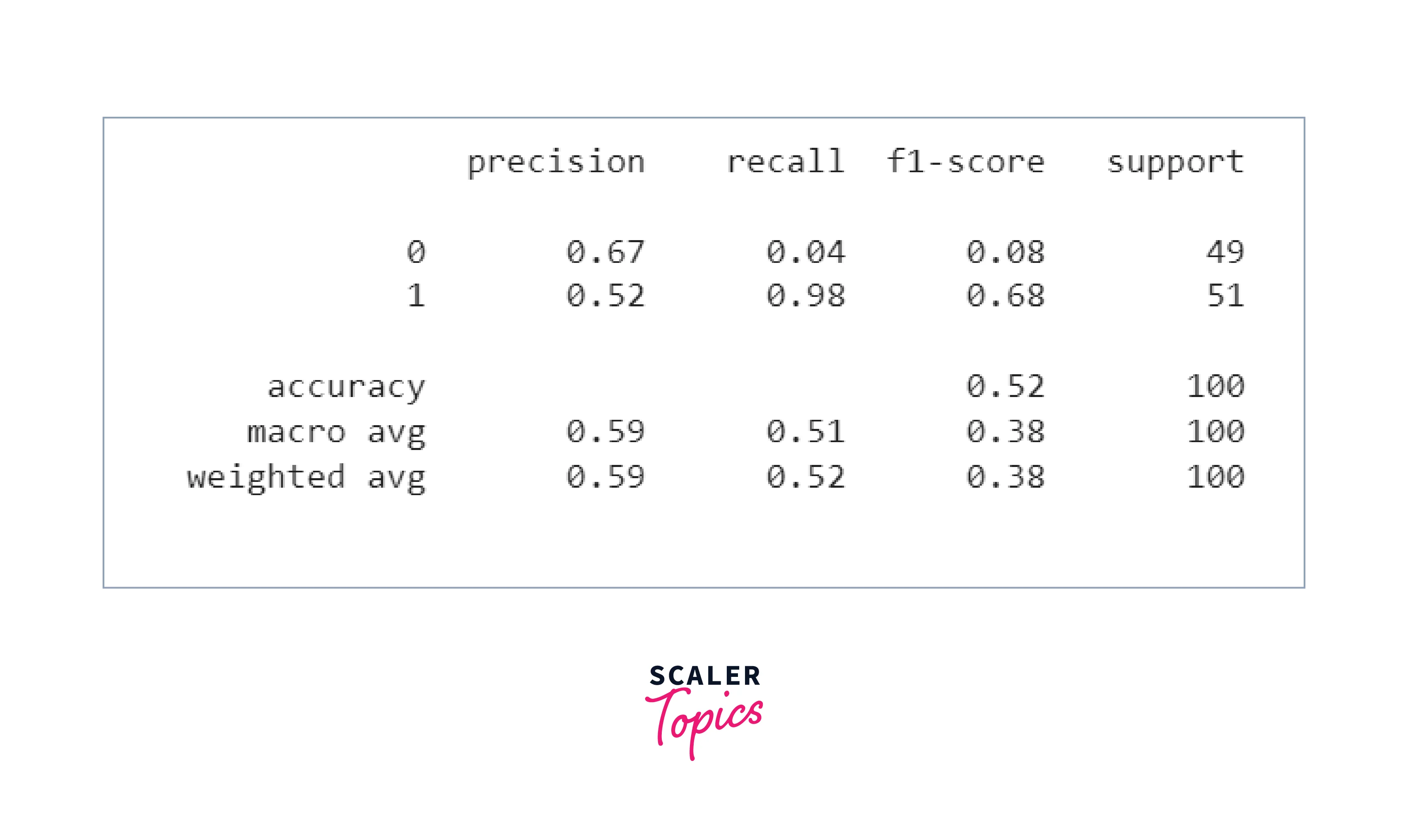
4. Making Predictions and Evaluation Similarly, for each input in the validation set, the model's logits are calculated using the same mechanism as the training loss calculation.
For each set of logits, the code calculates the predicted class label using the softmax function and argmax operation. These predicted labels (y_pred) and true labels (y_true) are then used to compute the classification report.
Output
Language Modeling Objectives
In the pre-training phase of Transformer-XL, the model is trained to predict the next token in a sequence given the context of previous tokens. The training objective is to maximize the likelihood of predicting the correct next token.This language modeling objective encourages the model to learn meaningful representations of words and understand the statistical properties of the language. By predicting the next word based on context, the model learns to capture syntactic and semantic relationships between words.
Transfer Learning with Transformer-XL
Transfer learning is a key benefit of pre-training large language models like Transformer-XL. Once a model is pre-trained on a vast corpus of text, it acquires a general understanding of language and can be fine-tuned for specific tasks with limited labeled data.
Transfer learning with Transformer-XL offers several advantages:
-
Efficient Training: Pre-training a large model on a large corpus can be computationally expensive. However, once pre-trained, the model can be fine-tuned for specific tasks with relatively little labeled data, making the overall training process more efficient.
-
Domain Adaptation: Pre-training on a diverse dataset enables the model to learn a generalized representation of language. Fine-tuning on task-specific data allows the model to adapt to the nuances and specificities of the target domain.
-
Few-Shot Learning: Transformer-XL's pre-trained representations can be leveraged for few-shot learning scenarios. Few-shot learning refers to scenarios where the model performs well even with very limited labeled data for the target task.
-
Multitask Learning: By fine-tuning a pre-trained Transformer-XL model on multiple tasks, the model can learn to generalize across different NLP tasks, leading to improved performance on each task.
Transfer learning has become a standard practice in NLP, and large pre-trained models like Transformer-XL have played a crucial role in advancing the state of the art in various NLP tasks.
Applications of Transformer-XL
Transformer-XL's ability to handle long-range dependencies and its efficient memory computation make it a powerful language model for a wide range of NLP applications. Some of the key applications of Transformer-XL include:
-
Language Generation and Text Completion
Language generation tasks involve generating coherent and contextually relevant text based on a given prompt or seed. Transformer-XL's ability to capture long-range dependencies allows it to produce more coherent and contextually consistent output in language generation tasks.Text completion, also known as text auto-completion or predictive typing, involves predicting the next word or token given the context of the previous words.
-
Document Understanding and Summarization
Document understanding tasks involve processing and analyzing lengthy documents to extract relevant information or answer specific questions. Transformer-XL's ability to handle very long sequences makes it suitable for document understanding applications, where capturing dependencies across long texts is essential. Document summarization tasks involve generating concise summaries of lengthy documents. Transformer-XL's memory computation and long-range dependency handling enable it to generate more informative and coherent summaries.
-
Machine Translation and Dialogue Systems
Machine translation involves translating text from one language to another. Transformer-XL's adaptive segmentation and context window extension make it effective in handling longer sentences in machine translation tasks. Dialogue systems, such as chatbots, involve generating responses in natural language based on user queries or prompts.
-
Contextual Question Answering: For question answering tasks that require a deep understanding of the context, Transformer-XL can excel. It can provide more accurate answers by considering a wider span of the text, which is crucial for comprehending complex questions.
-
Sentiment Analysis and Opinion Mining: Transformer-XL's extended context handling can contribute to more accurate sentiment analysis and opinion mining. It can capture nuances in longer texts and identify the sentiment of the entire content more effectively.
-
Document Classification: In tasks where categorizing longer documents is essential, Transformer-XL can help the model better grasp the overall theme and content of the text, leading to improved classification accuracy.
Performance and Limitations of Transformer-XL
-
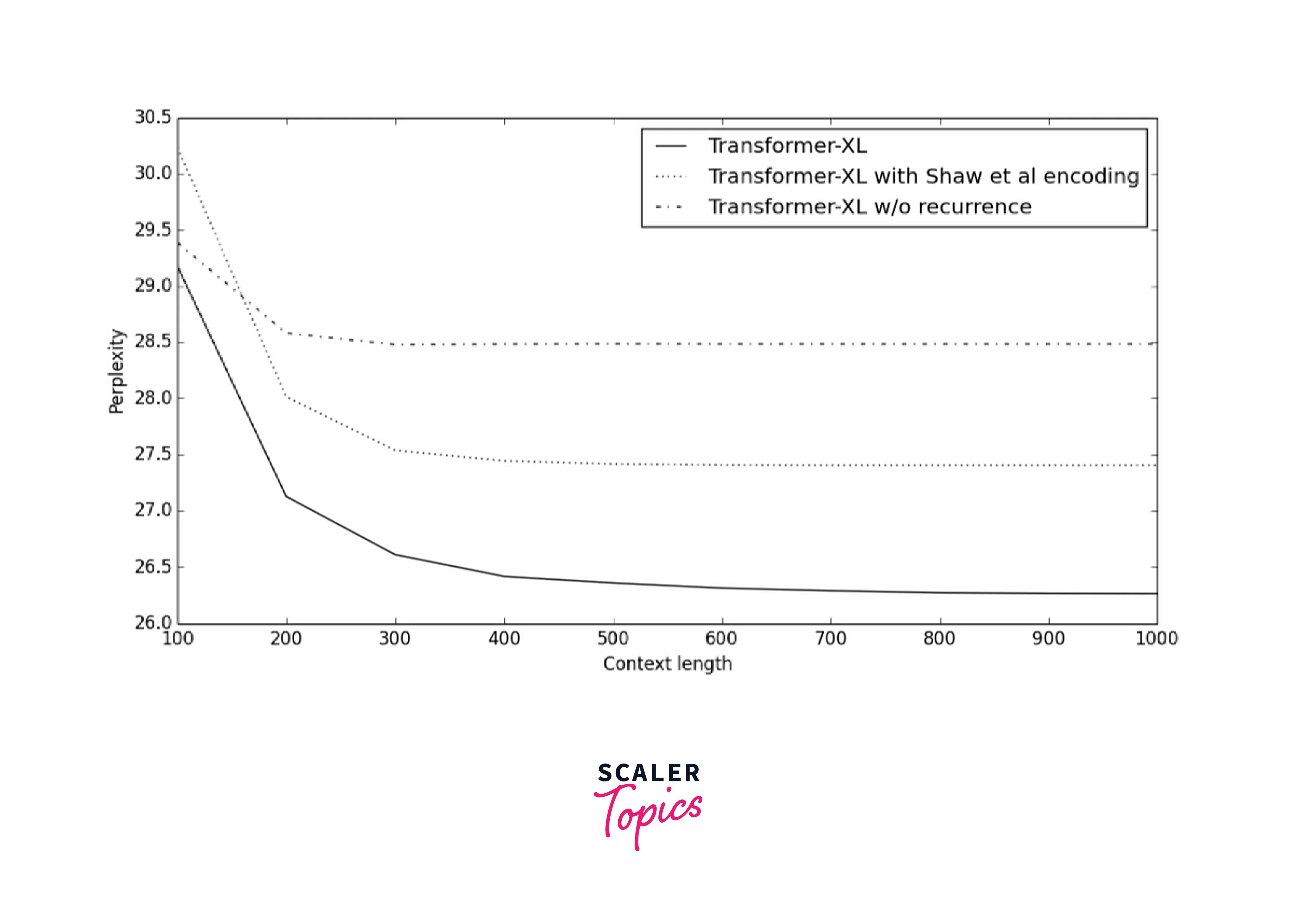
Computational Efficiency Considerations
While Transformer-XL offers significant advantages in handling long-range dependencies and very long sequences, it is important to consider computational efficiency. The memory computation and adaptive segmentation mechanisms introduce additional computational overhead compared to traditional Transformer models.
-
Handling Very Long Sequences
Transformer-XL's ability to handle long-range dependencies and lengthy sequences comes with a trade-off in terms of memory efficiency. While it is more scalable than traditional Transformer models, processing very long sequences can still be computationally expensive. For applications involving extremely long texts, it may be necessary to consider strategies such as dividing the text into smaller segments and processing them individually to manage memory consumption.
Conclusion
- Transformer-XL is an advanced language model that extends the Transformer architecture to address fixed-length context limitations in traditional models.
- It introduces memory computation and segment-level recurrence, enabling the model to learn from a larger context and capture long-term dependencies effectively.
- Transformer-XL uses relative positional encoding to understand token order and maintain context across distant tokens in the input sequence.
- The model's ability to handle longer contexts and maintain information from previous segments results in more coherent and contextually accurate language modeling.
- Hugging Face's Transformers library offers a convenient interface to implement and utilize Transformer-XL and other state-of-the-art models for various NLP tasks.