What is Apache Spark?
Overview
In today's data-driven world, large-scale data processing provides multiple insights or business intelligence, but as the scale of data increases, it becomes difficult to process large amounts due to the need for a large number of resources. Apache Spark is an open-source distributed data processing and computing system that has become the backbone of many big data processing solutions today. Its unparalleled scalability, support for multiple APIs, and lightning-fast analytic queries make it a game-changer in the world of big data. With Spark, businesses can process data up to 100 times faster than traditional Hadoop MapReduce, leading to faster insights and better decision-making.
Introduction
Apache Spark is distributed computing system designed for large-scale data processing. With the help of its data analytics engine, it can process both batch and real-time streaming data, as well as machine learning and graph processing workloads. It was created to solve the limitations of the Hadoop MapReduce framework, which had become the industry standard for distributed data processing. Apache Spark provides other major features like fault-tolerant architecture and parallel processing of data across a cluster of machines. Spark is one of the most used tools by data scientists, developers, and engineers who need to process large amounts of data efficiently.
Note : The limitations of Apache MapReduce are its batch-based processing approach, which made it unsuitable for real-time data processing, and disk-based processing, which was slower compared to processing data in memory.
What is Apache Spark?
We can explore the different components of apache spark which have made Spark an indispensable tool for big data analytics in organizations across the globe.
RDD
Resilient Distributed Datasets (RDD) are immutable, fault-tolerant data structures that are being used to divide the data into multiple partitions and process each partition across clusters of machines in parallel. This feature allows apache spark to process large-scale datasets in a distributed computing environment. RDDs allow users to perform complex data transformations and actions on large datasets. The RDDs can be automatically recovered in case of node failure and this feature enables Spark to handle big data workloads effectively.

DAG
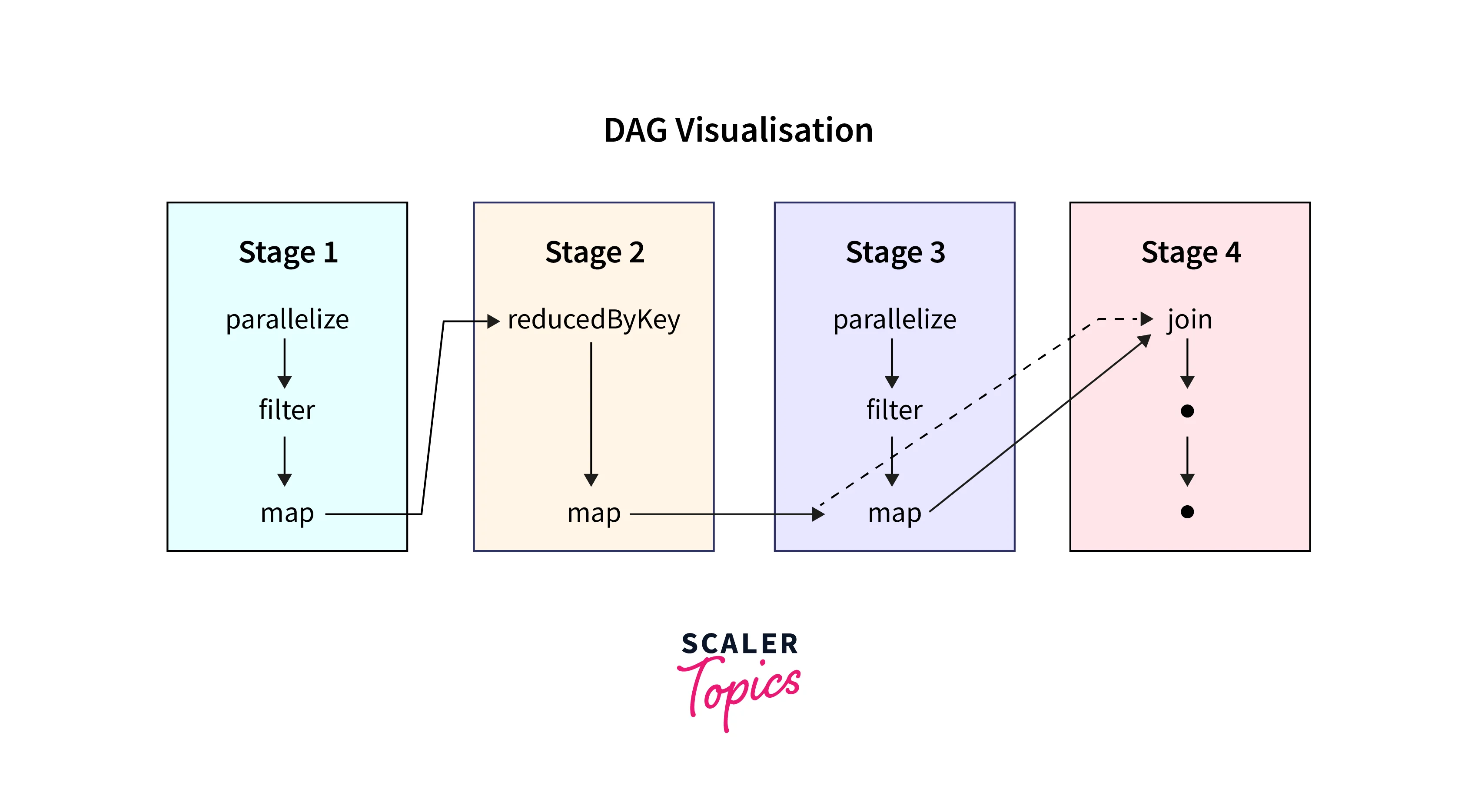
Directed Acyclic Graph(DAG), is a powerful tool in Apache Spark which is used to break down computing jobs into smaller, more manageable pieces. A DAG is similar to a graph data structure in which each node represents an operation or a stage, and the edges between the nodes represent the dependencies between those stages. By understanding the dependencies between different stages, Spark can optimize the scheduling of tasks and avoid unnecessary computation, leading to faster and more efficient data processing. DAG keeps a record of failed tasks and helps to recover from failures by re-executing only the failed tasks.
Client vs Cluster Mode
There are two modes for running a spark application.
| Client Mode | Cluster Mode |
|---|---|
| The driver program runs on the client machine. | The driver program runs on a node in the cluster |
| Suitable for development and testing on a small scale. | Suitable for running Spark applications on large-scale production clusters. |
| The client machine is responsible for managing resources such as memory, CPU, and network bandwidth. | The cluster manager is responsible for managing resources such as memory, CPU, and network bandwidth across all nodes in the cluster. |
| Typically used in secure environments as the client machine is not directly exposed to the cluster's security vulnerabilities. | Requires additional security measures to protect the driver program and cluster manager from potential security threats. |
| Limited scalability as the client machine can become a bottleneck when running Spark applications on a large scale. | Highly scalable as the cluster manager can distribute tasks across multiple nodes in the cluster to improve the performance and efficiency of Spark jobs. |
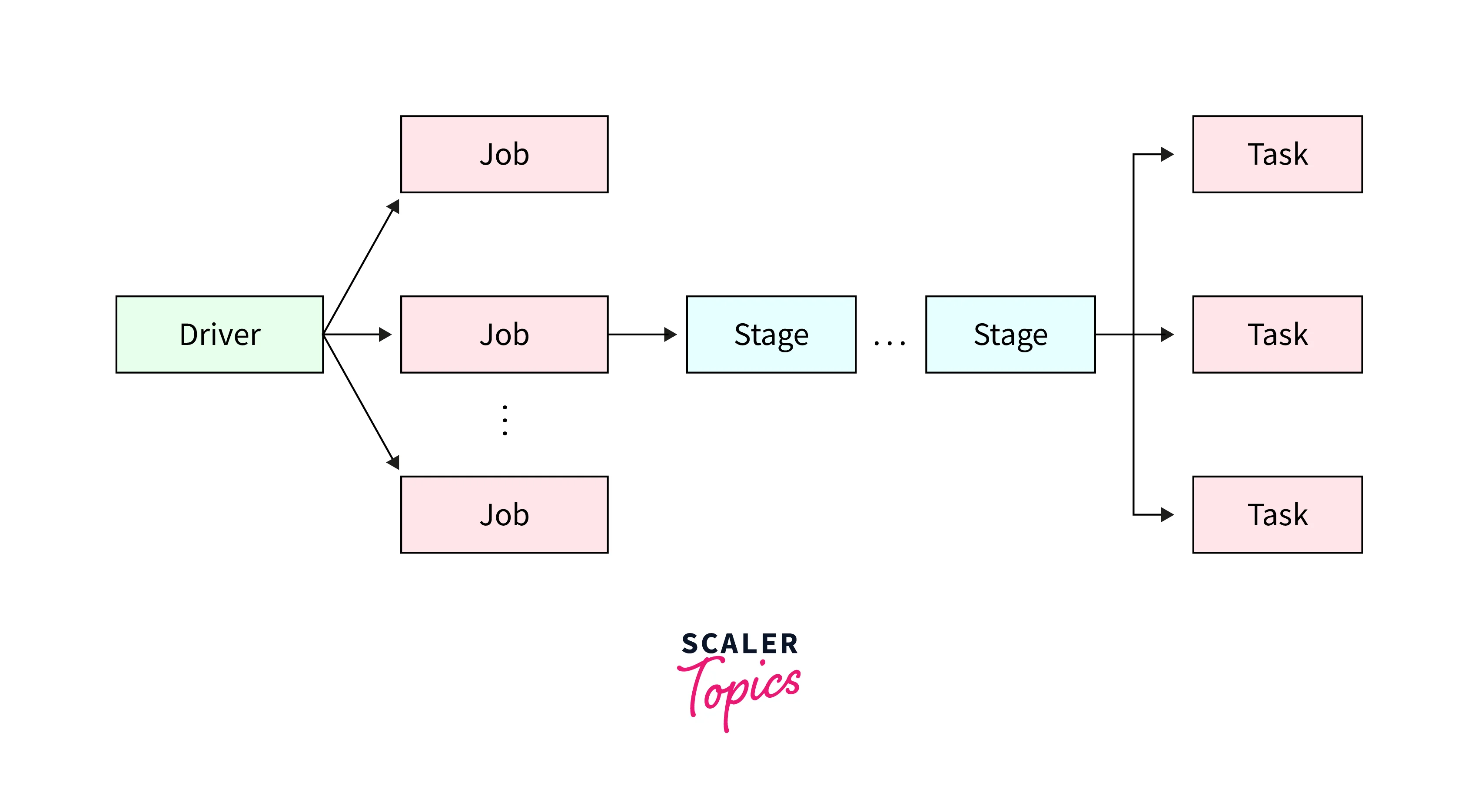
Stages and Tasks
In Apache Spark, a job is divided into a sequence of stages. Each stage represents a set of tasks that can be executed in parallel. Stages are created based on the dependencies between the RDD in the job. There are two types of stages in Spark,
- A shuffle stage occurs when data needs to be shuffled between the worker nodes to complete a task. Shuffle stages are typically created by operations like groupByKey, reduceByKey, and join.
- A result stage occurs when the final results of a Spark job are computed and returned to the driver program. Result stages are typically created by actions like collect, take, and save.
A task is the smallest unit of work in Spark. Tasks are executed in parallel across multiple worker nodes in the cluster. Tasks are created based on the partitions of the RDDs in the stage. The Spark Executor schedules and executes the task and is also responsible for resources required by the jobs.
Note: Dependencies in RDD are the relationship between different RDDs. The dependencies are classified based on whether the partition of a parent RDD is being used by single or multiple partitions of a child into narrow or wide and these dependencies are used to create DAG.
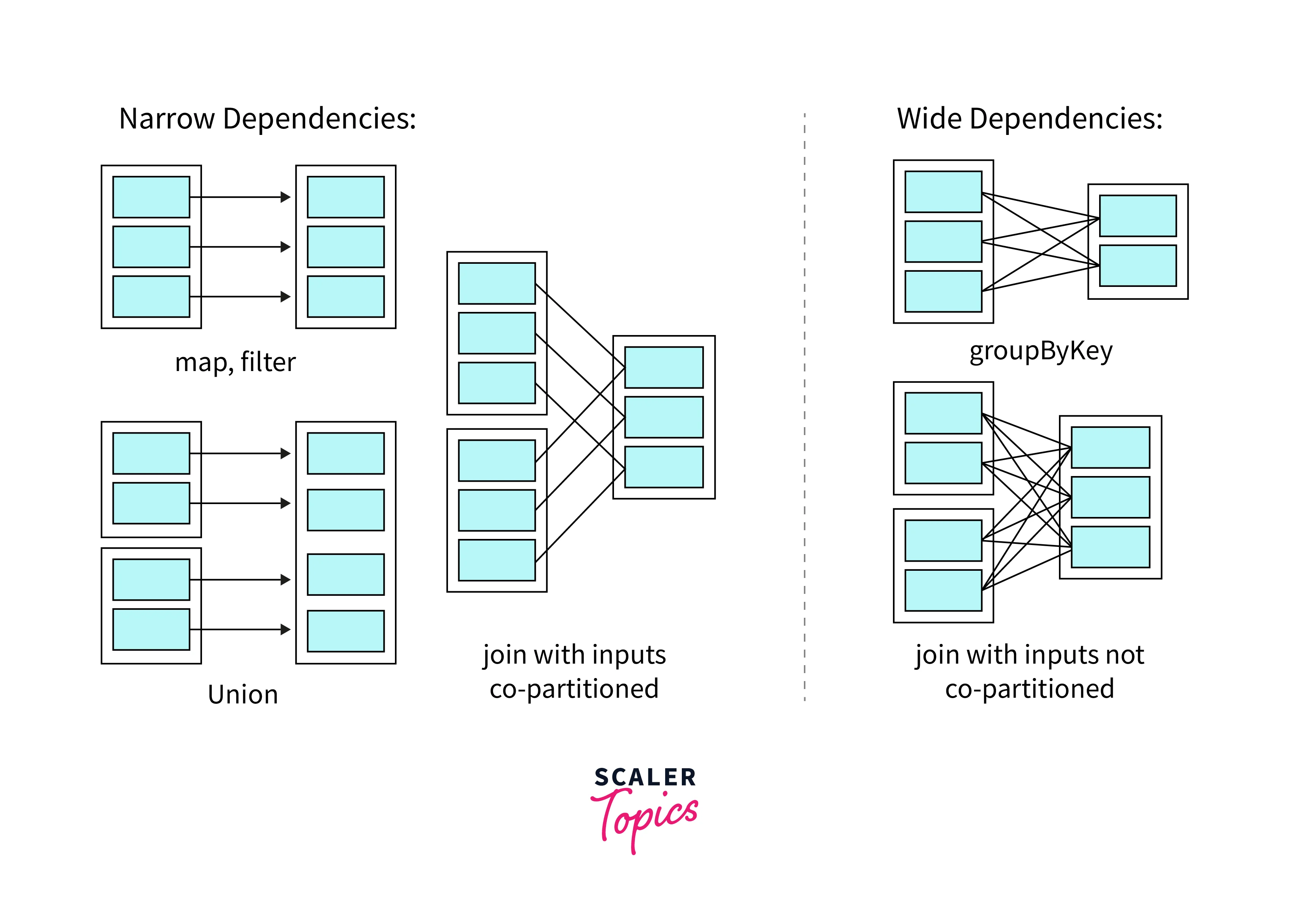
Narrow Vs Wide Transformation
Transformations are operations that transform one RDD into another RDD. Transformations can be classified into two types,
- A narrow transformation is an operation in which each partition of the parent RDD is used by at most one partition of the child RDD. This means that the transformation can be performed locally on each partition without any data shuffling. Examples of narrow transformations include operations like map, filter, and union.
- A wide transformation is an operation in which each partition of the parent RDD may be used by multiple partitions of the child RDD. This means that the transformation requires data shuffling across the network. Examples of wide transformations include groupByKey, reduceByKey, and join.
Narrow transformations are faster and more efficient than wide transformations as there is no need for data shuffling. By understanding the difference between narrow and wide transformations, Spark developers can write more efficient and scalable Spark applications.
Actions
Actions in Apache Spark are operations that trigger the execution of a series of transformations to produce an output or result. Actions trigger the computation and materialization of data in the RDD (Resilient Distributed Dataset) or data frame. A few examples are,
- The collect() actions, which return all the elements of an RDD or DataFrame to the driver program.
- The count(), which returns the total number of elements in the RDD or DataFrame.
- The foreach() can be used to apply a function to each element in the RDD or DataFrame.
The following Python code illustrates the creation of a Spark context, RDD, and triggering an action.
The SparkContext is used for initializing and configuring the Spark runtime environment. It also provides an interface for creating RDD. The parallelize function is used to create a collection with data distributed across nodes and the collect method retrieves all the data.
Evolution of Apache Spark
Apache Spark was first introduced in 2009 as a research project at UC Berkeley's AMPLab, and since then, it has rapidly evolved to become one of the most popular big data processing frameworks in the industry. Spark achieved a faster and more efficient way to process data by introducing a new data processing model called Resilient Distributed Datasets (RDDs), which allowed data to be stored in memory and processed in parallel across different machines. More recently, Spark has been enhanced to support even more use cases, including deep learning and data science workloads. With the introduction of Spark's built-in support for TensorFlow and other deep learning frameworks, Spark has become a popular platform for training and deploying large-scale deep learning models.
Spark Dataframe
Dataframes are important aspects of data processing and are used to represent data in most cases. Spark DataFrames were introduced in Apache Spark 1.3, in February 2015. Spark DataFrames is a distributed collection of data organized into named columns, similar to a table in a relational database. They are a core component of the Apache Spark ecosystem and provide a high-level interface for working with structured and semi-structured data.
We can create a spark data frame using the following Python code,
The SparkSession object is used to interact with the Spark DataFrames. The show() method displays the data frame as a table. The output of the above code will be,
| name | age |
|---|---|
| Alice | 25 |
| Bob | 30 |
| Charlie | 35 |
Three Ways of Spark Deployment
Spark provides us the flexibility to be deployed in various ways depending on the specific requirements of the application and the available infrastructure.
Standalone
In this mode, Spark runs on a cluster of machines managed by a standalone Spark cluster manager. This is a good option for organizations with dedicated resources and a need for better performance and scalability. To deploy Spark in standalone cluster mode, you need to set up a cluster manager, configure the Spark environment, and start the Spark master and worker nodes.
Hadoop Yarn
Hadoop YARN mode of deployment, allows Spark to run on Hadoop clusters. By using YARN, Spark can leverage the resources of a Hadoop cluster for data processing and analytics. The following steps are used to deploy spark on yarn,
- Install and configure Hadoop on all the machines that will be part of the cluster.
- Spark should be installed and configured to use YARN as the cluster manager.
- The spark-submit script can be used to submit job applications to the YARN cluster. The working of the yarn manager will depend on the configuration of the spark-defaults.conf file.
Spark in MapReduce (SIMR)
Spark in MapReduce (SIMR) is a deployment mode that allows Spark to run on an existing Hadoop cluster within the MapReduce framework, without the need to set up a separate Spark cluster. The following steps have to be followed to deploy spark in MapReduce,
- Install Spark on all the machines that will be part of the Hadoop cluster.
- Configure Hadoop to use SIMR as the cluster manager by changing the mapred-site.xml and core-site.xm files.
- Start the SIMR service using the simr-launch script and the spark-submit script can be used to submit jobs to spark.
Key features
Batch/Streaming Data
Spark is a distributed computing framework that provides parallel execution features and also provides support for distributed processing, which is scalable for large datasets. Spark provides support for the real-time processing of data through its streaming API. This allows developers to process and analyze data as it is generated, rather than waiting for it to be stored in a batch processing system.
SQL Analytics
Spark provides support for SQL analytics through Spark SQL and DataFrames. Spark SQL allows users to query structured and semi-structured data using SQL syntax. Spark SQL provides high performance and integrates seamlessly with other Spark modules.
Data Science at Scale
Spark enables large-scale data science with tools like Spark SQL for SQL-based analysis, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for real-time analysis. Spark provides with DataFrames, a high-level API for manipulating tabular data which is also type-safe and optimized for performance. Together, Spark SQL and DataFrames provide a powerful way to analyze large-scale data.
Machine Learning
Spark provides support for machine learning through its MLlib library. MLlib provides tools for common machine learning tasks such as classification, regression, and clustering.
Spark SQL
Spark SQL is a module in Apache Spark that provides support for querying structured and semi-structured data using SQL syntax. Spark SQL can be used to execute SQL queries, read data from a variety of data sources, and write data to those data sources.
Let us consider the table in the Spark Dataframe section as data present in data.csv and illustrate an example of how to use Spark SQL with Python,
The createOrReplaceTempView method will create an in-memory table that's only available for the duration of the SparkSession. The output will be a single row with a single column containing the count of rows where the age is greater than 30. In our example, only Charlie has an age(35) greater than 30. Therefore the output will be 1.
| count(1) |
|---|
| 1 |
Spark MLlib and MLflow
Spark MLlib is a machine learning library in Spark that provides a high-level API for building scalable and distributed machine learning models. The main features of this library are,
- Built-in support for model persistence, which allows trained models to be saved to disk and reloaded later for prediction or further training.
- Tools for hyperparameter tuning and feature engineering.
- Spark MLlib integrates seamlessly with the rest of the Apache Spark ecosystem.
MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides tools for tracking experiments, packaging code into reproducible runs, and sharing and deploying models. The main features of this library are,
- A central repository for storing and managing machine learning models.
- Tools for collaboration, and managing models, including model versioning, packaging, and deployment. Spark also provides seamless integration with MLlib and Spark Streaming.
Structured Streaming
Structured Streaming is a high-level API for building scalable and fault-tolerant streaming applications on Apache Spark. It allows developers to write streaming applications by treating streams of data as tables or data frames. The features of structured streaming are,
- Allows developers to use SQL-like operations to query the streaming data.
- End-to-end fault tolerance through RDDs.
- Scale to handle large volumes of streaming data.
- Provides support for multiple streaming data sources like HDFS, S3, and JDBC. Structured Streaming also has built-in integration with Apache Kafka for building streaming applications with data from Kafka.
Delta Lake
Delta Lake is an open-source storage layer that brings the properties of Atomicity, consistency, isolation, and durability(ACID) to Apache Spark and big data workloads. It is built on top of Spark and is designed to handle big data workloads at scale. The features of delta lake are,
- Provides schema during the writing of data, which enforces that data is always in the correct format.
- Allows users to version data and track changes.
- Delta Lake also supports both batch and streaming workloads which can be used to build real-time data pipelines.
- Designed to optimize query performance, making it easy to query large datasets quickly and efficiently.
Pandas API on Spark
Pandas API on Spark connects the powerful data manipulation capabilities of Pandas to large-scale data processing in Spark. The major features of pandas API on spark are,
- Fast execution for data manipulation tasks, as it uses Spark's distributed computing capabilities.
- Provides data serialization between Pandas and Spark, making it easy to move data between the two libraries.
- Compatible with various Spark components, including Spark SQL, Spark Streaming, and MLlib.
Here is a simple example to manipulate a dataset using the pandas API,
A Pandas UDF (User-Defined Function) is a way to apply a Python function that takes and returns a Pandas DataFrame to a Spark DataFrame. The @pandas_udf along with the schema as a parameter marks a pandas UDF function. The apply method is used to apply the pandas transformations to the dataset. The output will be,
| id | name | age |
|---|---|---|
| 1 | ALICE | 50 |
| 2 | BOB | 60 |
| 3 | CHARLIE | 70 |
Running Apache Spark
Apache Spark can be run in several modes as described in the above sections. In addition to the above modes, there is also Mesos Mode in which spark runs on a cluster managed by the Mesos cluster manager. This mode provides advanced features such as dynamic allocation and fine-grained resource allocation. We can also run apache spark on a Kubernetes cluster using the Kubernetes scheduler. This mode provides a way to run Spark on a cloud-based infrastructure and provides advanced features such as dynamic allocation and container isolation.
To run Apache Spark in any mode, we need to install Spark on the machine, set up a configuration file specifying the mode, and write your Spark application code using one of the supported APIs (RDD or DataFrame APIs). Then, we can submit jobs to Spark using the spark-submit command-line tool, which takes care of launching the application and managing the cluster resources.
Databricks Lakehouse Platform
Databricks Lakehouse Platform is a unified analytics platform that combines the power of data lakes and data warehouses in a single platform. It is built on top of Apache Spark and provides a simplified approach to data engineering, data science, and business analytics. The platform enables organizations to leverage the benefits of both data lakes and data warehouses without the need for separate systems. The major components are,
- Delta Lakes for providing ACID transactions and managing the data lake in a more efficient and scalable way.
- Databricks Workspace to provide a collaborative environment for data engineering, data science, and business analytics.
The Databricks Lakehouse platform is available on major cloud providers such as AWS, Microsoft Azure, and Google Cloud Platform.
Conclusion
- Apache Spark is an open-source, distributed computing system that can process large amounts of data in parallel across many nodes.
- The key features of apache spark are Batch and streaming data processing, SQL analytics, and Data and machine learning science at scale.
- Multiple libraries like Spark SQL, Spark MLlib, and MLflow provide features like querying and building scalable and distributed machine learning models.
- Pandas API on Spark provides data manipulation capabilities of Pandas in Spark.
- Structured Streaming API can be used with Spark to build fault-tolerant streaming applications.
- We can run Spark in multiple modes based on the resources and needs of the user.
- Databricks Lakehouse Platform provides an integrated solution for data engineering, data science, and business analytics on top of Spark.