What is Data Ingestion in Big Data?
Overview
Data ingestion is a critical process in Big Data that involves collecting, processing, and integrating huge volumes of data from diverse sources. The procedure entails gathering raw data, structuring it, and storing it in a centralized area for further analysis. Data ingestion, in its most basic form, is the process of putting data from various sources into a single repository. This assists enterprises in making sense of data, gaining important insights, and making informed decisions. Efficient data input is critical for maximizing data analysis and ensuring the success of Big Data projects.
Introduction
Data ingestion is an important step in big data analytics that involves gathering and processing massive amounts of data from numerous sources. It is the core of any successful big data project, transferring data from its source to a storage system for processing and analysis.
The necessity for data ingestion stems from the fact that the amount of data generated nowadays is massive, and traditional data processing techniques are incapable of handling it. Therefore, this data must be effectively collected, processed, and translated into an analysis-ready format to gain useful insights.
Business intelligence and analytics are two of the most common applications for data input. It allows enterprises to collect data from various sources, such as social media, sensors, and log files, and combine it with internal data to create a holistic perspective of their operations. As a result, they can make data-driven decisions and increase their overall efficiency and profitability.
Data Ingestion in Big Data
Collecting, preparing, and importing massive volumes of data from diverse sources into a Big Data system for processing and analysis is called data ingestion in Big Data. In layman's words, it is the first step of the data pipeline, when data is collected from various sources and prepared for processing.
Data ingestion is an important phase in Big Data processing since it is the foundation for the entire data processing pipeline. It enables businesses to derive insights and value from data by converting it into a useful format. The efficiency and quality of data input are critical to the success of a Big Data project.
The necessity for Big Data data ingestion stems from the need to process enormous amounts of data fast and efficiently. Because traditional data processing systems frequently struggle to accommodate the magnitude and complexity of Big Data, data ingestion is a critical step. By ingesting data into a Big Data system, businesses may process and analyze information more quickly, making better decisions and gaining a competitive advantage.
How does Data Ingestion Work?
Data ingestion is often divided into three stages: collection, processing, and storage.
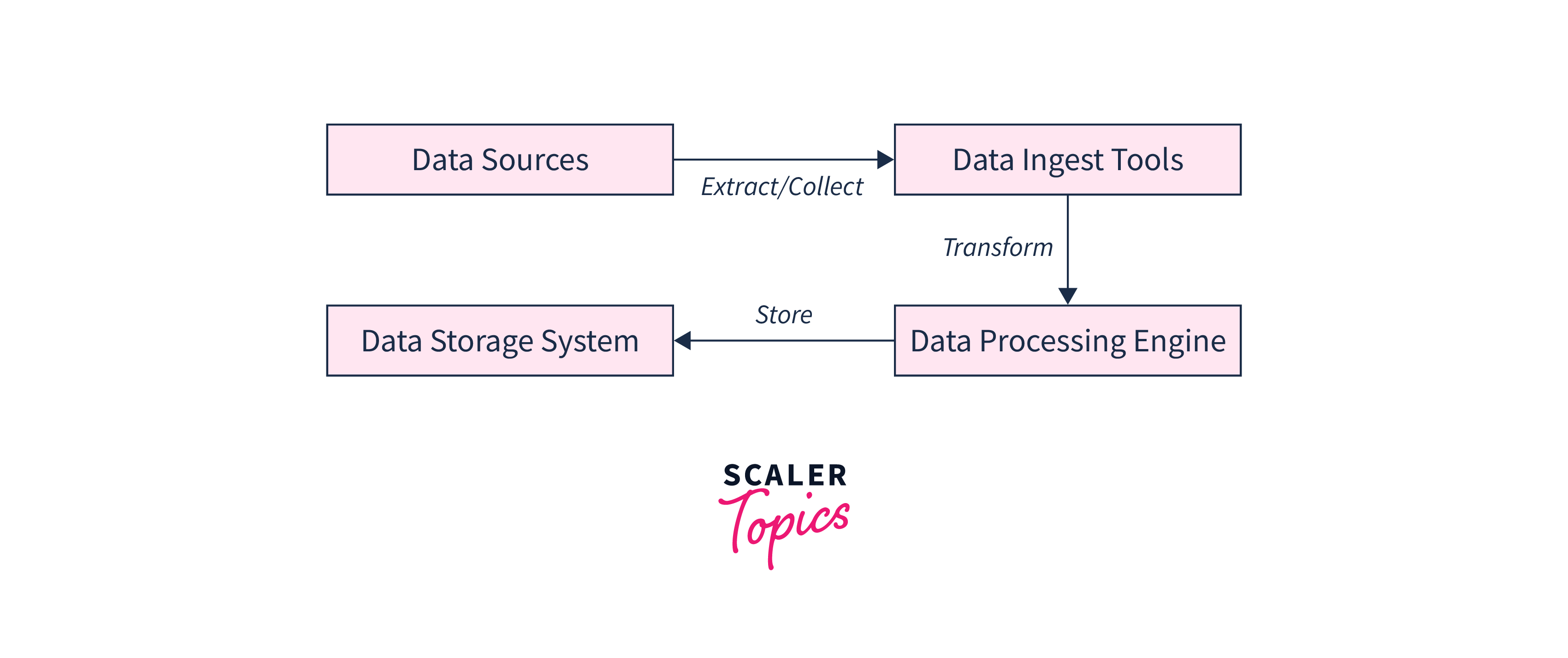
Let's take a closer look at each of these steps.
- Data collection entails acquiring information from many sources, such as databases, websites, and sensors. This information can be in various formats, including organized, semi-structured, and unstructured data. Structured data is well-organized and easily searchable. However, semi-structured and unstructured data might be more complex and require additional processing.
- After the data is acquired, it is processed to convert into a useful format. Cleaning and filtering the data, removing duplicates and extraneous information, and turning it into a uniform format that can be easily studied are required.
- Ultimately, the data is centralized in a data warehouse or data lake. This enables firms to more easily and efficiently access and analyzes data.
Data ingestion can be accomplished through various methods, including batch processing and real-time processing. Batch processing is gathering and processing data in big batches at regular intervals, whereas real-time processing entails collecting and processing data in real time.
APIs(Application Programming Interfaces) are a prominent way of data ingestion . APIs enable different systems to communicate and exchange data with one another. This is especially valuable for businesses that want data from numerous sources.
ETL (Extract, Transform, Load) tools are another technique of data intake. These applications automate data collection, processing, and feeding into a centralized system. This is especially valuable for firms that must process and evaluate enormous amounts of data.
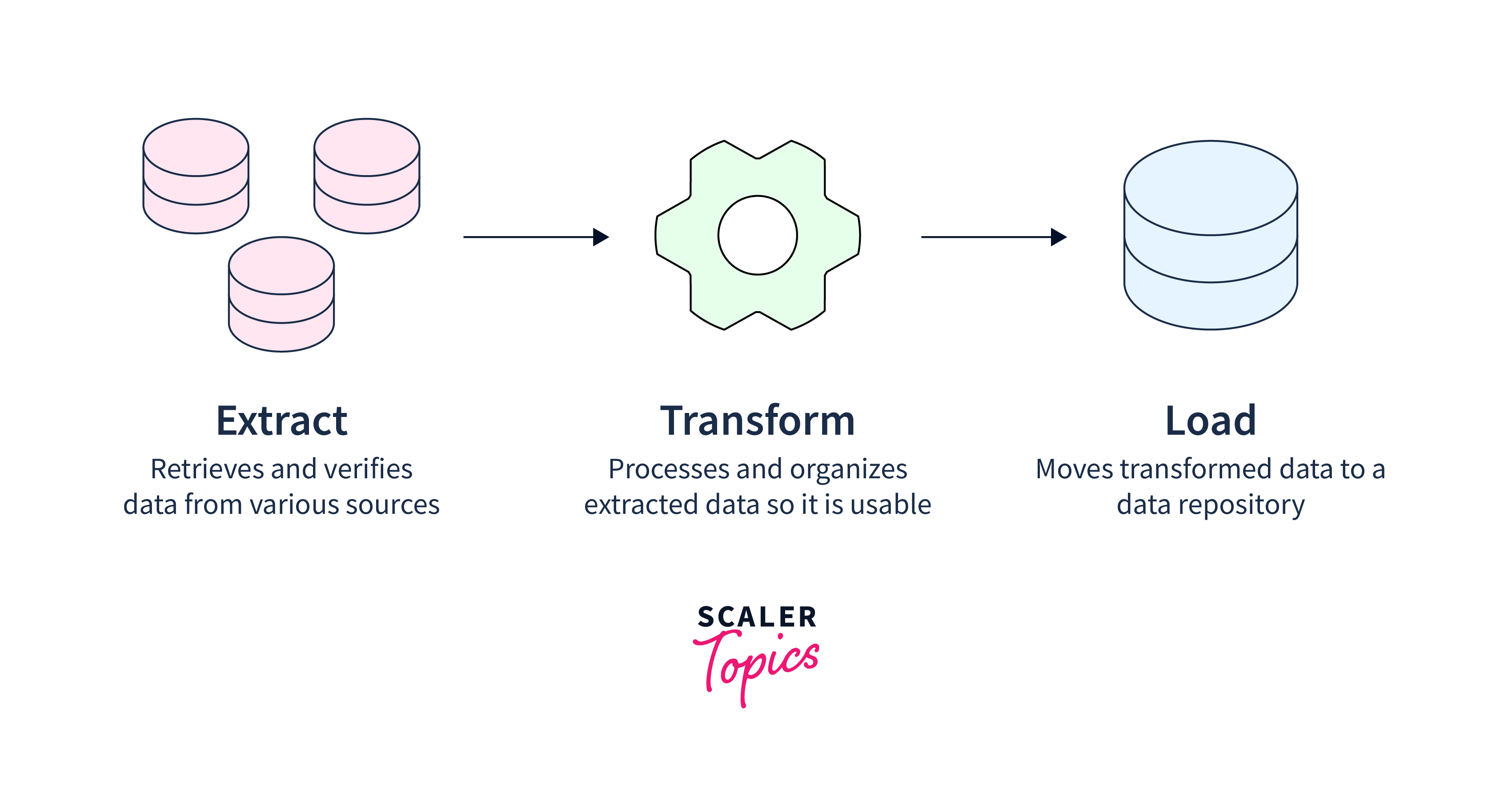
Types of Data Ingestion
Organizations employ various data ingestion strategies to acquire and store their data efficiently. Each method has distinct characteristics and use cases, and selecting the best one depends on the business's individual needs. In this post, we'll look at the most prevalent types of data ingestion and how they might help businesses.
-
Batch Consumption
Batch ingestion is a popular way to collect and handle huge amounts of data in batches. This approach extracts data from the source system, converts it to the desired format, and loads it into the target system in batches. Batch ingestion is appropriate for non-real-time data processing applications such as monthly reports or historical data analysis. The Benefit of Batch ingestion is that it allows organizations to process large volumes of data in a controlled and predictable manner. -
Real-time Ingestion
The practice of gathering and processing data in real-time as it is generated is known as real-time ingestion, also known as streaming ingestion. This technology is appropriate for real-time data processing applications such as fraud detection, stock trading, or online gaming. Organizations can respond fast to changing data, spot abnormalities, and make choices based on the most up-to-date information with real-time ingestion. Real-time ingestion, on the other hand, can be more sophisticated and resource-intensive than batch ingestion. -
CDC (Change Data Capture)
Change Data Capture (CDC) is a data ingestion mechanism that collects and stores changes made to a database rather than the full database. CDC benefits database-intensive applications, such as transactional or event-driven applications, that demand frequent updates. CDC reduces the required amount of data to be processed and improves data quality by capturing only the relevant changes. -
Log-based Ingestion
Log-based ingestion is a technique for gathering and analyzing information from log files created by applications, servers, or devices. This approach is appropriate for log-intensive applications such as web servers, network devices, and security systems. Organizations can use log-based ingestion to monitor and analyze system performance, detect faults or security breaches, and fix issues. -
Cloud-based Ingestion
Cloud-based ingestion refers to the collection and processing of data in a cloud environment such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP). Cloud-based ingestion delivers enterprises scalability, flexibility, and cost-effectiveness by allowing them to store and process data on the cloud without requiring on-premises equipment. Cloud-based ingestion also includes auto-scaling, fault tolerance, and security features.
Data Ingestion vs Data Integration
Data Ingestion and Data Integration are two critical activities that are at the heart of modern data management. While these procedures appear identical, their strategy, objective, and end fundamentally differ. Knowing the distinctions between data intake and integration is crucial for data analysts, engineers, and other data management professionals.
| Data Ingestion | Data Integration |
|---|---|
| Data Ingestion refers to collecting and importing data from different sources into a storage or processing system. | Data Integration, conversely, is the process of combining data from multiple sources into a single, unified view. |
| It collects data from various sources such as social media, customer feedback, IoT devices, etc. | It combines data from different sources, such as databases, data warehouses, and data lakes. |
| This process involves acquiring raw data from various sources, such as social media, customer feedback, IoT devices, and more, and transforming them into a structured format that can be analyzed. | This process involves transforming and merging data from different sources, such as databases, data warehouses, and data lakes, to create a consistent view of the data. |
| It transforms raw data into a structured format that can be analyzed. | It transforms and merges data from different sources to create a consistent view of the data. |
| It uses tools like Apache Kafka, AWS Kinesis, and Google Cloud Pub/Sub. | It uses tools such as Talend, Informatica, and Microsoft SSIS. |
Data Ingestion vs ETL
In modern enterprises, data ingestion and ETL (Extract, Transform, Load) are crucial data management processes. Data ingestion is concerned with gathering and storing raw data, whereas ETL is concerned with converting and aggregating data so that it can be analyzed. Understanding the distinctions between these two processes is critical for organizations seeking to improve their data utilization and get insights to inform decision-making. Businesses may unlock the full potential of their data and achieve a competitive advantage in their particular marketplaces by successfully exploiting these procedures.
| Data Ingestion | ETL |
|---|---|
| Brings raw data into a system or application. | Extracts data from multiple sources. |
| Focuses on collecting and storing data for future use. | Transforms and aggregates data to make it usable. |
| Data is usually stored in its raw form. | Data is transformed into a usable format. |
| Data can be ingested from various sources, including databases, logs, and streaming data. | Data is extracted from structured and unstructured sources. |
| Ingested data is typically not cleaned or processed in any way. | Data is cleaned, deduplicated, and formatted before being loaded into a target system. |
| Extracts data from multiple sources. | Brings raw data into a system or application. |
| Transforms and aggregates data to make it usable. | Focuses on collecting and storing data for future use. |
| Data is transformed into a usable format. | Data is usually stored in its raw form. |
| Data is extracted from structured and unstructured sources. | Data can be ingested from various sources, including databases, logs, and streaming data. |
| Data is cleaned, deduplicated, and formatted before loading into a target system. | Ingested data is typically not cleaned or processed in any way. |
Benefits of Data Ingestion in Big Data
One of the most crucial procedures in Big Data is data ingestion. Data ingestion is the process of gathering and importing data from numerous sources and storing it in a storage system, such as a data warehouse or data lake, where it can be analyzed and processed. In this section, we'll look at the advantages of data intake in Big Data and why it's such an important part of any data-driven company. Some of the benefits of Data Ingestion in Big Data are:
- Data ingestion enables firms to collect and store massive amounts of data from many sources. With the amount of data generated every day rising, it is critical to have a system that can efficiently gather and store it for analysis. Data ingestion systems can collect data from various sources, including sensors, social media platforms, and websites, and store it in a centralized repository for analysis. This means businesses can now access massive amounts of data to acquire insights into customer behavior, market trends, and operational performance.
- Second, data input enables businesses to optimize data processing and analysis. For example, data can be pre-processed using a data intake tool before being saved. Data can be cleansed, processed, and organized before entering the storage system, making analysis easier and faster. Furthermore, data ingestion enables enterprises to select the best storage system for their data, ensuring that it is optimized for processing and analysis.
- Now, data ingestion assists companies in improving data quality. Data ingestion technologies can discover and delete redundant, incomplete, or erroneous data by gathering data from many sources and processing it before storage. This guarantees that the data utilized for analysis is of good quality, improving the conclusions' accuracy.
- Finally, data ingestion allows organizations to automate the data collection process. With data ingestion tools, data can be collected and stored automatically, eliminating the need for manual data collection and reducing the risk of human error. This means that organizations can focus on analyzing the data rather than spending time and resources on data collection.
Challenges of Data Ingestion in Big Data
Data ingestion is collecting, integrating, and processing data from numerous sources and transferring it to a centralized location where it may be analyzed further. In big data, data ingestion is a critical phase that presents several issues. This post will look at major obstacles in big data ingestion and how to solve them.
Some of the challenges of Data Ingestion in Big Data are:
- The sheer volume of data must be swallowed, one of the most critical issues of big data ingestion. Big data often contain huge amounts of data that must be gathered from numerous sources, which can be difficult. This can lead to data accuracy, completeness, and consistency difficulties. To overcome this challenge, enterprises need to invest in powerful data ingestion tools that can handle large volumes of data and ensure data quality.
- Another area for improvement with huge data input is data compatibility. Data might come from various sources and be in various formats and structures, making integration problematic. Data incompatibility can result in inaccuracies, inconsistencies, and quality difficulties. Organizations must employ data integration solutions capable of transforming and mapping data from multiple sources into a consistent format to address this issue.
- Security is another key difficulty of massive data input. Big data generally contain sensitive and confidential information that must be kept secure from unauthorized access. Therefore, organizations must implement strong security measures, such as encryption and access controls, to address this issue to protect data privacy and security.
- Furthermore, another issue with big data input is scalability. As the volume of data grows, organizations must be able to expand their data ingesting procedures to meet the increased demand. To address this issue, businesses must invest in scalable and adaptable data intake systems that can grow and adapt to changing business needs.
Data Ingestion Tools in Big Data
In big data, numerous data ingestion technologies are available that help simplify and automate the data import process. This post will look at some of the most prominent data intake methods used in big data.
- Apache Kafka is a common data intake platform used extensively in big data. It is an open-source distributed streaming technology capable of handling massive amounts of data in real-time. Apache Kafka can process and store many data streams in a distributed system. In addition, it is a data ingestion solution that is dependable, scalable, and fault-tolerant.
![]()
- Apache NiFi is another frequently used data ingestion method in big data. Apache NiFi can analyze data from various sources, including sensors, social media, and Internet of Things (IoT) devices. It is a sophisticated tool capable of handling and processing massive amounts of data in real time.
![]()
- Apache Flume is a distributed data ingestion platform for collecting, aggregating, and moving huge amounts of data from several sources to a centralized repository. It is an open-source program designed to manage large amounts of data efficiently. Apache Flume is a reliable tool that can work with many data sources, including log files, social media, and IoT devices.
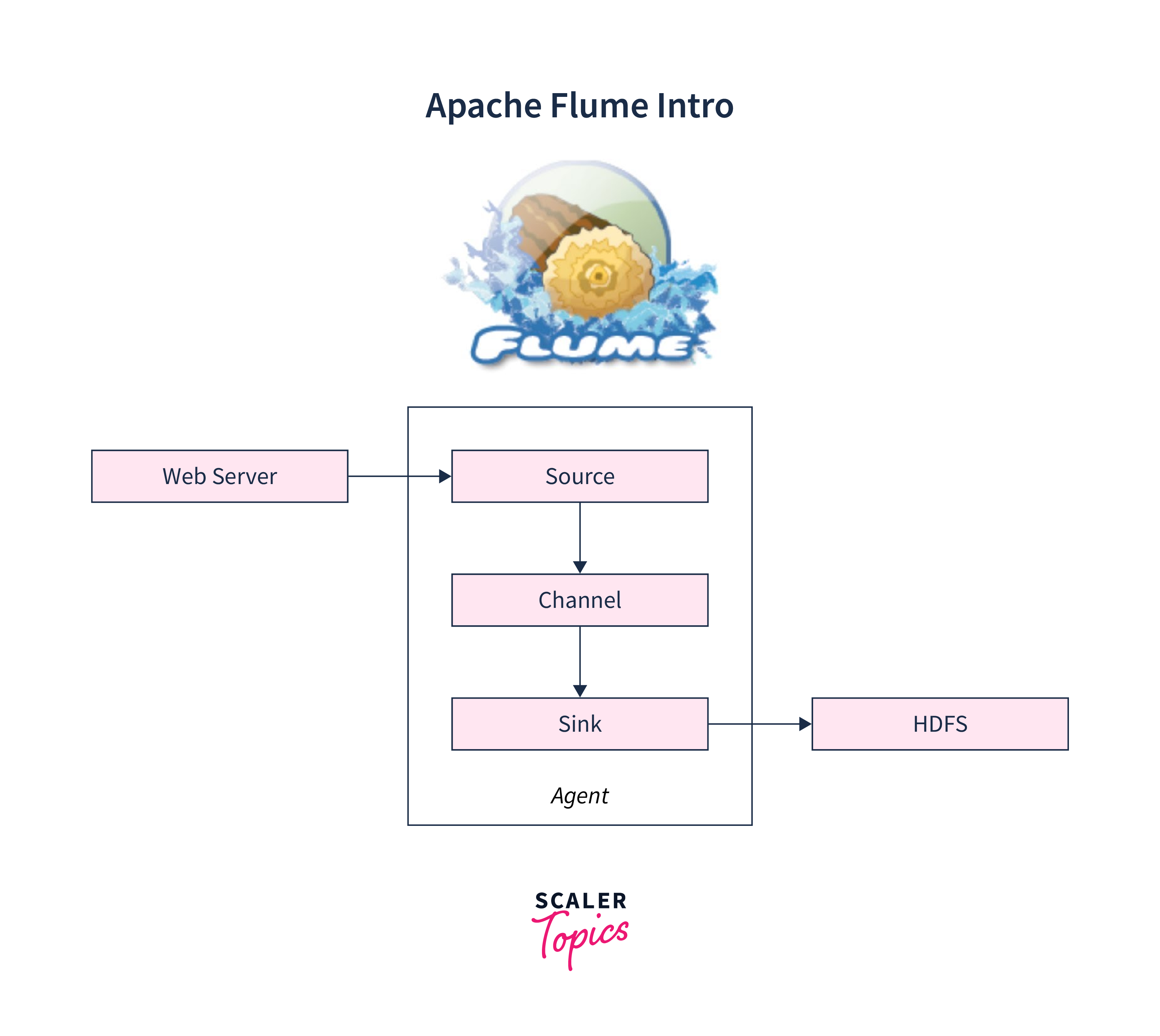
Conclusion
- Data ingestion is collecting and importing data from various sources into a big data system for analysis. Data ingestion is critical in big data since it serves as the foundation of any big data project.
- It is critical to ensure that the ingested data is appropriately prepared and organized to allow for efficient analysis. This includes ensuring that the data is appropriately labelled, classified, and organized in a way that makes sense for the intended application.
- Data ingestion is a critical stage in any big data project, and data ingestion completion is equally significant. It is critical for the success of any big data project to ensure that the ingested data is of good quality and appropriately formatted.
- Having a team of professionals who can carefully review the data and detect any flaws or inconsistencies is critical to ensuring the data is ready for usage in analytics.
- It is also critical to remember that data ingestion is not a one-time event.
- It is a continuous process that necessitates frequent monitoring and management to ensure that the ingested data is accurate, up-to-date, and useful.