What is Parsing in NLP?
Overview
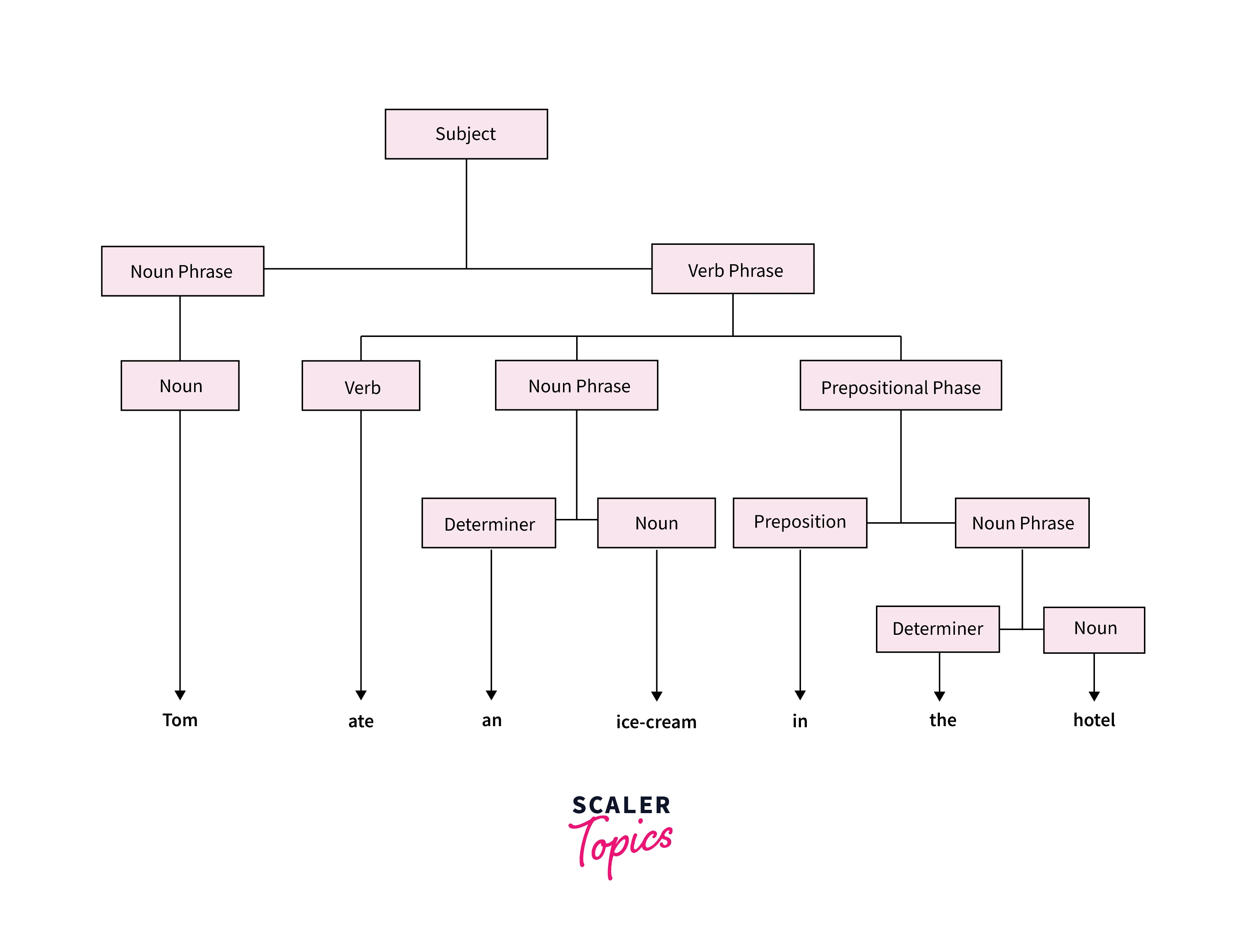
Consider the sentence "I ate a glass of water". A sentence like this should be rejected by our computer while processing a text. Natural Language Processing was designed by humans so that a computer understands the human language. Interpreting and processing a text is not an easy task, as it involves a plethora of rules and guidelines. It is crucial to determine the underlying structure of a given input text. That's what parsing in NLP does.
Parsing in NLP
Text as a bag of words or an array is inconsequential. However, the syntactic structure of the text can be very useful. Parsing helps us to extract the dictionary meaning of words from a text. It is the process by which we determine whether a set of tokens will be accepted by a grammar or not. Parsing performs a syntactic analysis of the text by analyzing the constituent words and deciding its structure with the help of an underlying grammar. In other words, a parser takes in an input string and a set of grammar rules as input and generates the parse tree.
Parsing also helps in the following:
- Detect syntax errors
- Create a parse tree and symbol table
- Generate Intermediate Representations(IR)
A Typical Parsing Process Flow
Apart from syntax, parsing in NLP plays an important role in determining the semantic structure.
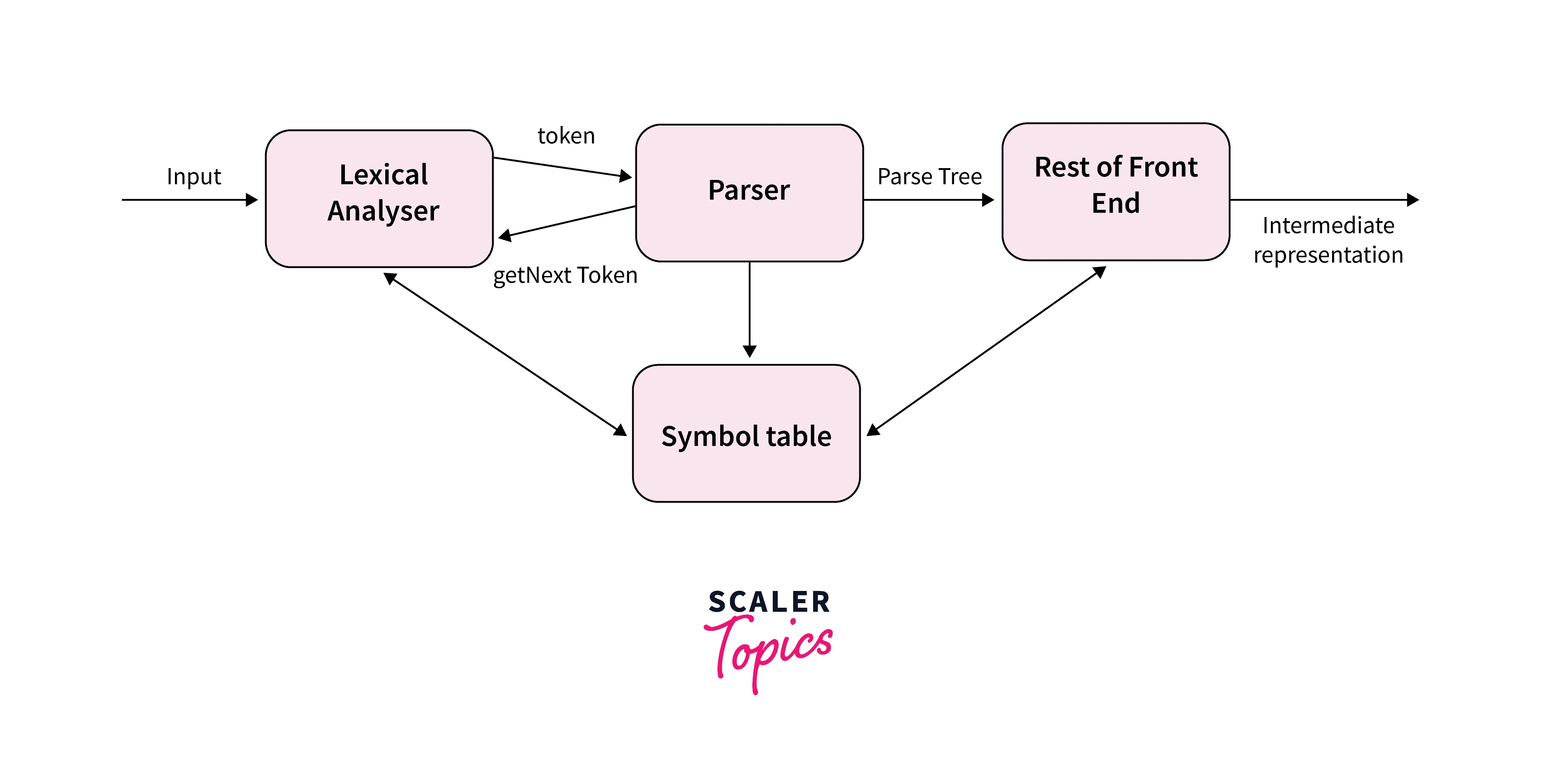
The process of parsing in NLP has the following sequential steps:
- The lexical analyzer converts the input text into individual tokens.
- The tokens are then fed into the parser to get the syntactic structure of the text.
- A Symbol table is being referenced continuously as it stores information about the occurrence of various tokens.
The graphical representation of this structure is the Parse tree:
Parsing Techniques
The different processes of parsing in NLP are classified based on how a parse tree is built.
The frequently used processes are:
- Top-Down parsing
- Bottom-Up parsing
- Predictive parsing
- Left Corner parsing
- Finite State parsing
We already know that the process of parsing in NLP involves describing the structure of an input sentence with the help of a combination of certain grammatical rules.
Top-Down Parsing
Top-down parsing in NLP constructs the parse tree by starting from the root and going down to the leaf. Starting from the first rule, a top-down parser matches the words in the input sequence to the symbols in the grammar in a stepwise manner. Precisely, a top-down parser, while generating the parse tree with root as the start symbol of the grammar, performs a leftmost derivation in each step. We use our CFG rules from left to right.
Example:
Consider the grammar T->T + T|T _ T|T|p and the input string as p + p _ p. Then the rules will be used as:
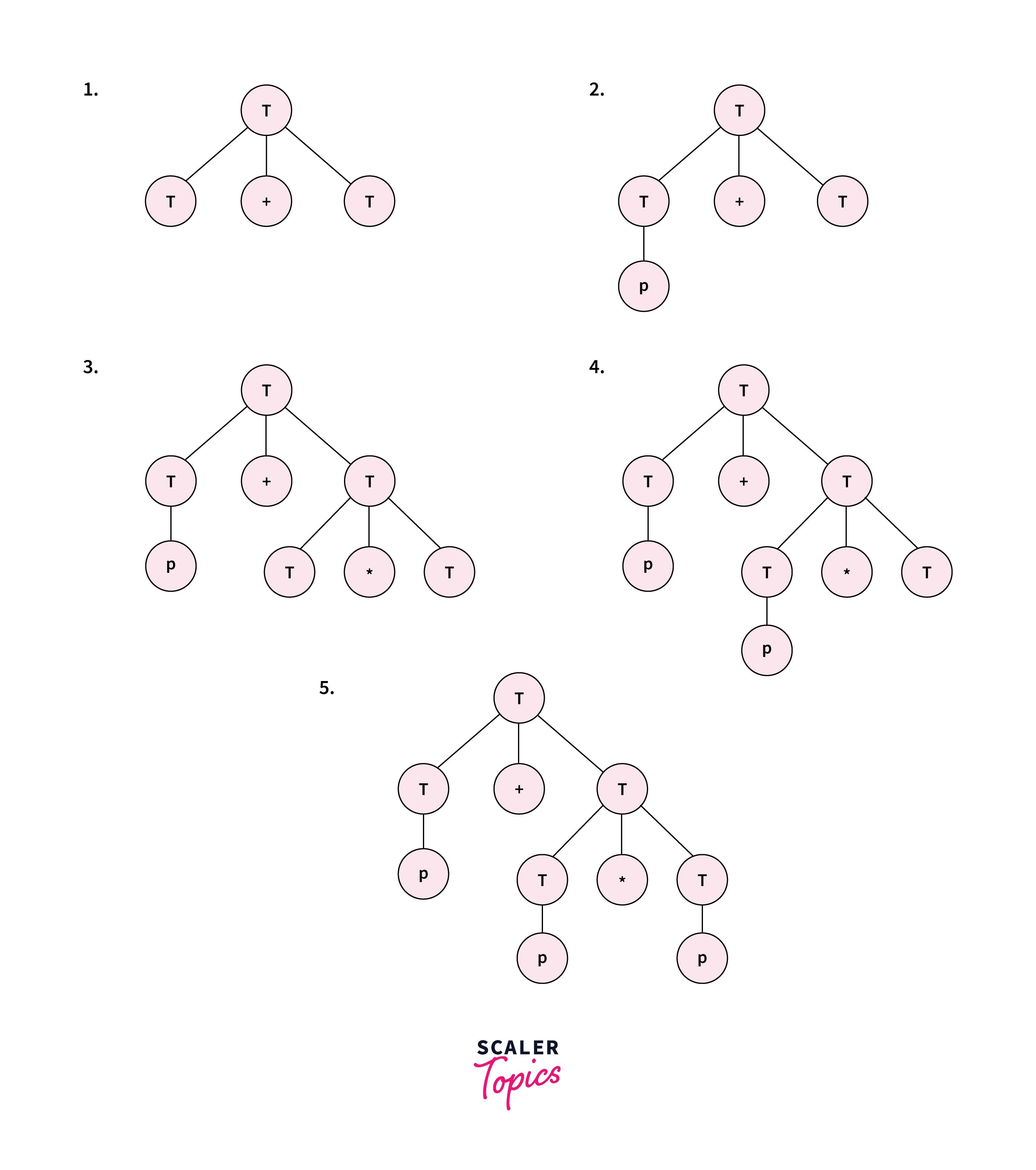
There are two types of top-down parsing in NLP:
- With backtracking:
The parser can scan the input text repeatedly, i.e., if the input string cannot be obtained using one production rule, the parser can use another one to get the required string. - Without backtracking:
Once a production rule is applied, we cannot use another one. There are two types of parsers here: Recursive Descent parser and Predictive Parser.
Bottom-Up Parsing
In bottom-up parsing, we begin with the input string(words to be parsed). Using this information, we build the structure in a stepwise manner. In other words, we start from the leaf nodes of the parse tree and work our way upwards. Hence, we have to reach the start symbol by applying the production rules in reverse order. We use our CFG rules right to the left.
The bottom-up parser is classified into:
- LR parser
- Operator Precedence Parser.

Recursive Descent Parsing
It is a top-down parsing method that may or may not require backtracking. We recursively scan the input to make the parse tree, which is created from the top, while reading the input from left to right.
Predictive Parsing
It is a top-down, recursive descent parsing method that requires no backtracking. A predictive parser parses the input and generates the parse tree using a stack and a parsing table. To avoid backtracking, it uses a look-ahead pointer that points to the next input symbols and uses only the LL(k) grammar.
Left Corner Parsing
Both top-down and bottom-up parsing are stepwise processes and can be dependent on backtracking. There is a good chance that while making decisions, both processes may lose some information provided by the words of the input text, hit a dead end, or go in the wrong direction. This drawback is overcome by Left Corner parsing. Left Corner parsing is a combination of top-down and bottom-up processing, which avoids going in the incorrect direction and making wrong decisions. This process mixes up steps of bottom-up parsing with top-down parsing in an alternating fashion.
Ambiguity in Natural Language Parsing
Ambiguity in natural language parsing is the challenge of interpreting ambiguous structures and meanings in human language. This complexity arises from diverse sentence structures, rich linguistic expressions, and the potential for words or phrases to have multiple interpretations. Resolving ambiguity is crucial in natural language processing (NLP) as it involves accurately understanding context, word semantics, and syntactic structures to discern the intended meaning of a sentence. Ambiguity can take various forms, including lexical, syntactic, and semantic ambiguity, necessitating advanced algorithms and context-aware parsing techniques for enhanced accuracy in natural language understanding.
If more than one parse tree is generated by a grammar, it is said to be ambiguous. The above-mentioned parsing methods can deal with ambiguity by:
- Removing left recursion
- Removing left factoring
However, some parsing methods tackle the problem of ambiguity especially parsing in NLP:
Statistical Parsing:
This method can parse any sentence and is often accurate. This parser computes the most probable parse tree of a sentence with the help of a weighted Context Free Grammar. This parser is used when we have a weak grammar that can generate multiple parse trees.
Dependency Parsing:
This method focuses on the dependencies between the words/phrases in a sentence to generate the grammatical structure. This parser assumes that there is a relationship between every word of a sentence. It links words based on their relationship while generating a parse tree.
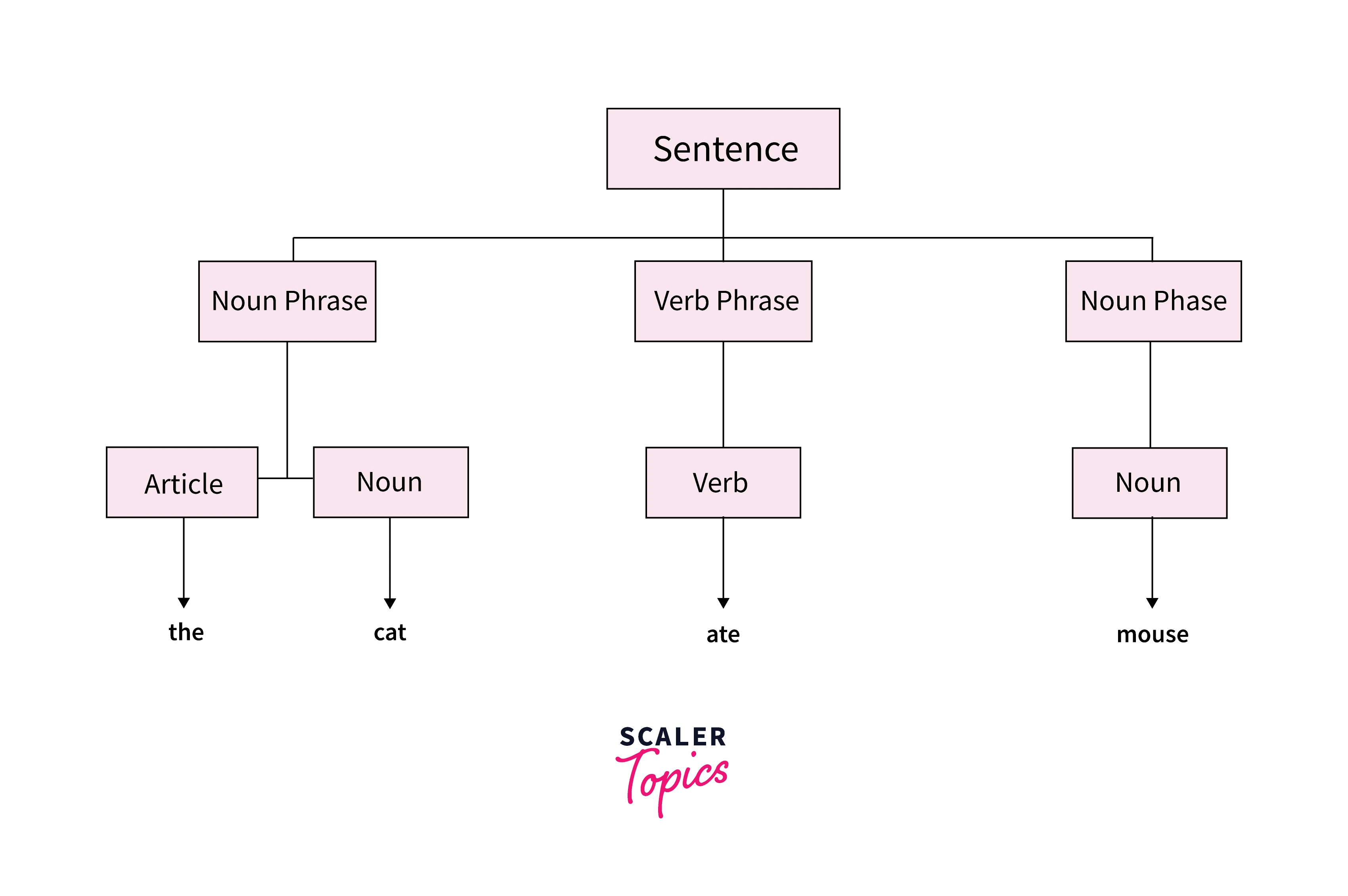
Constituency Parsing:
In this method, we break down our input sentence into several constituents(sub-phrases) that have a specific type in the grammar. Consider the sentence "Rahul sees Rohan" This method would first split the sentence into a Noun Phrase("Rahul") and verb phrase ("sees Rohan") and then split the verb phrase into a verb("sees") and noun("Rohan").
Deep vs. Shallow Parsing
| Deep Parsing | Shallow Parsing |
|---|---|
| This parsing technique generates the complete syntactic structure of the sentence. | This technique generates only parts of the syntactic structure of a sentence. |
| Also termed as full parsing | Also termed as chunking |
| Helps in complex NLP parsing applications. | Used in less complex NLP parsing applications. |
Different Parsers with Examples
Recursive Descent Parser
As we already know recursive descent parsing is a top-down approach and recursively tries to generate the parse tree of a given input string.
Let's see an example:
Consider the grammar:
and the input string: pxq.
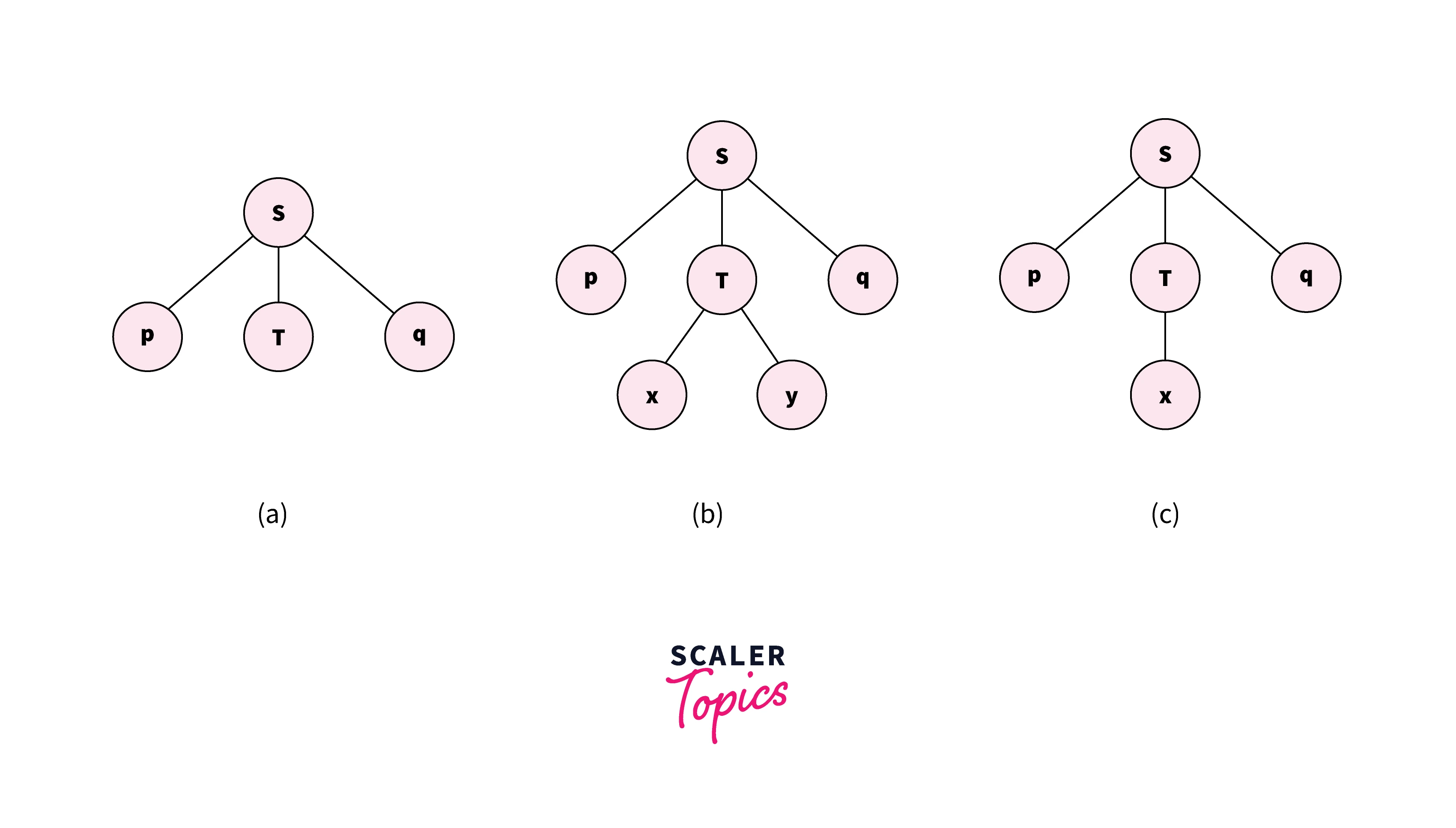
The parser will parse the string in the following steps:
- First, the character 'p' is scanned and according to that the first rule(S->pTq) is used. The first part of this rule S->p satisfies the input character.
- The next character 'x' is then scanned. We move on to the second part of the first rule (S->T), which is a non-terminal and hence the second rule(T->xy|x)'s first part(T->xy) is used. The rule T->x matches here so we scan the next character, 'q'.
- Now, the rule (T->y) does not match with 'q'. This rule(T->xy) is discarded. Now, we backtrack and use the rule(T->x), which satisfies the character 'x', similar to step 2.
- The final character 'q' is then matched with the last rule of the first grammar, i.e. S->q.
Shift Reduce Parser
This is a bottom-up parser that uses an input buffer for storing the input string and a stack for accessing the production rules.
Shift Reduce parser uses the following functions:
- Shift:
Transferring symbols from the input buffer to stack. - Reduce:
Reduction of the correct production rule. - Accept:
the string is accepted by the grammar - Error:
When the parser can perform neither of the above three.
Consider the grammar:
The input string: a+a+a
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| $ | a+a+a$ | Shift |
| $a | +a+a$ | Reduce T->a |
| $T | +a+a$ | Shift |
| $T+ | a+a$ | Shift |
| $T+a | +a$ | Reduce T->a |
| $T+T | +a$ | Reduce T->T+T |
| $T | +a$ | Shift |
| $T+ | a$ | Shift |
| $T+a | $ | Reduce T->a |
| $T+T | $ | Reduce T->T+T |
| $T | $ | Accept |
Chart Parser
Chart parsing is a bottom-up parsing technique used in natural language processing and syntactic analysis. It constructs a chart data structure to keep track of potential parse constituents and their relationships. Let's consider the sentence "The cat chased the mouse" and a simple context-free grammar for English:
With this grammar, a Chart Parser would start with individual words as the initial constituents and gradually build up to larger structures. For example, it would first identify "cat" as a noun phrase (NP) and "chased" as a verb phrase (VP), and eventually, it would combine these to form the complete sentence (S).
Regexp Parser
A Regexp (regular expression) parser is used to search for and match patterns in text based on a specified regular expression. Suppose we want to find all email addresses in a given text. We can use a regular expression to define the pattern of an email address and then search for it within the text. Here's an example using Python's re module:
In this example, the regular expression r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b' defines the pattern for email addresses. The re.findall function searches the text for all occurrences of this pattern and prints them. This demonstrates how a Regexp parser can be used to extract specific information, like email addresses, from a text document.
Parsing with NLTK Package
NLTK is a package in Python that helps us implement Parsing in nlp. This package contains functions for all the operations and elements in parsing, such as:
- Nonterminal()
- Production()
- CFG()
- RecursiveDescentParser()
- ShiftReduceParser()...and many more.
You just have to import the functions and use them accordingly. For example:
Probabilistic Parser with NLTK
A probabilistic parser tackles ambiguity in parsing and generates the most likely parse tree. There are two types of probabilistic parser:
-
ViterbiPCFGParser:
This parser uses the concept of dynamic programming and parses the input text iteratively. -
Bottom-Up PCFG Chart Parser:
This parser produces multiple parse trees for a given input text. BottomUpPCFGChartParsers takes the help of BottomUpPCFGChartParser subclasses' constructors.
Stanford Parser
Helps in implementing dependency parsing with NLTK, Stanford parser is a state-of-the-art dependency parser. To implement this we need the Stanford CoreNLP parser and the required language model. The below code is an example of how to implement a Stanford parser.
Conclusion
- Parsing is extremely important and necessary for natural language processing.
- We now know what parsing is, the different types of parsers, and the challenges we face while parsing in NLP;
- Without parsing, there will be no structure to work upon, and things may go in the wrong direction.
- Although implementing a parser is not easy, once done, it is very helpful for various NLP processes.