Movie Review Prediction using TensorFlow
Overview
In this article, you will learn to build a neural network for sentiment analysis for making Movie Review Predictions. First, we must predict whether the movie review will be favorable or unfavorable. Then, we use the train and test text samples from the IMDb movie review dataset labeled as positive and negative. The Stanford AI Lab has made this IMDb movie review dataset available.
What are we Building?
A movie review's sentiment can be analyzed to determine whether it is good or negative, affecting its total score. Furthermore, based on the reviews, sentiment analysis can infer the attitude of the critics. Therefore, since the machine learns through training and evaluating the data, it is possible to automate determining whether a review is favorable or unfavorable.
Description of Problem Statement
The amount of data generated on the internet daily is enormous, and it will only grow as more and more people start utilizing it. At the same time can share their opinions and viewpoints on various subjects thanks to social networking sites, such as by submitting reviews of the movies they've seen on sites like IMDb. It would be impossible to manually sort through all of these reviews to determine whether a particular review is positive or negative. So, there is a need to automate this.
Pre-requisites
To solve this problem, We will adopt a natural language processing (NLP) method for recognizing the positivity and negativity of data. To implement this solution, you need to know about the basic knowledge of Deep Learning and its implementation with the TensorFlow library. In addition, you need to have a piece of knowledge of the Deep Learning model and its framework. Finally, you must also know natural language processing(NLP) and its application.
How are we Going to Build this?
Sentiment Analysis is one of the applications that classify texts into positive, negative, or occasionally neutral categories based on the context of the text. The IMDb movie reviews dataset, one of the well-known sentiment analysis datasets, is used in this article to discuss sentiment analysis using TensorFlow Keras.
Movie reviews are categorized in this manner as either positive or negative polarity. Instead of reading the entire review, this article's goal is to simplify it for anyone to paste a review and determine whether it is positive or negative based on the review's wording.
Final Output
Finding the reviews' polarity can benefit many different companies and industries. For example, using intelligent systems, we can give users in-depth reviews of movies, products, and services without making them read individual reviews. This allows us to make judgments based on the information the intelligent systems have provided. For example, the Multi-Layer Perceptron model, used in this article's algorithms, produced an accuracy of 86.22%.
Requirements
A low-level set of tools to create and train neural networks is offered by Google's TensorFlow2.x. With Keras, you can stack layers of neurons and work with various neural network topologies. We also use NumPy, a python library for working with arrays, and Tensorlfow, which imports dataset and model layers. Text vectorization is also supported using conventional word frequency and more sophisticated through-word embeddings.
Simple Multi-Layer Perceptron Model
Load the IMDB Dataset
You can load the dataset in a format prepared for usage in neural networks and deep learning models using the keras.datasets.imdb.load data() function.
The words are swapped with integers representing a word's absolute popularity within the dataset. Therefore, each review's sentence comprises a series of integers.
It is helpful that the imdb.load data() function accepts extra options, such as the maximum length of reviews to support and the number of top words to load.
Let's calculate some of the dataset's attributes after loading it. The complete IMDb dataset will be loaded at first as a training dataset, along with a few libraries.
Output:
Explore the Data
Examine the shape of the training dataset :
Output:
The review's excellent and poor sentiments can only be classified in a binary manner(0,1).
The first review appears as follows :
Output:
The content of reviews is integer-encoded, with each number standing for a particular word from the dictionary. The review's excellent and poor sentiments can only be classified in a binary manner(0,1).
We use the imdb.get word index() function from Keras. We can retrieve a dictionary that maps words to their corresponding indexes in the IMDB dataset.
Decode reviews from the index :
Output:
Word Embeddings
What is word embedding? Word embedding is a recent development in the field of natural language processing. Where a high-dimensional space, words are represented as real-valued vectors, with the closeness of the vector space indicating how similar the words are to one another in meaning.
Word vectors' fixed length and decreased dimensions enable us to express words more effectively. Thanks to the word embedding layer, we can turn each word into a fixed-length vector with a predetermined size. The resulting vector is dense and does contain not only 0s and 1s but also actual values.
Build the Model
You can start by creating a simple single-hidden-layer multi-layer perceptron model.
We are importing the classes and functions needed for this model.
You'll then load the IMDB dataset. As the what is word embeddings section says, you will simplify the dataset by loading only the top 5,000 comments.
Additionally, the dataset will get split into training and test sets. This usual split mechanism works well. Reviews will be restricted to 500 words, with longer reviews being zero-padded and shorter reviews truncated.
Layers, Loss Function, and Optimizer
You can now start building your model. First, you'll use an Embedding layer as the input layer, setting the word vector size to 32 dimensions, the input length to 500, and the vocabulary to 5,000. As mentioned, this first layer's result will be a matrix with 32 x 500 dimensions.
After flattening the output of the word-embedded layers to one dimension, you will utilize a dense hidden layer of 300 units with a relu function. One neuron makes up the output layer, which employs sigmoid activation to produce 0 and 1 as predictions.
The effective ADAM optimization method is used to optimize the model, which employs logarithmic loss.
Output:
Train the Model
You can fit the model during training and validate it using the test data. However, due to how quickly this model overfits, you will only utilize a few training epochs, in this case, just three.
You will use a batch size of 130 because there are many data. You will assess the model's accuracy after training on the test dataset.
Output :
Evaluate the Model
As you can see, this extremely straightforward model efficiently earns a score of 86%, close to the original work.
Output:
Prediction
Let’s take the data from x_test and predict the polarity of the review with the model we build.
predict_x provides an array of predictions which is a float. Then, we use the numpy.argmax() function to return the indices of the array's maximum element (i.e., 0 or 1) along the axis.
Verify Predictions
In the above model building, we have examined the model's accuracy. Now, we are going to evaluate the performance of the model. For this, we will import metrics from the sklearn library.
Output:
We can improve the model performance accuracy by adding more layers and, at the same time, by increasing the training samples.
Word Embeddings
To study word embedding, we develop a function that gives, given an input, the output of the embedding layer of the multi-perceptron model. To test this, let's do our review, encrypt it, and embed it :
Output:
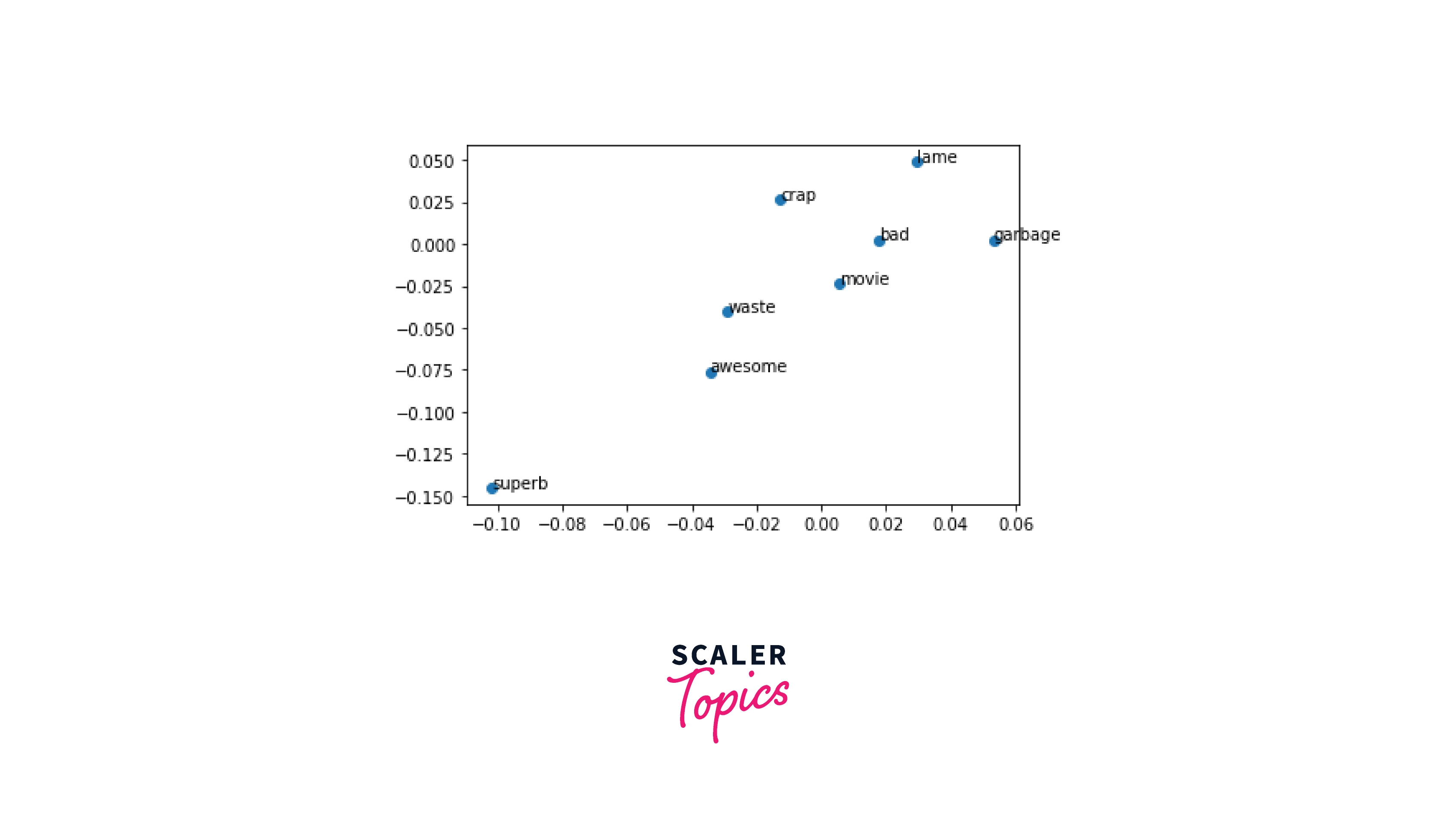
Words with similar meanings are indeed clustered together, as can be seen. One set has the words "superb" and "awesome”, The comments on this part of the plane have positive commands. We have "lame", "crap", and... "garbage" on the opposite side.
The dense layer in our network aims to compile data from the whole point distribution for each review.
Conclusion
You learned about the IMDB sentiment analysis dataset for accessing in this article. In addition, you discovered how to create the following deep-learning models for sentiment analysis :
- How to use Keras to examine and load the IMDB dataset.
- How to build an extensive neural network model for sentiment analysis.
- Explore the word embeddings created using the model.