Working Principle of a Transformer
Overview
Transformers have emerged as a groundbreaking technology in natural language processing (NLP), enabling significant advancements in various applications such as machine translation, sentiment analysis, text generation, and more. At the core of these advancements lies the remarkable working principle of transformer, which has revolutionized how computers understand and generate human language. This article aims to provide an in-depth understanding of the working principle of transformer and its importance in NLP.
The Importance of Transformers in NLP
Transformers have proven to be of paramount importance in NLP for several reasons:
- Contextual Understanding:
The self-attention mechanism empowers transformers to capture the contextual relationships between words in a sentence. This enables the model to better understand the nuanced meanings of words based on their surrounding context, leading to more accurate and contextually relevant language processing. - Parallelization:
Unlike traditional sequential models, transformers can process input sequences in parallel, making them highly efficient and reducing training times. This parallelization is crucial for handling the vast amount of data encountered in NLP tasks, enabling faster and more scalable language processing. - Long-Range Dependencies:
The ability to capture long-range dependencies in language is a significant advantage of transformers. This enables them to establish connections between words that are far apart in a sentence, leading to more coherent and meaningful language generation. - Transfer Learning:
Transformers can be pretrained on vast corpora of text, acquiring a general understanding of language structures. This pretrained knowledge can be fine-tuned for specific NLP tasks with smaller datasets, leading to faster and more accurate performance on various language-related applications.
The combination of these factors has made transformers the go-to architecture in NLP, driving substantial progress in areas like machine translation, sentiment analysis, text summarization, question-answering systems, and more.
The Transformer Architecture
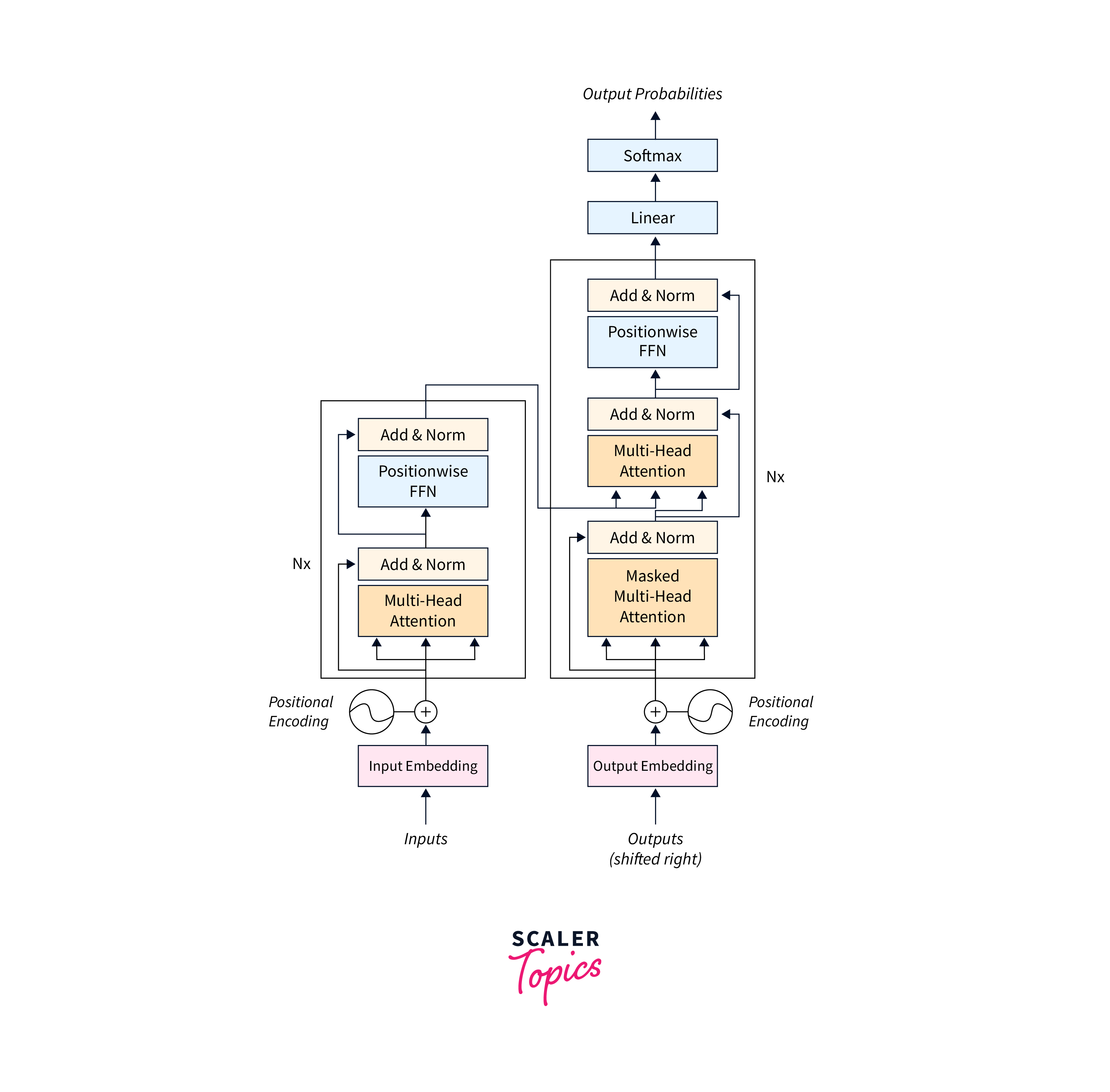
The transformer principal architecture deviates from sequential processing and adopts a parallel and attention-based approach. It consists of an encoder and a decoder, which work together to process input sequences and generate output sequences. Attention mechanisms are pivotal in allowing the model to focus on relevant information.
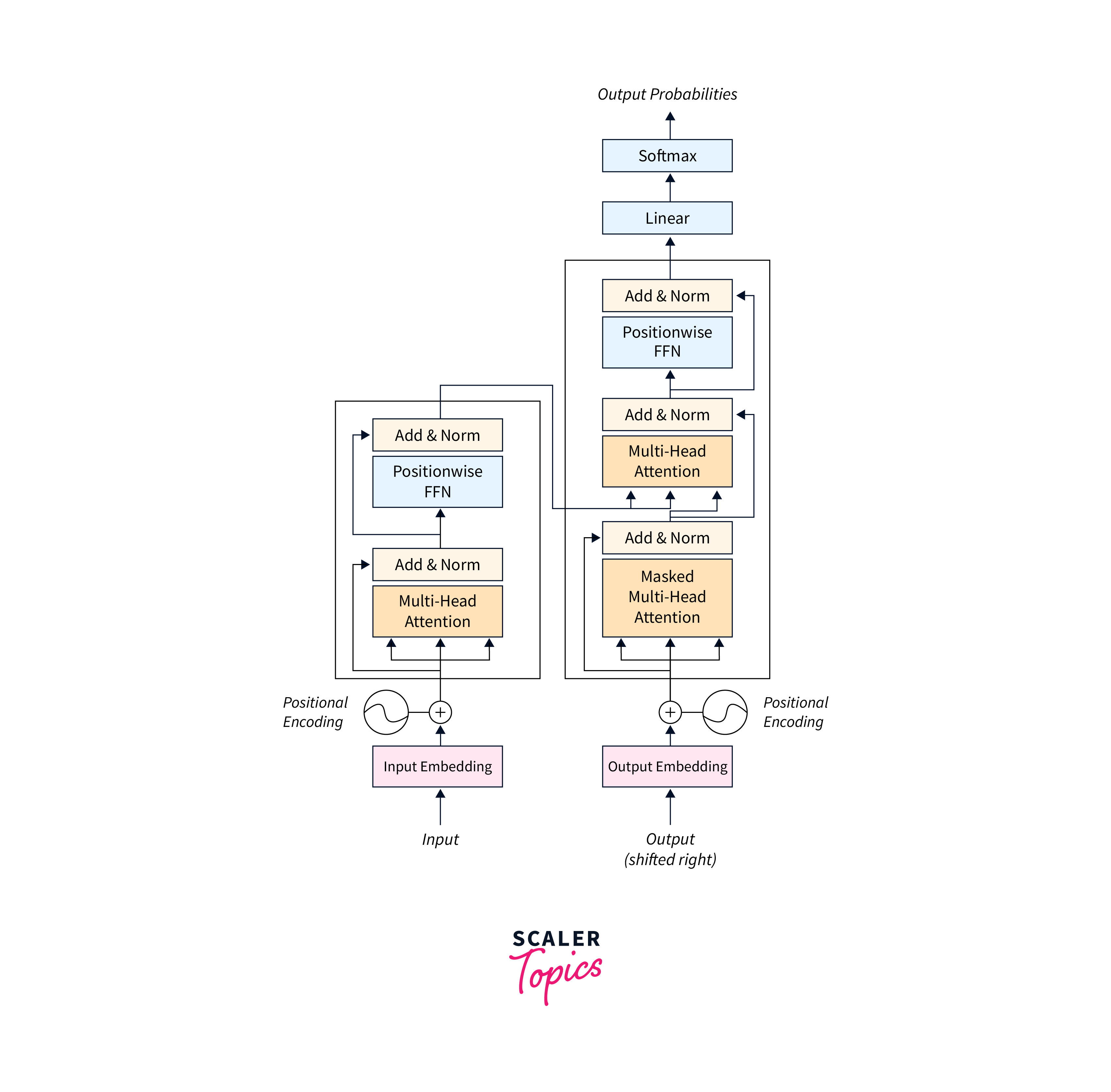
Overview of the Transformer Model
The transformer model, introduced in the paper "Attention Is All You Need" by Vaswani et al. in 2017, revolutionized Natural Language Processing (NLP). Traditional models like RNNs and CNNs struggled with capturing long-range dependencies in language, limiting their contextual understanding.
Transformers introduced self-attention mechanisms, enabling the model to weigh the relevance of words in an input sequence relative to each other. This approach allows transformers to consider the entire context simultaneously, capture complex linguistic patterns, and understand the relationships between distant words in a sentence.
Components of the Transformer
The transformer model consists of several key components:
-
Encoder
The encoder is responsible for processing the input sequences and extracting their contextual information. It consists of multiple encoder layers, usually stacked on each other. Each encoder layer contains two sub-layers: a self-attention mechanism and a position-wise feed-forward neural network.- Self-Attention Mechanism:
The self-attention mechanism allows the encoder to weigh the importance of each word/token in the input sequence by attending to other words/tokens within the same sequence. It calculates attention weights for each word/token based on its relationship with other words/tokens, effectively capturing dependencies and contextual information. - Position-wise Feed-Forward Neural Network:
After the self-attention mechanism, each encoder layer applies a position-wise feed-forward neural network to the hidden representations. This network introduces non-linear transformations, enabling the model to learn complex mappings between the input and output representations.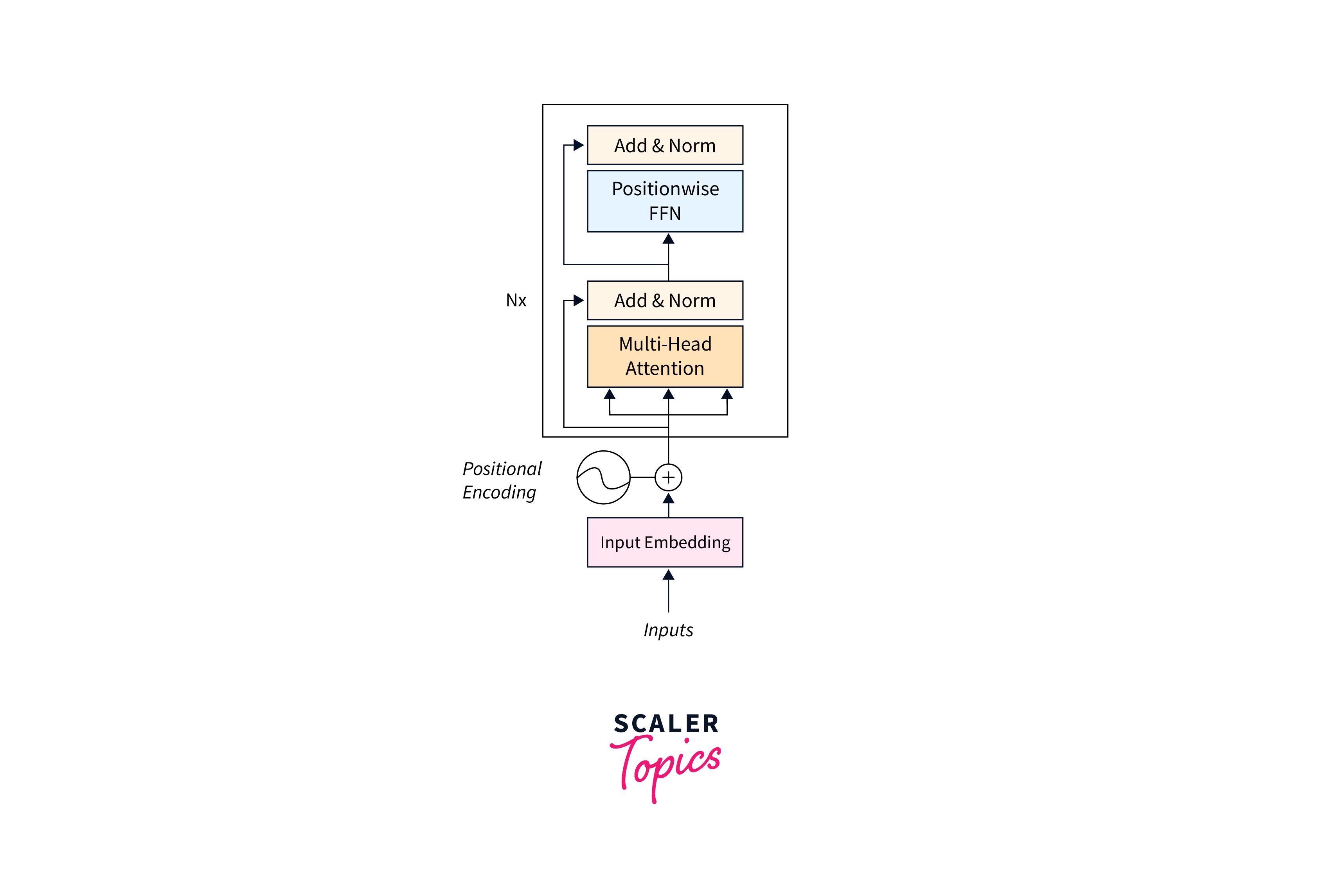
- Self-Attention Mechanism:
-
Decoder
The decoder takes the encoded input and generates the final output sequence. It also consists of multiple decoder layers, typically identical in structure to the encoder layers. Each decoder layer has three sub-layers: self-attention, encoder-decoder attention, and position-wise feed-forward networks.- Self-Attention:
Similar to the encoder, the self-attention mechanism in the decoder allows it to attend to different positions in the decoder sequence. It enables the decoder to capture the relevant context from the previously generated words in the output sequence. - Encoder-Decoder Attention:
The encoder-decoder attention mechanism allows the decoder to attend to the hidden representations generated by the encoder. It helps the decoder capture the relevant information from the input sequence while generating the output.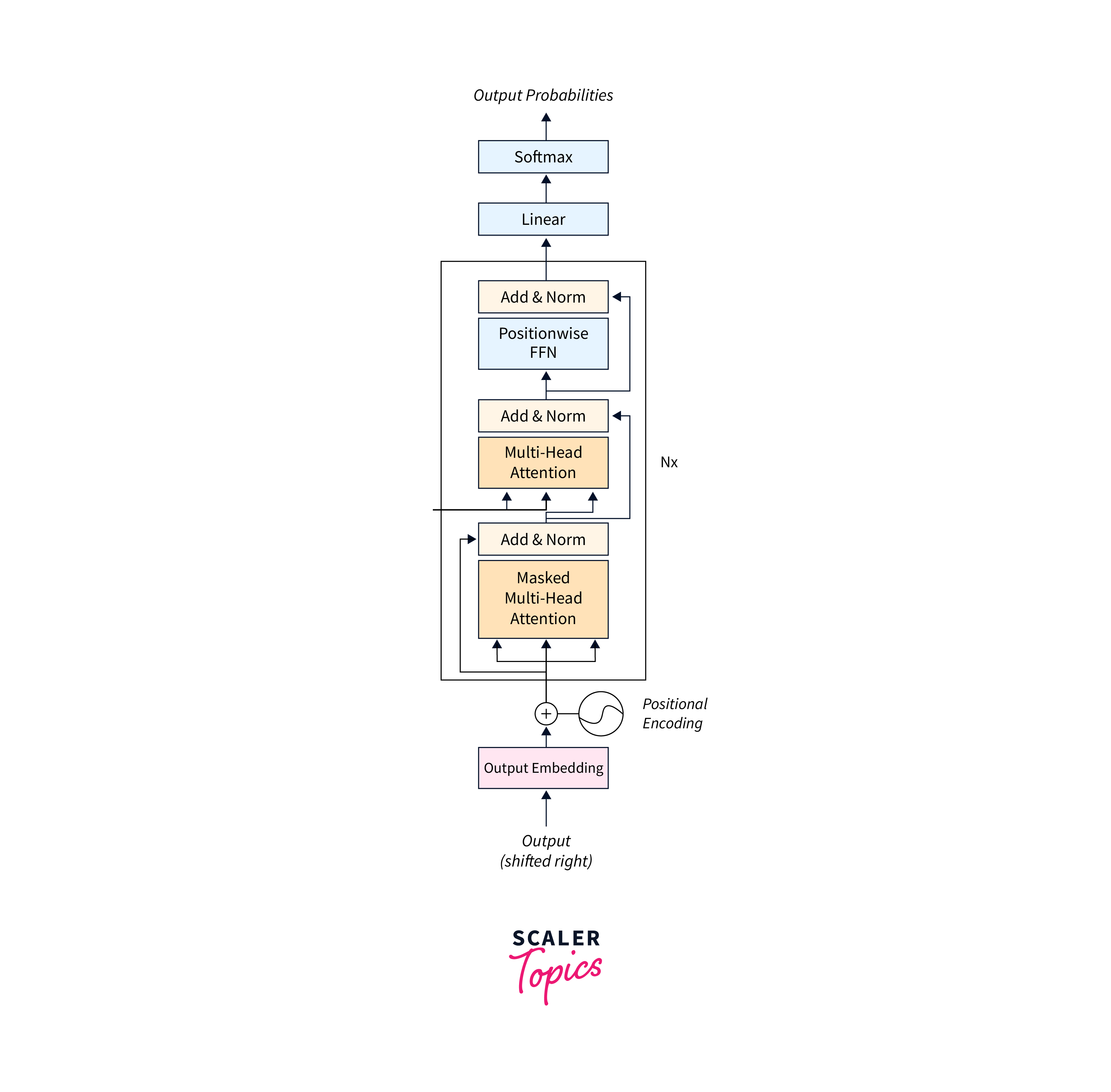
- Self-Attention:
-
Attention Mechanism
The attention mechanism is a fundamental component of the transformer model and is used in both the encoder and decoder. It enables the model to selectively focus on relevant parts of the input sequence by assigning weights to different elements based on their relevance.- Self-Attention:
Self-attention within the transformer allows each word/token to attend to all other words/tokens in the same sequence, capturing their dependencies and relationships. It enables the model to assign varying levels of importance to different words/tokens, depending on their relevance to the context. - Encoder-Decoder Attention:
The encoder-decoder attention mechanism helps the decoder attend to the relevant information in the encoded input sequence while generating the output. It allows the decoder to align its attention with the important parts of the input sequence for accurate generation.
These components work together to enable transformers to capture and model the dependencies and contextual relationships within the input sequences, resulting in their remarkable performance in various NLP tasks.
- Self-Attention:
Input Representation
Input representation in transformers is essential for handling variable-length sequences and capturing contextual relationships between words, enabling accurate language processing in NLP tasks.
To facilitate the input representation in transformers, two essential techniques are employed:
- Word Embeddings:
Word embeddings are high-dimensional vector representations that capture the semantic meaning of words. Each input token (word or subword unit) is mapped to its corresponding word embedding in transformers. These embeddings encode the contextual information of the tokens in the context of the entire sequence. Word embeddings are learned during the training process and updated based on the task. They allow the model to understand the meaning and relationships between different words in the input sequence. The model can perform operations and calculations by representing words as continuous vectors, capturing their semantic similarity and contextual relevance. Word embeddings are essential for transformers as they provide a dense, continuous representation of words, enabling the model to handle a large vocabulary and generalize well to unseen words.
- Positional Encoding:
Positional encoding is crucial for capturing the sequential order of the input tokens in the transformer model. Unlike recurrent neural networks (RNNs) or convolutional neural networks (CNNs), transformers do not inherently capture sequential information. To incorporate positional information, positional encoding is added to the word embeddings. It provides the model with information about the relative position of each token within the sequence. Positional encoding is typically represented as a vector or matrix added element-wise to the word embeddings. There are different methods to encode positional information, with the most common approach being the use of sine and cosine functions with different frequencies and offsets. This allows the model to learn the relative positions of the tokens based on their sinusoidal patterns.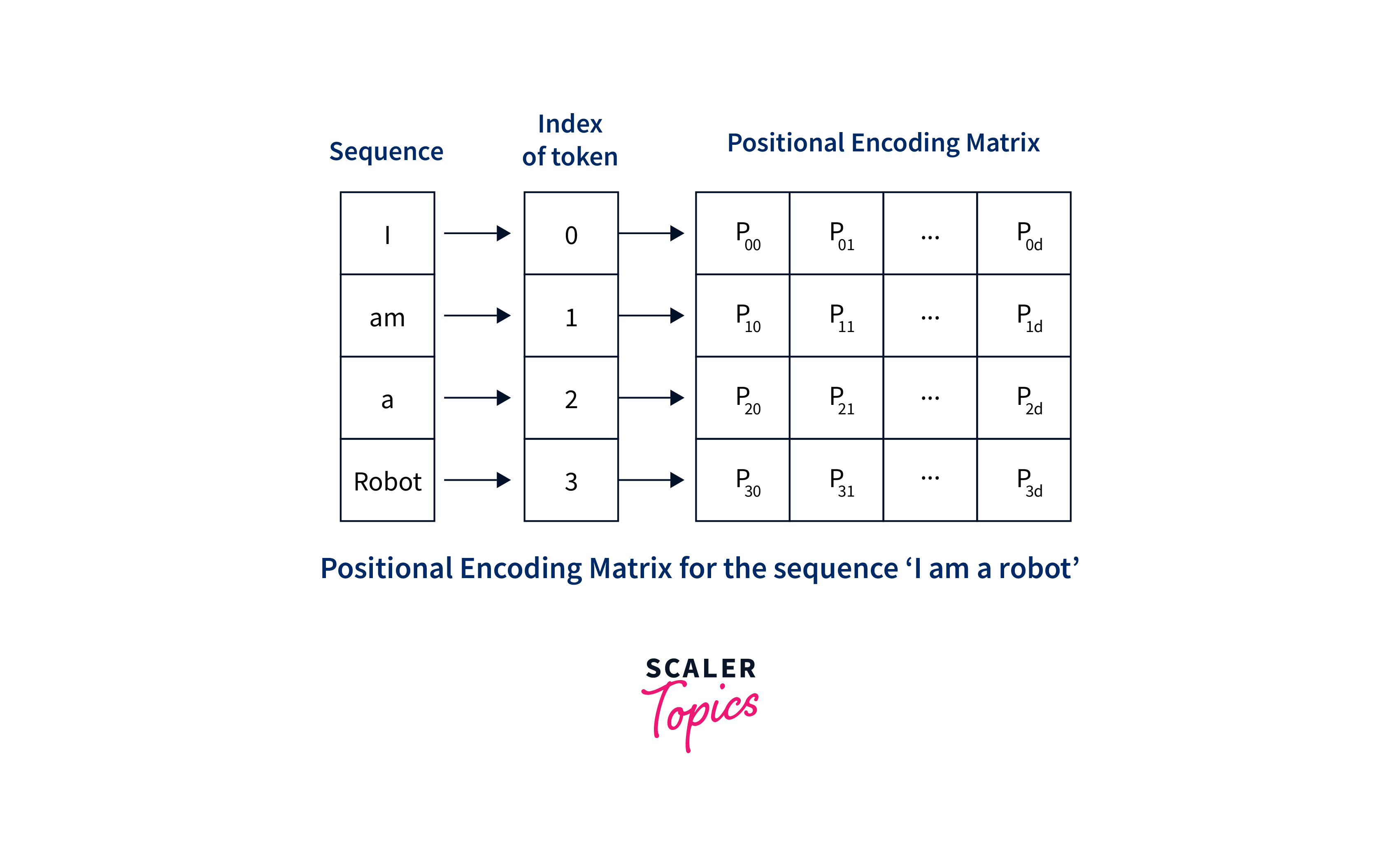
By including positional encoding, transformers can differentiate between tokens based on their position in the sequence, enabling the model to understand the sequential structure and dependencies of the input.
Combining word embeddings and positional encoding ensures that the transformer model can effectively process and understand the input sequences, capturing both the semantic meaning of words and their sequential order.
Encoder-Decoder Architecture
Stacking multiple encoder and decoder layers in the transformer model is a common practice to enhance the representation capability and capture complex dependencies within the input and output sequences.
- Stacking Multiple Encoders and Decoders:
To increase the representation capability of the model and capture complex dependencies, transformers often stack multiple encoder and decoder layers. Stacking multiple encoders allows the model to capture finer-grained information and learn hierarchical representations of the input sequence. Similarly, stacking multiple decoders enhances the model's ability to generate complex and contextually rich output sequences. By stacking multiple layers, the transformer principal model can capture more intricate patterns and dependencies in the input-output mappings. It enables the model to learn more abstract representations and effectively handle a wide range of NLP tasks.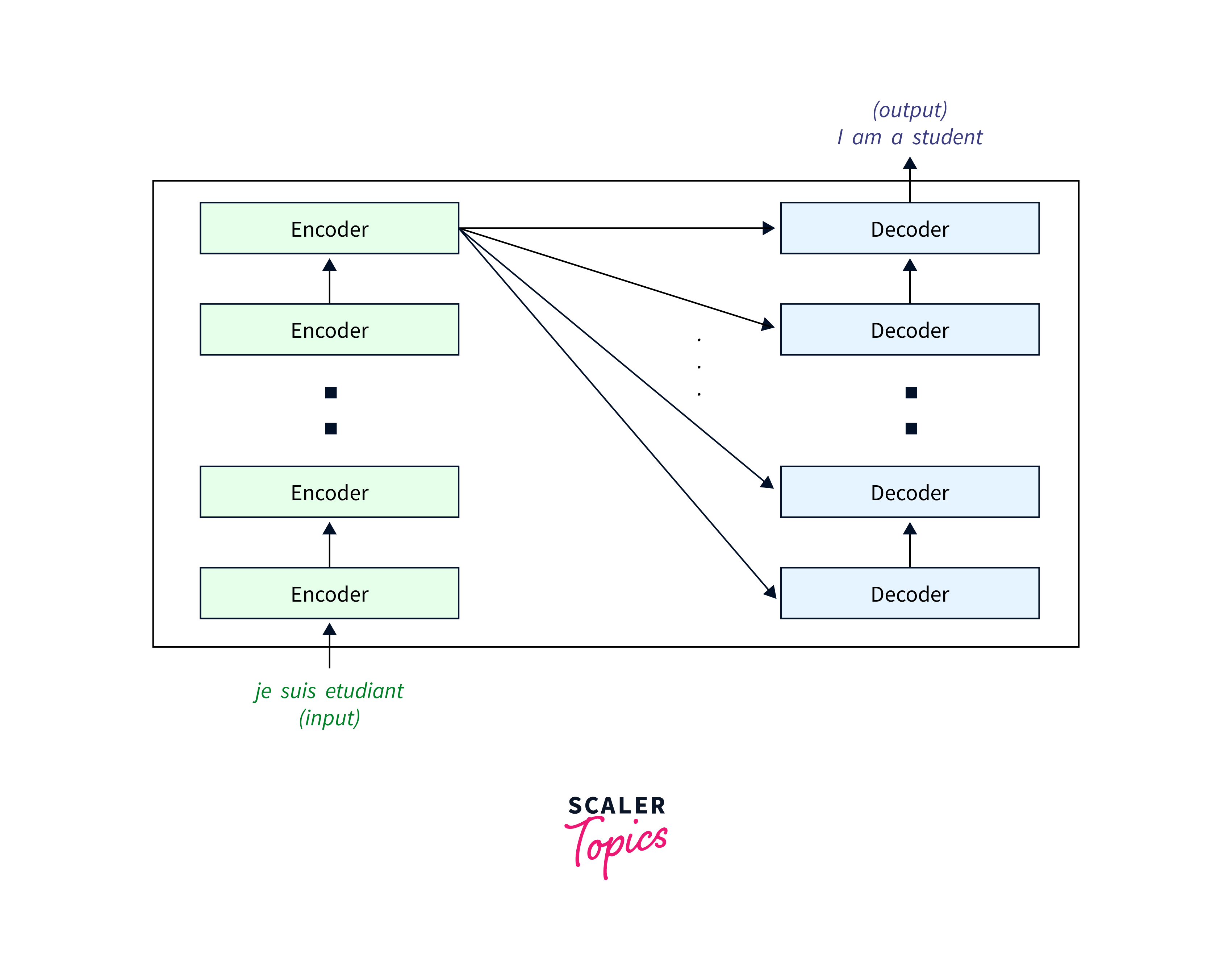
In conclusion, the encoder-decoder architecture and the stacking of multiple layers are key aspects of the transformer model. It allows the model to process input sequences, capture dependencies, and generate output sequences with rich contextual information.
The Attention Mechanism
The attention mechanism is a crucial building block of transformer models, revolutionizing how they process sequences in natural language. Unlike traditional models that process input sequentially, the attention mechanism empowers transformers to selectively focus on relevant elements within the input sequence, enhancing their ability to understand and generate human language.
At its core, the attention mechanism allows the model to assign different weights to different parts of the input sequence, giving higher importance to more relevant elements and downplaying the significance of less relevant ones. This process enables the model to capture long-range dependencies between words, which is especially valuable for understanding complex sentence structures and linguistic relationships.
The Concept of Attention in Deep Learning
Attention in deep learning refers to the ability of a model to dynamically allocate its computational resources to different parts of the input data. It enables the model to focus on the most relevant information while ignoring irrelevant or less important parts. Attention mechanisms mimic the human cognitive process of selectively attending to specific input aspects.
In the context of transformer models, attention mechanisms are applied to capture relationships between words or tokens in a sequence. Instead of treating all words equally, attention mechanisms allow the model to assign varying levels of importance or attention to different words, emphasizing the most relevant ones for the task.
Scaled Dot-Product Attention
Scaled dot-product attention is a popular formulation of attention used in transformer models. It calculates the attention weights between a query and a set of key-value pairs. Here's an overview of the steps involved:
- Query, Key, and Value:
Each word/token in the input sequence is associated with a query, key, and value. These are learned linear projections of the input embeddings, allowing the model to encode the relationships between the words. - Similarity Calculation:
The attention mechanism computes the similarity between the query and each key using a dot product. The dot products are scaled by the square root of the dimension of the key vectors to prevent large values that could result in unstable gradients. - Softmax and Attention Weights:
The dot products are passed through a softmax function to obtain attention weights. These weights represent each word's importance or relevance in the query sequence. - Weighted Sum:
The attention weights are used to calculate a weighted sum of the value vectors. This weighted sum serves as the attended representation, capturing the information from the relevant words in the sequence.
Multi-Head Attention
Multi-head attention is an extension of the attention mechanism in transformers. It allows the model to capture different relationships and dependencies by performing attention computation multiple times with different learned linear projections. Each attention head attends to different parts of the input sequence and provides a unique perspective on word relationships.
1. Concept In multi-head attention, the input embeddings are linearly projected into multiple queries, keys, and values. Attention is computed independently for each head, resulting in multiple attention weights and attended representations. These multiple sets of attention results are concatenated or combined to provide a rich and diverse representation of the input sequence.
2. Benefits
- Capturing Different Relationships:
By performing attention with multiple heads, the model can capture different relationships between words. Each head may focus on different aspects, such as local dependencies, global dependencies, or specific patterns, leading to a more comprehensive understanding of the input sequence. - Enhanced Representation:
The combination of multiple attention heads allows the model to generate a richer representation by capturing multiple perspectives and aspects of the input. This leads to more robust and expressive representations that capture complex patterns and dependencies. - Improved Generalization:
Multi-head attention helps the model generalize better by attending to different parts of the input sequence. It reduces over-reliance on a single attention mechanism and prevents the model from being biased towards specific patterns or dependencies.
The Flow of Information
The flow of information in a Transformer model can be summarized as follows:
a. From Input Embeddings to Encoders
The input sequence, typically represented as a sequence of tokens, is converted into dense vector representations called input embeddings. Each token is mapped to a high-dimensional vector using techniques like word embeddings.
b. Through the Attention Layers
The input embeddings with positional encoding are passed through multiple encoder layers. In each encoder layer, the self-attention mechanism attends to the input sequence, capturing dependencies between the tokens. The output of each encoder layer is a refined representation of the input sequence.
c. Decoding the Output
The encoder output is then fed into the decoder. Similar to the encoder, the decoder consists of multiple decoder layers. In each decoder layer, self-attention and encoder-decoder attention mechanisms are applied to the previous outputs (auto-regressive) and the encoder's hidden representations. This allows the decoder to generate the output sequence step by step.
d. The Final Linear and Softmax Layers
The decoder output is passed through a linear layer, followed by a softmax activation function. This generates a probability distribution over the vocabulary for each position in the output sequence. The model selects the token with the highest probability as the predicted output at each position.
Throughout the flow of information, attention mechanisms play a crucial role. They allow the model to selectively attend to relevant parts of the input sequence, capture dependencies, and understand the context necessary for accurate output generation.
This iterative process, combined with the attention mechanisms, enables the model to understand and generate contextually relevant sequences.
Implementing a Simple Transformer in Python
To gain hands-on experience with working of transformer, implementing a simple transformer model in Python can be an instructive exercise. For implementation, we use the TensorFlow library.
Imports
Import the necessary modules required for the working of transformer. Also, define the hyperparameters.
Building a Transformer
Now, we are going to dive in building the componenets of a Transformer achitecture one after the other from Positional encoder to decoder.
1. Positional Encoding
The below function generates positional encodings for a given sequence length and depth. Positional encodings are used in transformer models to provide positional information to the model, enabling it to understand the order and relative positions of words or tokens in a sequence.
2. Positional Embeddings
You can also do the positional embedding layer which takes an input sequence, applies word embeddings, and adds positional encodings to provide semantic and positional information to the model.
3. Scaled Dot Product Attention Layer
The scaled_dot_product_attention function provides a fundamental component of the attention mechanism, which is widely used in deep learning models, particularly in the Transformer architecture. Here's an overview of what the function does:
4. Multi Head Attention
Multi Head Attention extends the basic scaled dot-product attention mechanism to enable the model to focus on different parts of the input sequence simultaneouslHere's an example of a self-attention layer:
5.Point wise feed forward network
The primary purpose of the Point-wise Feed-Forward Network is to apply a non-linear transformation to the output of the Multi-Head Attention mechanism. Here's an overview of the Point-wise Feed-Forward Network:
6. Encoder
The encoder in a transformer model processes the input sequence and creates contextual embeddings for each word/token.
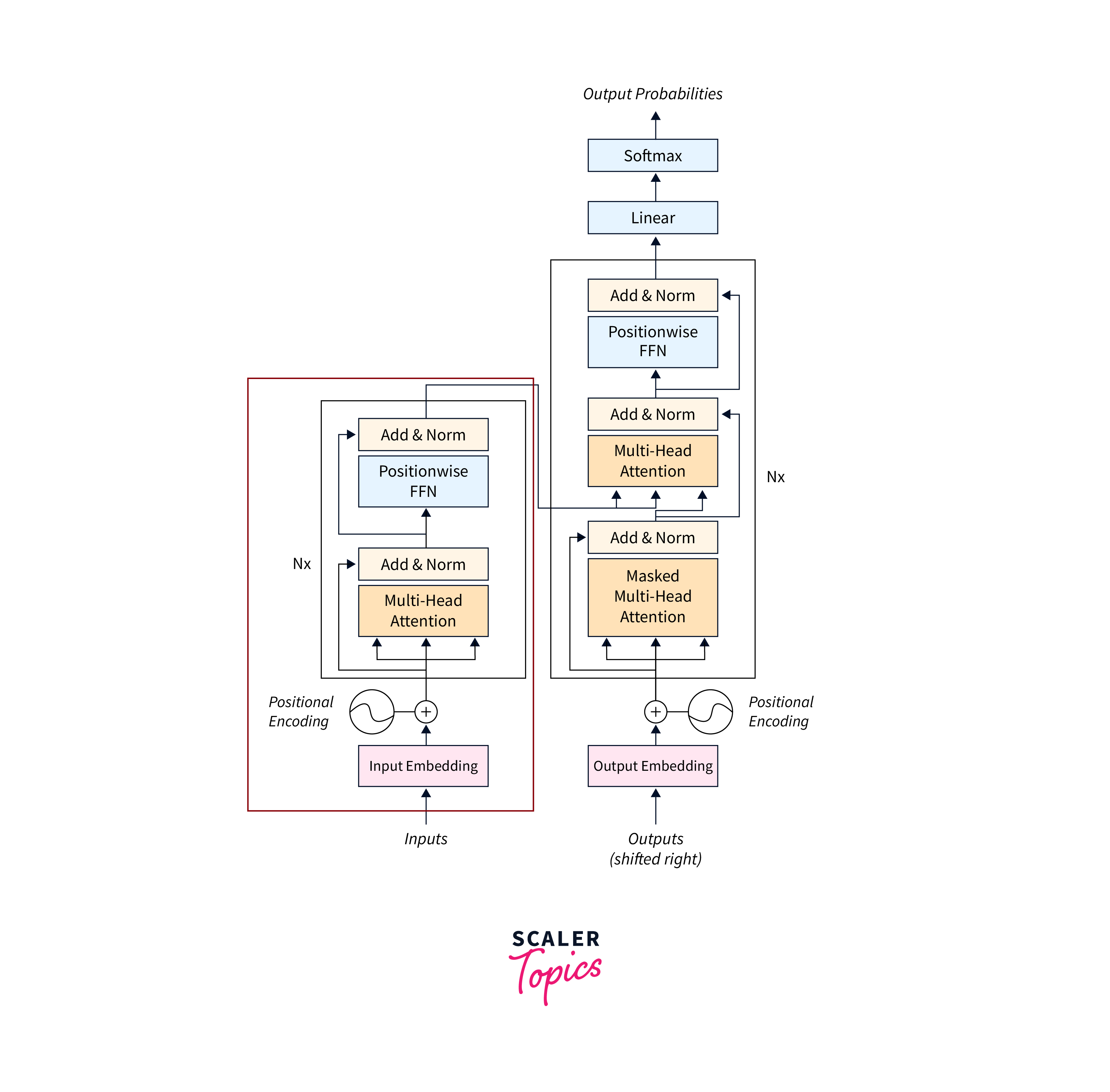
- Encoder
- The encoder Layer:
The Encoder consists of sub-layers that process the input sequence and capture relevant information.
7. Decoder
The decoder in a transformer model generates the output sequence based on the contextual embeddings and attention weights learned during training.
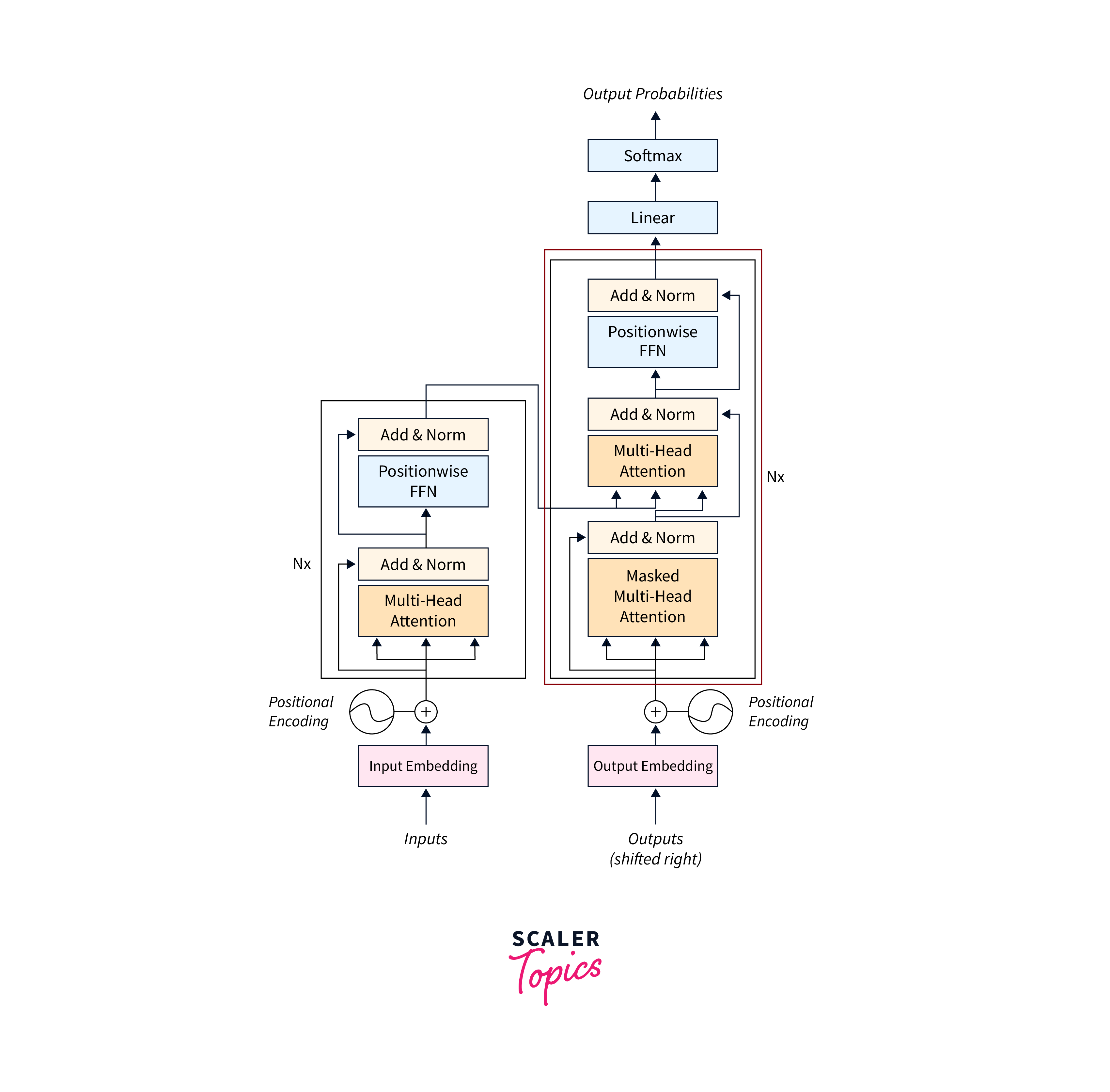
- The Decoder layer
The decoder layer is similar to the encoder layer but has additional sub-layers to enable the generation of the output sequence. It typically consists of three sub-layers: masked multi-head self-attention, encoder-decoder attention, and feed-forward network. These sub-layers work together to capture relevant information from the encoded input and generate the output sequence. - The Decoder
The decoder in a transformer model is responsible for generating the output sequence by sequentially decoding the encoded input. It consists of multiple decoder layers, which are stacked on top of each other.
8. The Transformer
Finally, the complete implementation of the Transformer model
Output

- Testing a Transformer

Conclusion
- Transformers have revolutionized the natural language processing (NLP) field by enabling significant advancements in various applications such as machine translation, sentiment analysis, and text generation.
- The working principle of Transformer is based on self-attention, which allows the model to capture dependencies and contextual relationships across words or tokens in a sequence.
- Transformers consist of an encoder-decoder architecture, where the encoder processes the input sequence, and the decoder generates the output sequence.