Sqoop Starting
Overview
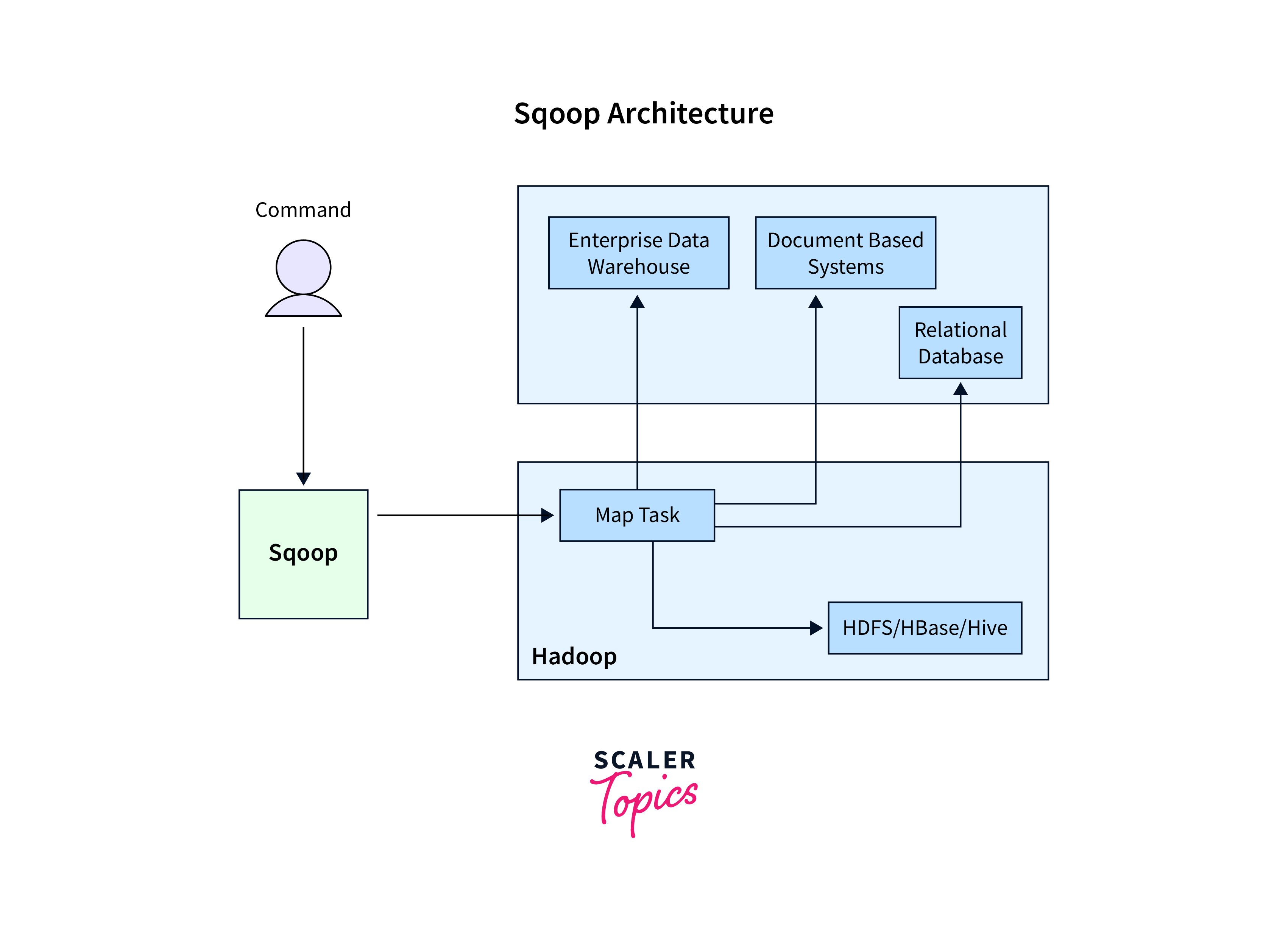
In the world of big data, data migration between traditional relational databases and Hadoop's distributed ecosystem is crucial for efficient data processing and analysis. Sqoop, an essential tool in the Hadoop ecosystem, enables the transfer of large volumes of data between relational databases and Hadoop, providing a seamless data integration process. This article serves explore concepts of starting sqoop.
Syntax:
Explanation:
- generic-args: Common arguments that apply to all Sqoop tools. Example: --connect, for specifying the JDBC connection string, and --username and --password, for authentication.
- tool-name: Sqoop tool being used, such as import or export.
- tool-args: Arguments specific to the chosen Sqoop tool. Example: --table, for the table name, and --target-dir for specifying the HDFS directory where data will be stored.
:::
Installation and Configuration
Before exploring starting sqoop and its the features, it's essential to set up the Sqoop within your Hadoop ecosystem. To achieve this, you can refer to the detailed guide on Sqoop integration with Hadoop, available at Scalar Hadoop.
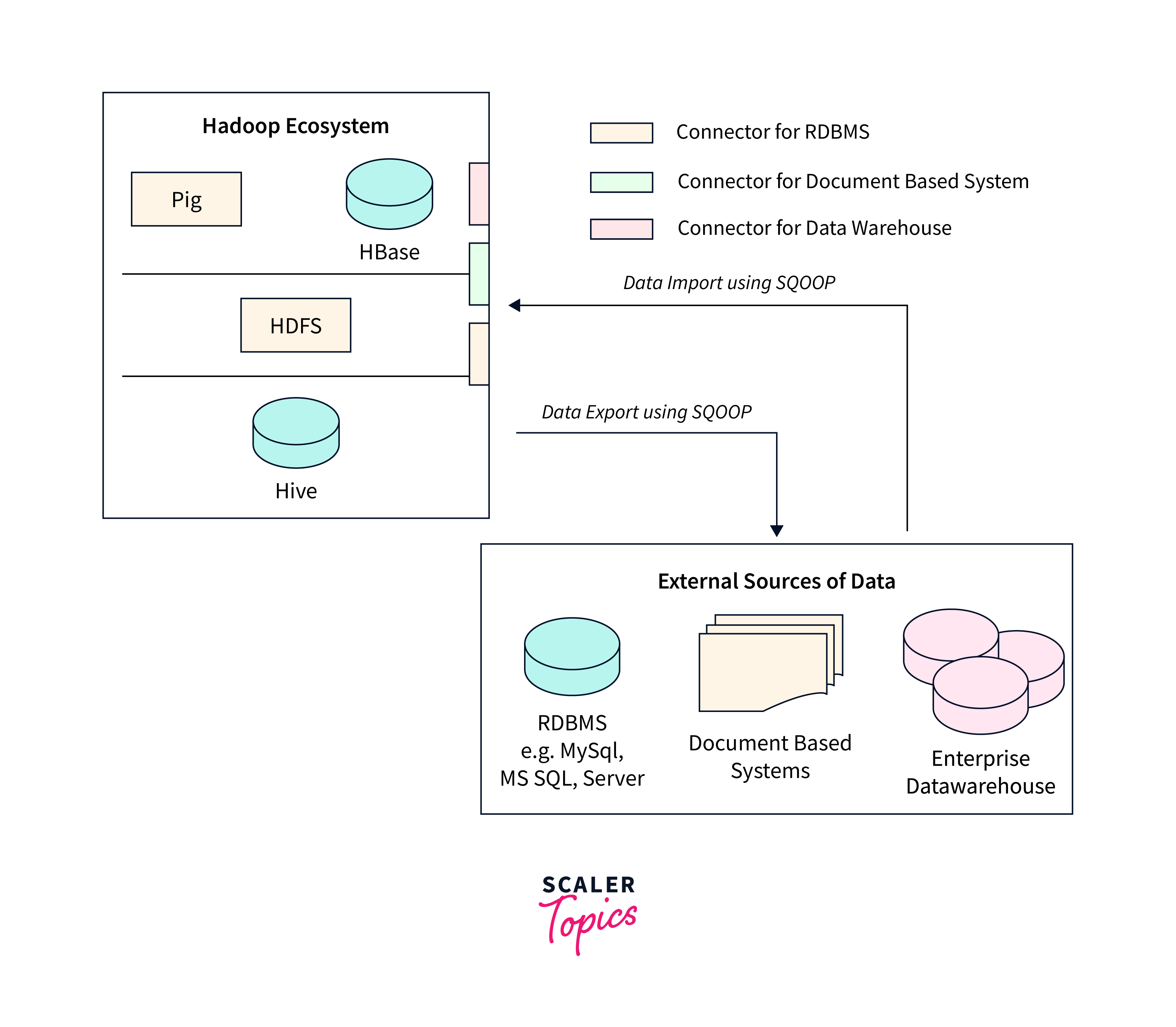
Supported Data Sources
Sqoop supports various relational databases as mentioned below for data transfer between these databases and the Hadoop distributed file system (HDFS).
- MySQL
- PostgreSQL
- Oracle
- SQL Server
- Others
Syntax:
The syntax for starting sqoop and importing data from a MySQL database:
The jdbc changes based on the database. For instance, for PostgreSQL, we will use jdbc:postgresql://hostname:port/database \ as a connection string.
Database-specific Options:
Multiple database-specific options can be used based on the data source that is being used with starting sqoop tools.
MySQL-Specific:
- --mysql-delimiters: Handle delimiters in MySQL data during import or export.
- --mysql-enum-as-strings: Ensures that ENUM columns are treated as strings in Hadoop when importing data from MySQL.
- --mysql-opt: Pass arbitrary MySQL options for custom MySQL-specific behaviors.
PostgreSQL-Specific:
- --direct: Enables direct export mode which uses PostgreSQL's COPY command for faster data transfer when exporting data.
- --postgres-upsert: Exporting data with PostgreSQL's UPSERT (INSERT ON CONFLICT) capability, allowing updates or inserts based on primary keys or unique constraints.
Oracle-Specific:
- --direct: Import or export mode with Oracle's direct path load mechanism for improved performance.
- --oracle-external-table: When importing data, allows data to be read directly from external files rather than copying to an intermediate location.
- --map-column-java: Specify mapping between Oracle column types and Java data types.
SQL Server-Specific:
- --direct: Direct data transfer with bulk import/export capabilities.
- --sqlserver-use-new-import-api: Enables the use of the newer SQL Server Import API, enhancing performance.
Generic:
- --fetch-size: Number of rows fetched in each database round trip.
- --direct-split-size: Split size of data blocks, impacting parallelism.
Importing Specific Tables and Queries
Sqoop provides the capability for starting sqoop and import specific tables and execute custom queries, offering control over the data integration process. It allows users to extract only the required data for analysis, minimizing resource consumption and optimizing performance.
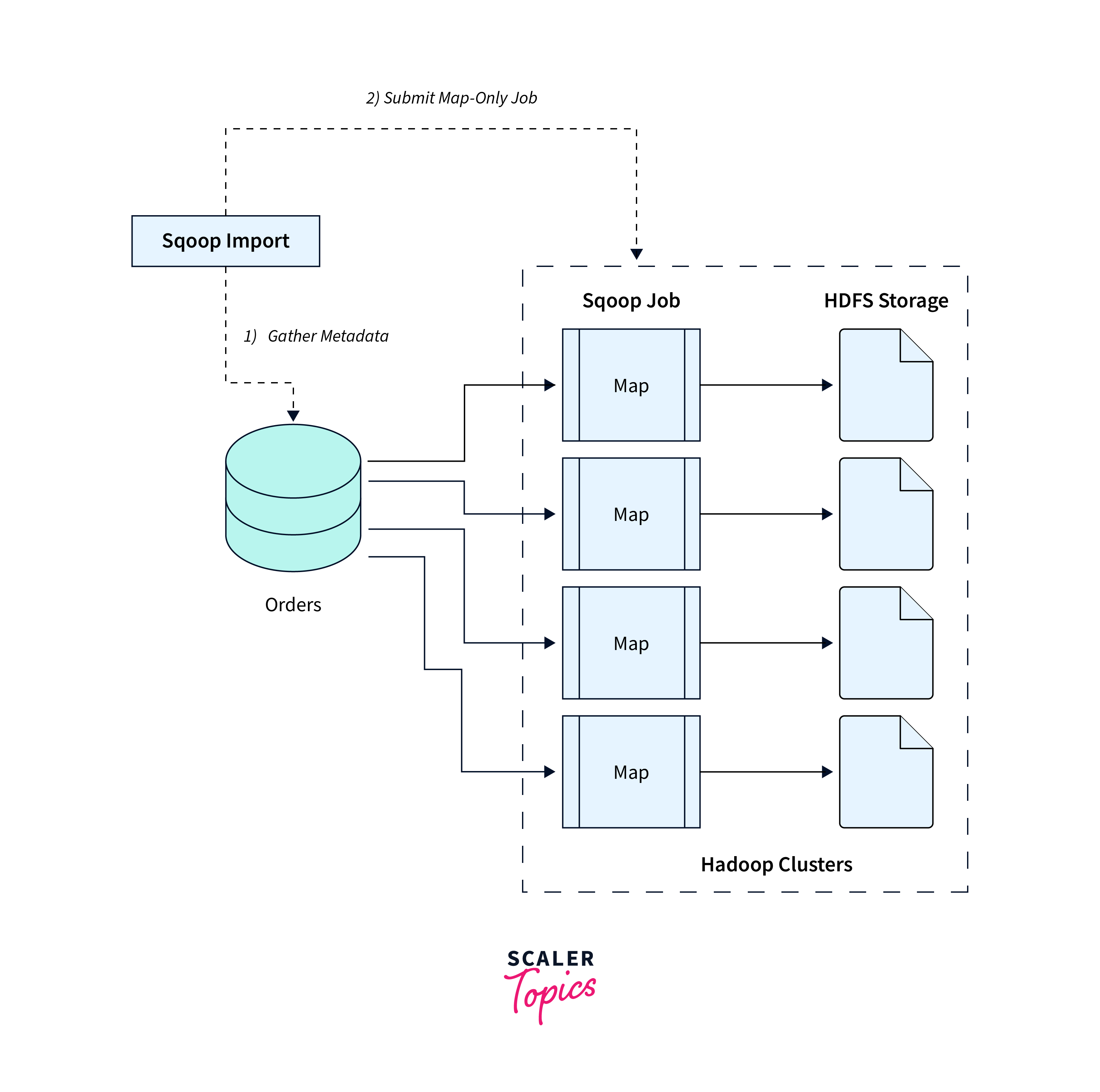
Syntax:
Explanation:
- --table: Name of the table to be imported.
- --columns: Columns to be imported from the table.
- --query: Enables the execution of a custom SQL query for data extraction.
- --split-by: Split based on specifed data into multiple tasks for parallel import.
- --target-dir: HDFS directory where the imported data will be stored.
- --num-mappers: number of parallel map tasks.
Examples:
To import data from a MySQL database using a custom SQL query:
The \$CONDITIONS is a placeholder used by starting sqoop to split data efficiently in parallel tasks.
Data Serialization and Formats
Sqoop offers a range of data serialization and formatting options that optimize data transfer efficiency, storage utilization, and compatibility.
Syntax:
Formats:
The formats are specifed by the --as-<format> argument. You can refer the Supported Data Formats section of the Sqoop tools article and the --<schema-name>-schema parameter specifes the path to specific(<shema-name>) schema file. This allows a custom schema for data import or export.
Options:
- --compress: Enables data compression during import.
- --compression-codec: Specifies the compression codec to be used.
- --null-string: Replaces occurrences of a null string in text fields during import.
- --null-non-string: Replaces occurrences of a null non-string value in text fields during import.
- --input-null-string: The string that represents null values in string columns.
Data Serialization Algorithms:
The different algorithms supported on starting sqoop for data serialization are:
- None: No serialization or compression.
- Gzip: Efficient transfer and storage.
- Bzip2: Offers high compression ratios.
- Snappy: Provides fast compression and decompression.
- LZO: Lempel-Ziv-Oberhumer (LZO) algorithm is optimized for high-speed compression.
- LZ4: Provides fast compression and decompression rates.
- Deflate: Lite and widely used compression method.
- Zstandard (Zstd): Balance between compression speed and ratio.
Example:
To import data from an Oracle database in Avro format with Snappy compression and also replace null strings and non-strings with custom values:
Explanation:
In this example, any null string occurrences in the source data will be replaced with the string <NULL> and any null values that are not of string type will be replaced with the value <N/A> in the Hadoop environment.
Data Serialization and Compression in Export
Sqoop supports data serialization and compression during the export process on starting sqoop, that ensures capability for data exported from Hadoop to maintain optimal efficiency and storage utilization.
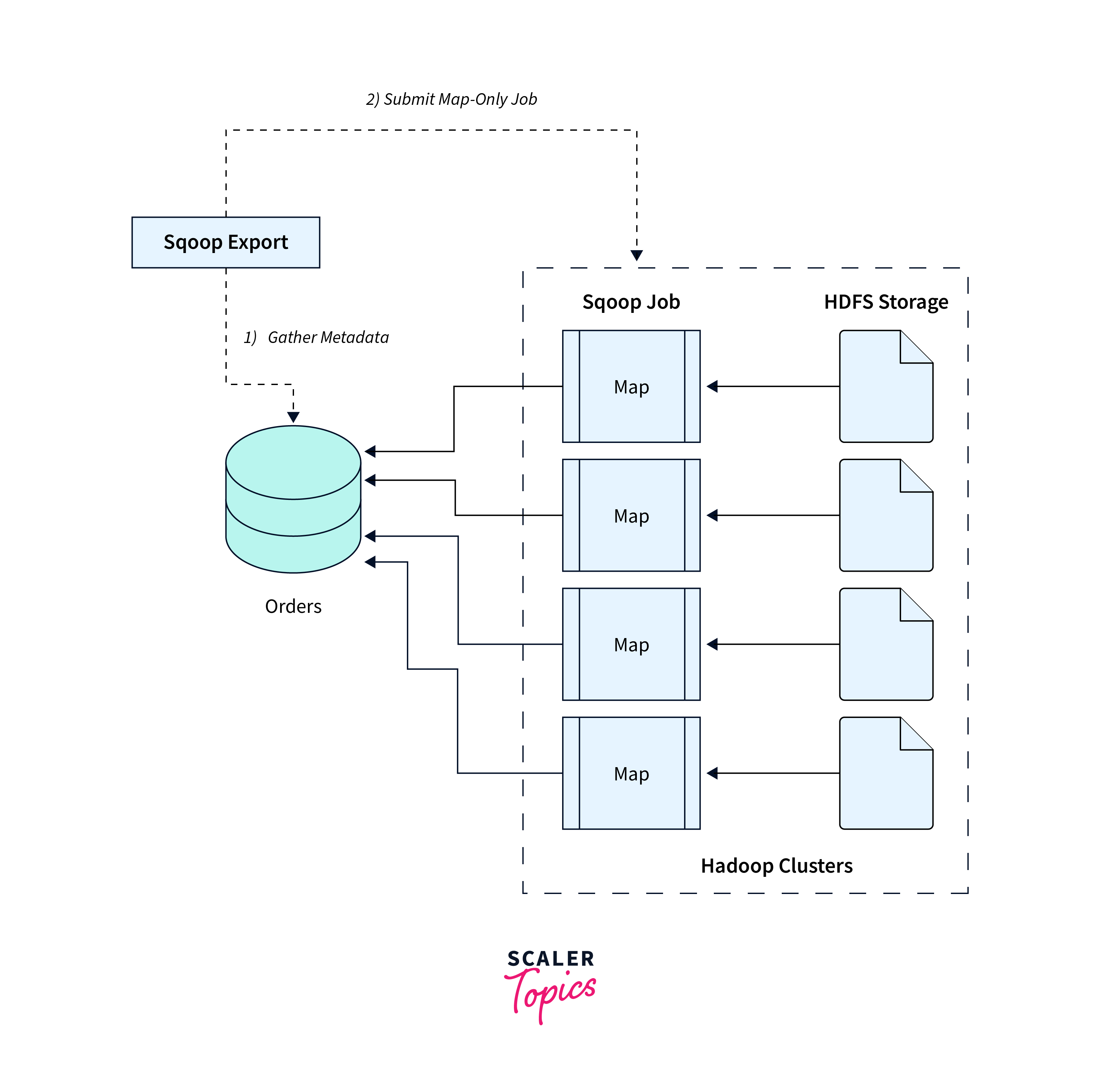
Syntax:
Options:
- --compress: Enables data compression during export.
- --update-mode: Update mode. It can be set to one of the following values:
- updateonly: Only updates existing records.
- allowinsert: Allows both updates and inserts.
- allowinsertfailupdate: Tries to insert new records and updates existing ones if a primary key constraint violation occurs.
- --staging-table: Name of a temporary staging table, where data is first loaded.
- --relaxed-isolation: Relaxes the transaction isolation level for improved performance.
- --boundary-query Enables parallel data export by partitioning the export based on user-defined boundaries.
- --compression-level: Specifies the compression level (1-9) for codecs that support different compression levels.
Compression levels represent the degree of data compression applied during the export process on starting sqoop. Higher compression levels result in smaller file sizes but may require more resources and time whereas, lower compression levels lead to larger file sizes but involve quicker compression and decompression operations.
Compression Codecs:
-
--compression-codec: Every data serialization algorithm can be specified by the compression codec to be used during export. These codecs with use cases are:
- org.apache.hadoop.io.compress.GzipCodec: Batch processing where time efficiency is not the top priority.
- org.apache.hadoop.io.compress.BZip2Codec: Storage capacity is limited.
- org.apache.hadoop.io.compress.SnappyCodec: Real-time data processing or quick data loading is required
- org.apache.hadoop.io.compress.LzopCodec: High-Speed Workflows
- org.apache.hadoop.io.compress.LzoCodec: Large-scale data analytics
- org.apache.hadoop.io.compress.Lz4Codec: Quick data loading applications.
- org.apache.hadoop.io.compress.DeflateCodec: Balance between compression and performance is required.
- org.apache.hadoop.io.compress.ZStandardCodec: Modern data processing pipelines.
Example:
To export data to an Oracle database with Snappy compression and a custom compression level of 6:
A compression level of 6 signifies a balance between storage efficiency and computational performance. It provides a moderate compression ratio while aiming to minimize the computational overhead during compression and decompression.
Conclusion
- Data serialization and compression are crucial for efficient data transfer and storage in the Hadoop ecosystem.
- Sqoop is compatible with various data sources such as MySQL, Oracle, SQL Server, and PostgreSQL.
- Sqoop supports various serialization formats: Text File, SequenceFile, Avro Data File, and Parquet File.
- Compression algorithms like Gzip, Bzip2, Snappy, LZO, LZ4, Deflate, and Zstandard are available in Sqoop.
- Compression codecs like Gzip, Snappy, and others can be specified using the --compression-codec option.