TensorFlow GPU Unleashing the Power of Parallel Computing
Overview
Parallel computing has become a game-changer in data processing and machine learning. With data's increasing volume and complexity, traditional computing methods need help to keep up with the demands. This is where parallel computing shines, leveraging the power of multiple processing units to tackle complex tasks simultaneously. One of the most popular frameworks for parallel computing is TensorFlow. When combined with powerful Graphics Processing Units (GPUs), it becomes a force to be reckoned with, and large neural networks can be computationally intensive. We can harness the power of GPUs and parallel computing to tackle this challenge.
Pre-requisites
Before you delve into GPU computing, there are certain prerequisites you need to consider to ensure a smooth and effective experience. Here are the key prerequisites for GPU computing:
-
Compatible Hardware: Your system's foremost requirement is a compatible Graphics Processing Unit (GPU). Not all GPUs support GPU computing, and the degree of support can vary. High-performance GPUs designed for parallel processing, such as NVIDIA GeForce, Tesla, or Quadro series GPUs, are commonly used for GPU computing.
-
GPU Drivers: You must install the appropriate GPU drivers on your system. These drivers allow your operating system to effectively communicate with and utilize the GPU. Make sure to keep your GPU drivers up to date, as newer drivers often provide performance improvements and bug fixes.
-
CUDA Toolkit: If you're using NVIDIA GPUs, the CUDA Toolkit is essential. CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model developed by NVIDIA. It provides a programming framework and libraries for utilizing GPU resources effectively. Install the appropriate version of the CUDA Toolkit for your GPU and operating system.
-
cuDNN Library: The cuDNN (CUDA Deep Neural Network) library is highly beneficial for deep learning tasks. It's an optimized GPU-accelerated library that provides primitives for deep neural networks, enhancing their performance. Ensure you download and install the cuDNN library that matches your CUDA version.
Introduction to TensorFlow GPU
TensorFlow an open-source machine learning framework developed by Google. It allows users to build and deploy machine learning models efficiently. While TensorFlow can be run on various types of hardware, including CPUs, one of its biggest advantages is its compatibility with GPUs.The integration of TensorFlow with GPUs offers significant benefits in terms of speed and performance. TensorFlow can accelerate training and inference processes by harnessing the parallel computing power of GPUs, reducing the time required to build and deploy models. One of the key advantages of TensorFlow GPU is its ability to handle large-scale datasets. As machine learning models are trained on massive amounts of data, processing the data efficiently becomes crucial. With their parallel processing capabilities, GPUs can significantly speed up the training process, allowing for faster iterations and experimentation. Moreover, TensorFlow GPU can handle complex neural networks with ease. TensorFlow GPU also enhances the inference process.
Inference refers to applying a trained model to make predictions on new data. With GPUs, the inference process can be performed in real-time, enabling faster decision-making and response times in applications such as image recognition, natural language processing, and autonomous vehicles. TensorFlow GPU provides a powerful platform for parallel computing in machine learning. By leveraging the capabilities of GPUs, TensorFlow accelerates the training and inference processes, enabling faster and more efficient model development. To leverage the power of TensorFlow GPU, it is essential to have a compatible hardware setup. This typically involves installing a compatible GPU in your system and configuring TensorFlow to utilize GPU resources efficiently. TensorFlow provides libraries and APIs that allow developers to integrate their models with GPUs seamlessly.
What is Parallel Computing
In traditional computing, tasks are executed sequentially, where each task is completed before the next one begins. This sequential approach can be time-consuming and limits the speed and efficiency of computations. On the other hand, parallel computing enables the simultaneous execution of multiple tasks, significantly reducing the overall processing time. In traditional computing, tasks are executed sequentially, where each task is completed before the next one begins. This sequential approach can be time-consuming and limits the speed and efficiency of computations. It achieves this by dividing a large problem into smaller sub-problems that can be solved concurrently. These sub-problems are then distributed across multiple processors or cores, allowing for parallel execution and faster results. There are different approaches to parallel computing, depending on the hardware and software utilized. One common method is shared memory parallelism, where multiple processors access a shared memory space and work on different parts of the problem simultaneously. This approach requires careful synchronization and coordination to avoid conflicts and ensure consistency.
The integration of parallel computing with TensorFlow GPU enables data scientists and developers to leverage the full potential of their hardware and achieve optimal performance in machine learning tasks. Whether training complex neural networks or performing real-time inference, parallel computing with TensorFlow GPU can significantly enhance the speed and efficiency of model development. Parallel computing is a powerful technique that enables the execution of multiple tasks simultaneously, reducing processing time and improving efficiency.
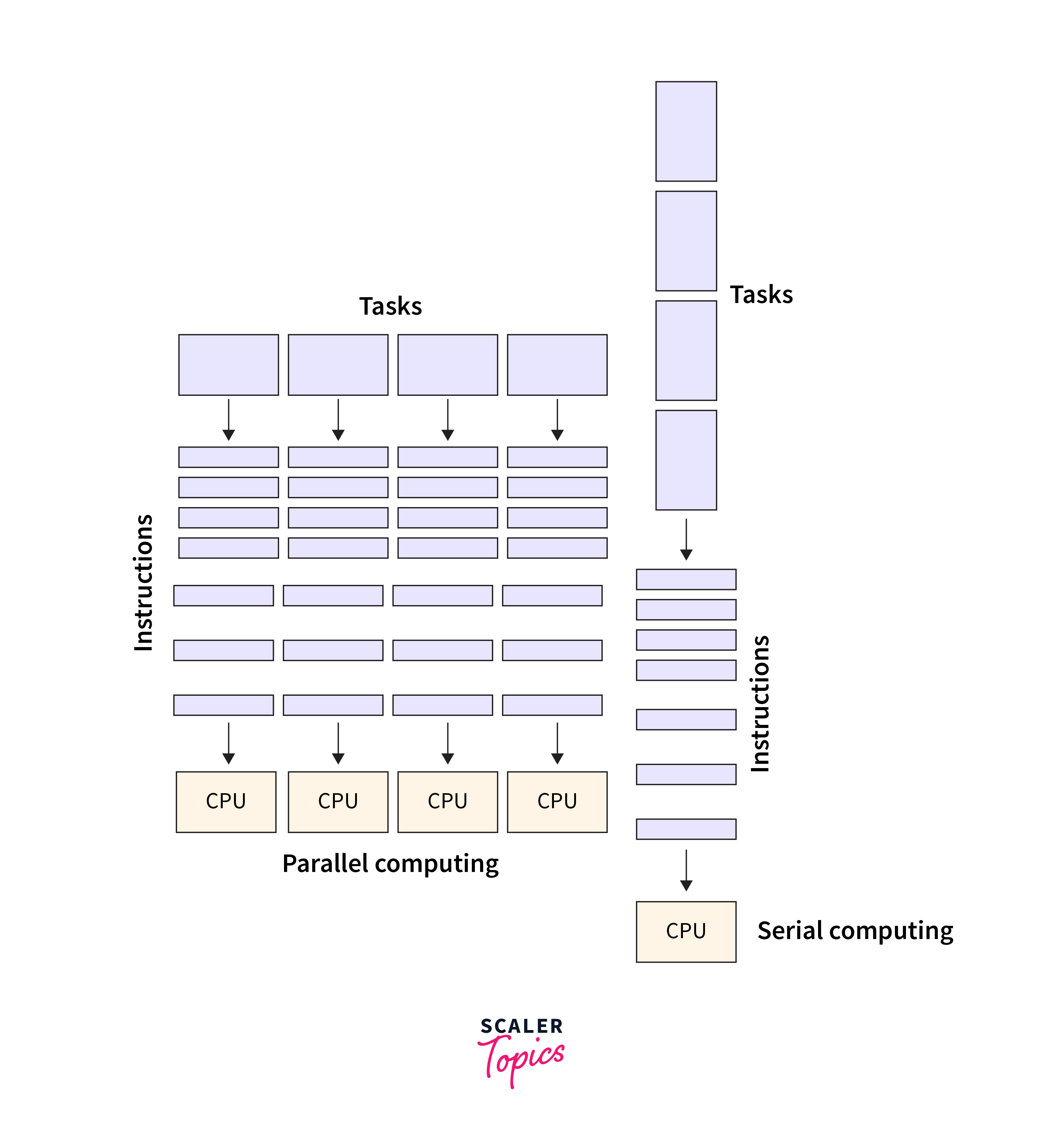
In addition to leveraging GPUs for parallel computing, another important facet is the utilization of multi-core CPUs. These CPUs incorporate multiple processing cores on a single chip, enabling parallel execution of tasks. This parallelism within a single CPU chip can also enhance computational performance by dividing workloads among different cores. This approach is particularly beneficial for tasks that may not require the intense parallelism that GPUs provide but can still benefit from simultaneous processing. So, in the realm of parallel computing, both GPUs and multi-core CPUs contribute significantly to optimizing performance across a wide range of applications, including machine learning with frameworks like TensorFlow GPU.
Installing the latest TensorFlow version with GPU support
Windows
-
Verify GPU Compatibility: Check the official TensorFlow website for a list of supported GPUs and requirements.https://www.tensorflow.org/install/pip
-
Install CUDA Toolkit and cuDNN: TensorFlow requires the CUDA Toolkit and cuDNN libraries. Download the appropriate versions for your GPU and Windows version from the NVIDIA website. Follow the installation instructions provided by NVIDIA.
-
Install Microsoft Visual Studio (Optional): If you encounter any issues during Installation, installing Microsoft Visual Studio with C++ components can be helpful.
-
Create a Virtual Environment (Optional): Creating a virtual environment to manage dependencies is recommended. Open a Command Prompt with administrator privileges and create a virtual environment using Venv
-
Activate the Virtual Environment: Navigate to the virtual environment's Scripts directory and activate the virtual environment:
- Install TensorFlow: Open a command prompt or PowerShell with administrator privileges. Activate your virtual environment (if created) and use pip to install TensorFlow with GPU support:
- Test Installation: Run a simple TensorFlow script to test if GPU support is working:
macOS
-
Verify GPU Compatibility: Check the TensorFlow website for GPU compatibility.
-
Install Homebrew (if not installed): Homebrew is a package manager for macOS. Follow the instructions on the Homebrew website to install it.https://mac.install.guide/homebrew/index.html
-
Install CUDA Toolkit and cuDNN: Use Homebrew to install the CUDA Toolkit and cuDNN:
- Create a Virtual Environment (Optional): Set up a virtual environment using venv:
- Activate the Virtual Environment: Activate the virtual environment:
- Install TensorFlow: Install TensorFlow with GPU support using pip:
- Test Installation: Run the script shown in the Windows section to verify GPU support.
Linux
- Step 1: Verify GPU Compatibility
Before proceeding, ensure that your GPU is compatible with TensorFlow. Check the official TensorFlow website for a list of supported GPUs and requirements.
- Step 2: Install NVIDIA Drivers
First, you must install the appropriate NVIDIA GPU drivers for your Linux distribution. You can usually install them through your distribution package manager.
For Ubuntu:
For CentOS:
- Step 3: Install CUDA Toolkit and cuDNN
TensorFlow requires the CUDA Toolkit and cuDNN libraries for GPU support. Download the appropriate GPU and Linux distribution versions from the NVIDIA website. Follow the installation instructions provided by NVIDIA.
- Step 4: Create a Virtual Environment (Optional)
Creating a virtual environment to manage dependencies and avoid conflicts with system-wide packages is recommended. You can use Venv or conda to create a virtual environment.
Using venv:
Using conda (if you have Anaconda installed):
- Step 5: Install TensorFlow
With your virtual environment activated, install TensorFlow with GPU support using pip:
- Step 6: Test Installation
Run a simple TensorFlow script to test if GPU support is working:
These instructions provide a general overview of the installation process on Windows and macOS. Please refer to the official TensorFlow documentation for any updates or additional steps required for your setup.'https://www.tensorflow.org/install/pip#macos'
Performance Benefits of using TensorFlow GPU
Utilizing TensorFlow GPU for machine learning tasks can provide significant performance benefits compared to using only the CPU. The power of parallel computing in GPUs allows for faster execution of complex computational tasks, resulting in accelerated training and inference times. Here are some key performance benefits of using TensorFlow GPU:
-
Accelerated Training Speed: The parallel processing capabilities of GPUs enable TensorFlow to train deep neural networks much faster than CPU-only implementations. The massive number of cores in a GPU allows for parallel execution of multiple calculations simultaneously, leading to significant speed improvements. With TensorFlow GPU, you can train large-scale models with millions of parameters in a fraction of the time it would take on a CPU.
-
Enhanced Model Performance: TensorFlow GPU allows for more complex and deeper neural network architectures to be trained due to its increased computational power. With more layers and nodes, deep learning models can learn intricate patterns and representations in the data, improving accuracy and performance. Using TensorFlow GPU, you can explore and experiment with more advanced neural network architectures, such as convolutional neural networks (CNNs) for image recognition or recurrent neural networks (RNNs) for natural language processing, with faster training times and better results.
-
Efficient Data Processing: GPUs excel at handling large amounts of data in parallel, making them ideal for processing extensive datasets used in machine learning applications. TensorFlow GPU allows seamless integration with data pipelines and libraries like NumPy, enabling efficient preprocessing, data augmentation, and batch processing. By leveraging the parallel processing capabilities of TensorFlow GPU, you can process and manipulate large datasets more quickly, reducing the overall training time and enhancing the efficiency of your machine learning workflows.
-
Real-Time Inference: Inference, or applying a trained model to new data, is often a critical aspect of machine learning applications. TensorFlow GPU allows for real-time inference by leveraging its parallel computing capabilities. With faster inference times, you can deploy machine learning models in production environments and deliver near-instant results to end-users, enhancing the usability and performance of your machine learning systems.
-
Scalability and Flexibility: TensorFlow GPU provides a scalable and flexible solution for machine learning tasks. As your computational requirements increase, you can easily scale your TensorFlow GPU setup by adding more GPUs to your system or utilizing cloud-based GPU instances. This scalability allows for the efficient distribution of computational loads and empowers data scientists and researchers to tackle more complex problems easily.
By harnessing the power of parallel computing through TensorFlow GPU, you can unlock the full potential of your hardware and significantly improve the performance of your machine-learning workflows. Whether training deep neural networks, processing large datasets, or deploying real-time inference systems, TensorFlow GPU offers a powerful solution for accelerating machine learning tasks and pushing the boundaries of what is possible in artificial intelligence.
Advanced Techniques for Optimizing TensorFlow GPU Performance
While TensorFlow GPU already provides significant performance benefits for machine learning tasks, there are advanced techniques that can further optimize its performance and maximize the utilization of the GPU hardware. These techniques can help you achieve even faster training and inference times and improve the efficiency and scalability of your machine-learning workflows. Here are some advanced techniques for optimizing TensorFlow GPU performance:
-
Batch Size Optimization: One of the key factors affecting GPU performance is the batch size used during training. Larger batch sizes can take advantage of the parallel processing capabilities of the GPU more efficiently, leading to faster training times. However, using excessively large batch sizes may exceed the memory capacity of the GPU, causing out-of-memory errors. Finding the optimal batch size that balances memory usage and computational efficiency is crucial. You can experiment with different batch sizes and monitor the GPU memory consumption to determine the sweet spot for your specific model and dataset.
-
Mixed Precision Training: Another technique for optimizing TensorFlow GPU performance is to use mixed precision training, which involves performing computations using lower precision (e.g., half-precision floating-point format) instead of the default single precision (e.g., float32). By using lower precision, you can reduce the memory bandwidth requirements and increase the computational throughput of the GPU. TensorFlow provides APIs and tools like the Automatic Mixed Precision (AMP) package, which facilitates mixed precision training and ensures numerical stability during training. Incorporating mixed precision training can result in significant speedup without sacrificing model accuracy.
-
Tensor Core Utilization: Tensor Cores are specialized hardware units available in certain GPU architectures, such as NVIDIA's Volta and Ampere architectures. These Tensor Cores can perform tensor operations much faster, especially for mixed precision computations. To leverage the full potential of Tensor Cores in TensorFlow GPU, you need to ensure that the operations in your model are compatible with Tensor Core acceleration. This involves using supported data types and alignment requirements for tensor operations. TensorFlow provides APIs to enable Tensor Core utilization, such as the tf.keras—mixed_precision API for mixed precision training with Tensor Cores.
-
Memory Management: Efficient memory management is crucial for optimizing TensorFlow GPU performance. You can reduce memory usage by minimizing unnecessary data transfers between the CPU and GPU, employing memory-efficient data structures, and using memory optimizations provided by TensorFlow, such as memory mapping and dynamic memory allocation. Additionally, you can use memory profiling tools to identify memory bottlenecks and optimize memory usage in your TensorFlow GPU workflow.
-
Distributed Training: If you can access multiple GPUs or GPU clusters, you can leverage distributed training techniques to accelerate your TensorFlow GPU performance further. TensorFlow's distributed training capabilities allow you to train your models on multiple GPUs simultaneously, reducing the training time significantly. You can use strategies like data parallelism, model parallelism, or a combination of both, depending on the characteristics of your model and the available resources.
By applying these advanced techniques, you can unlock the full potential of TensorFlow GPU and achieve even faster and more efficient machine learning workflows. Optimizing batch sizes, utilizing mixed precision training and Tensor Cores, optimizing memory management, and leveraging distributed training can significantly enhance the performance of your TensorFlow GPU setup, enabling you to push the boundaries of machine learning and artificial intelligence. Through continuous exploration and experimentation, you can ensure that you are making the most of your GPU hardware and staying at the forefront of cutting-edge machine-learning techniques.
Case Studies: How TensorFlow GPU Transformed Deep Learning Projects
With the rise of deep learning and the increasing importance of GPU acceleration in machine learning, TensorFlow GPU has become a powerful tool for transforming deep learning projects. The combination of TensorFlow's versatile framework and the parallel processing capabilities of GPUs has enabled researchers, developers, and data scientists to tackle complex tasks with unprecedented speed and efficiency.
-
Accelerated Training Time: TensorFlow GPU has significantly reduced the training time for deep learning models, allowing for faster iteration and experimentation. By leveraging the parallel processing capabilities of GPUs, researchers can train large-scale models on massive datasets in a fraction of the time compared to traditional CPU-based training. This has paved the way for rapid progress in various domains, from computer vision to natural language processing.
-
Larger and More Complex Models: Deep learning models often require increased complexity to achieve state-of-the-art performance. With TensorFlow GPU, researchers can train larger and more complex models that were previously infeasible due to computational limitations. This has opened up new possibilities for tackling challenging tasks such as image classification, object detection, and language translation. By utilizing the parallel processing power of GPUs, researchers can explore deeper architectures and incorporate more parameters, leading to improved accuracy and performance.
-
Real-Time Applications: TensorFlow GPU has enabled real-time deployment of deep learning models in various applications. Tasks such as real-time object detection, autonomous driving, and live language translation require efficient inference on the fly. By leveraging the parallel processing capabilities of GPUs, researchers can deploy deep learning models that can process data in real time, enabling responsive and interactive applications.
Conclusion
- TensorFlow GPU harnesses the parallel processing capabilities of powerful GPUs, drastically reducing training times for deep learning models.
- This efficiency accelerates model development, enabling researchers and data scientists to iterate and experiment faster, ultimately driving innovation across various domains.
- The integration of TensorFlow with GPUs empowers the training of larger, more complex neural network architectures. Researchers can explore intricate model designs, such as convolutional and recurrent neural networks, improving accuracy and performance across diverse tasks like image recognition, natural language processing, and more.
- TensorFlow GPU enables real-time inference, making it feasible to deploy machine learning models for immediate decision-making.
- This capability is crucial in applications like autonomous vehicles, real-time object detection, and live language translation, where rapid responses are essential.
- TensorFlow GPU democratizes access to high-performance computing for a broader community of researchers and developers. It levels the playing field by allowing individuals to tackle complex problems and explore cutting-edge techniques without the need for massive computational resources.